 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBine Trees: Enhancing Collective Operations by Optimizing Communication Locality
Aug 24, 2025Communication locality plays a key role in the performance of collective operations on large HPC systems, especially on oversubscribed networks where groups of nodes are fully connected internally but sparsely linked through global connections. We present Bine (binomial negabinary) trees, a family of collective algorithms that improve communication locality. Bine trees maintain the generality of binomial trees and butterflies while cutting global-link traffic by up to 33%. We implement eight Bine-based collectives and evaluate them on four large-scale supercomputers with Dragonfly, Dragonfly+, oversubscribed fat-tree, and torus topologies, achieving up to 5x speedups and consistent reductions in global-link traffic across different vector sizes and node counts.
Exploring GPU-to-GPU Communication: Insights into Supercomputer Interconnects
Aug 26, 2024



Multi-GPU nodes are increasingly common in the rapidly evolving landscape of exascale supercomputers. On these systems, GPUs on the same node are connected through dedicated networks, with bandwidths up to a few terabits per second. However, gauging performance expectations and maximizing system efficiency is challenging due to different technologies, design options, and software layers. This paper comprehensively characterizes three supercomputers - Alps, Leonardo, and LUMI - each with a unique architecture and design. We focus on performance evaluation of intra-node and inter-node interconnects on up to 4096 GPUs, using a mix of intra-node and inter-node benchmarks. By analyzing its limitations and opportunities, we aim to offer practical guidance to researchers, system architects, and software developers dealing with multi-GPU supercomputing. Our results show that there is untapped bandwidth, and there are still many opportunities for optimization, ranging from network to software optimization.
Swing: Short-cutting Rings for Higher Bandwidth Allreduce
Jan 17, 2024The allreduce collective operation accounts for a significant fraction of the runtime of workloads running on distributed systems. One factor determining its performance is the distance between communicating nodes, especially on networks like torus, where a higher distance implies multiple messages being forwarded on the same link, thus reducing the allreduce bandwidth. Torus networks are widely used on systems optimized for machine learning workloads (e.g., Google TPUs and Amazon Trainium devices), as well as on some of the Top500 supercomputers. To improve allreduce performance on torus networks we introduce Swing, a new algorithm that keeps a low distance between communicating nodes by swinging between torus directions. Our analysis and experimental evaluation show that Swing outperforms by up to 3x existing allreduce algorithms for vectors ranging from 32B to 128MiB, on different types of torus and torus-like topologies, regardless of their shape and size.
HammingMesh: A Network Topology for Large-Scale Deep Learning
Sep 03, 2022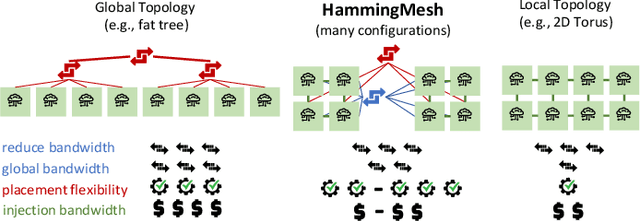
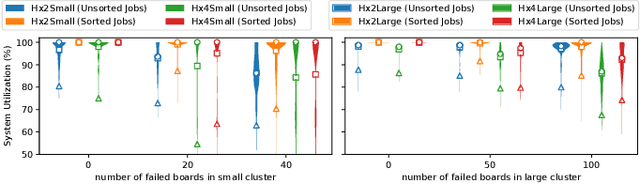
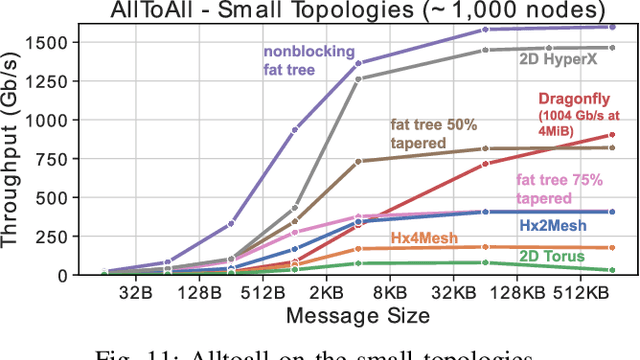
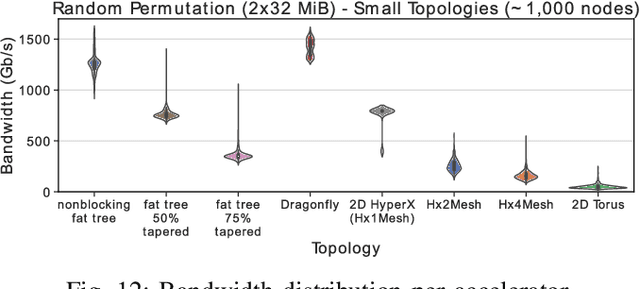
Numerous microarchitectural optimizations unlocked tremendous processing power for deep neural networks that in turn fueled the AI revolution. With the exhaustion of such optimizations, the growth of modern AI is now gated by the performance of training systems, especially their data movement. Instead of focusing on single accelerators, we investigate data-movement characteristics of large-scale training at full system scale. Based on our workload analysis, we design HammingMesh, a novel network topology that provides high bandwidth at low cost with high job scheduling flexibility. Specifically, HammingMesh can support full bandwidth and isolation to deep learning training jobs with two dimensions of parallelism. Furthermore, it also supports high global bandwidth for generic traffic. Thus, HammingMesh will power future large-scale deep learning systems with extreme bandwidth requirements.