 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Avoiding Linear Algebraic Kernel K-Means on GPUs
Jan 23, 2026Clustering is an important tool in data analysis, with K-means being popular for its simplicity and versatility. However, it cannot handle non-linearly separable clusters. Kernel K-means addresses this limitation but requires a large kernel matrix, making it computationally and memory intensive. Prior work has accelerated Kernel K-means by formulating it using sparse linear algebra primitives and implementing it on a single GPU. However, that approach cannot run on datasets with more than approximately 80,000 samples due to limited GPU memory. In this work, we address this issue by presenting a suite of distributed-memory parallel algorithms for large-scale Kernel K-means clustering on multi-GPU systems. Our approach maps the most computationally expensive components of Kernel K-means onto communication-efficient distributed linear algebra primitives uniquely tailored for Kernel K-means, enabling highly scalable implementations that efficiently cluster million-scale datasets. Central to our work is the design of partitioning schemes that enable communication-efficient composition of the linear algebra primitives that appear in Kernel K-means. Our 1.5D algorithm consistently achieves the highest performance, enabling Kernel K-means to scale to data one to two orders of magnitude larger than previously practical. On 256 GPUs, it achieves a geometric mean weak scaling efficiency of $79.7\%$ and a geometric mean strong scaling speedup of $4.2\times$. Compared to our 1D algorithm, the 1.5D approach achieves up to a $3.6\times$ speedup on 256 GPUs and reduces clustering time from over an hour to under two seconds relative to a single-GPU sliding window implementation. Our results show that distributed algorithms designed with application-specific linear algebraic formulations can achieve substantial performance improvement.
Dual Natural Gradient Descent for Scalable Training of Physics-Informed Neural Networks
May 27, 2025Natural-gradient methods markedly accelerate the training of Physics-Informed Neural Networks (PINNs), yet their Gauss--Newton update must be solved in the parameter space, incurring a prohibitive $O(n^3)$ time complexity, where $n$ is the number of network trainable weights. We show that exactly the same step can instead be formulated in a generally smaller residual space of size $m = \sum_{\gamma} N_{\gamma} d_{\gamma}$, where each residual class $\gamma$ (e.g. PDE interior, boundary, initial data) contributes $N_{\gamma}$ collocation points of output dimension $d_{\gamma}$. Building on this insight, we introduce \textit{Dual Natural Gradient Descent} (D-NGD). D-NGD computes the Gauss--Newton step in residual space, augments it with a geodesic-acceleration correction at negligible extra cost, and provides both a dense direct solver for modest $m$ and a Nystrom-preconditioned conjugate-gradient solver for larger $m$. Experimentally, D-NGD scales second-order PINN optimization to networks with up to 12.8 million parameters, delivers one- to three-order-of-magnitude lower final error $L^2$ than first-order methods (Adam, SGD) and quasi-Newton methods, and -- crucially -- enables natural-gradient training of PINNs at this scale on a single GPU.
Physics-constrained DeepONet for Surrogate CFD models: a curved backward-facing step case
Mar 14, 2025



The Physics-Constrained DeepONet (PC-DeepONet), an architecture that incorporates fundamental physics knowledge into the data-driven DeepONet model, is presented in this study. This methodology is exemplified through surrogate modeling of fluid dynamics over a curved backward-facing step, a benchmark problem in computational fluid dynamics. The model was trained on computational fluid dynamics data generated for a range of parameterized geometries. The PC-DeepONet was able to learn the mapping from the parameters describing the geometry to the velocity and pressure fields. While the DeepONet is solely data-driven, the PC-DeepONet imposes the divergence constraint from the continuity equation onto the network. The PC-DeepONet demonstrates higher accuracy than the data-driven baseline, especially when trained on sparse data. Both models attain convergence with a small dataset of 50 samples and require only 50 iterations for convergence, highlighting the efficiency of neural operators in learning the dynamics governed by partial differential equations.
Exploring GPU-to-GPU Communication: Insights into Supercomputer Interconnects
Aug 26, 2024



Multi-GPU nodes are increasingly common in the rapidly evolving landscape of exascale supercomputers. On these systems, GPUs on the same node are connected through dedicated networks, with bandwidths up to a few terabits per second. However, gauging performance expectations and maximizing system efficiency is challenging due to different technologies, design options, and software layers. This paper comprehensively characterizes three supercomputers - Alps, Leonardo, and LUMI - each with a unique architecture and design. We focus on performance evaluation of intra-node and inter-node interconnects on up to 4096 GPUs, using a mix of intra-node and inter-node benchmarks. By analyzing its limitations and opportunities, we aim to offer practical guidance to researchers, system architects, and software developers dealing with multi-GPU supercomputing. Our results show that there is untapped bandwidth, and there are still many opportunities for optimization, ranging from network to software optimization.
Towards a learning-based performance modeling for accelerating Deep Neural Networks
Dec 09, 2022Emerging applications such as Deep Learning are often data-driven, thus traditional approaches based on auto-tuners are not performance effective across the wide range of inputs used in practice. In the present paper, we start an investigation of predictive models based on machine learning techniques in order to optimize Convolution Neural Networks (CNNs). As a use-case, we focus on the ARM Compute Library which provides three different implementations of the convolution operator at different numeric precision. Starting from a collation of benchmarks, we build and validate models learned by Decision Tree and naive Bayesian classifier. Preliminary experiments on Midgard-based ARM Mali GPU show that our predictive model outperforms all the convolution operators manually selected by the library.
GPU-based parallelism for ASP-solving
Sep 04, 2019
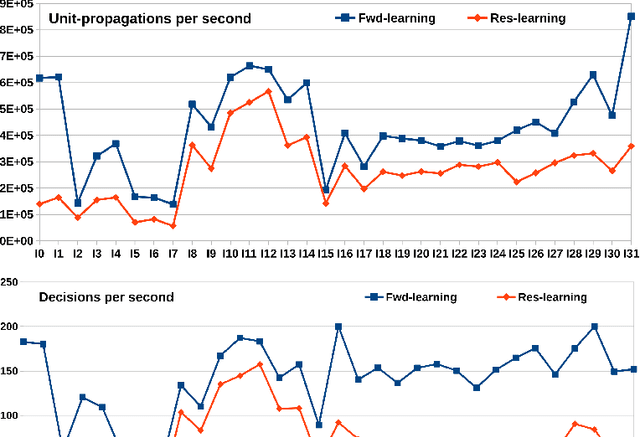
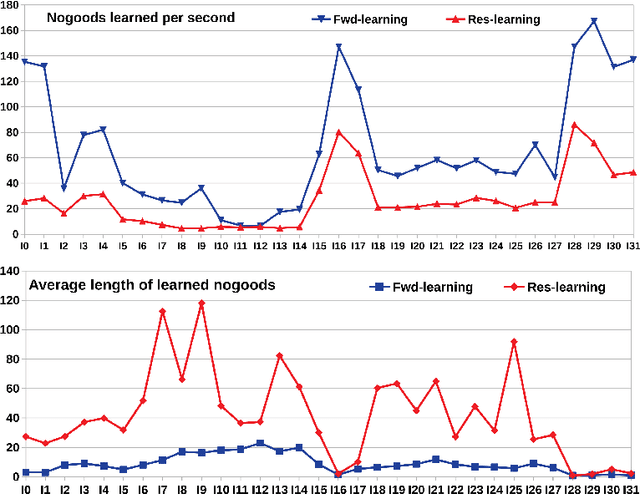
Answer Set Programming (ASP) has become, the paradigm of choice in the field of logic programming and non-monotonic reasoning. Thanks to the availability of efficient solvers, ASP has been successfully employed in a large number of application domains. The term GPU-computing indicates a recent programming paradigm aimed at enabling the use of modern parallel Graphical Processing Units (GPUs) for general purpose computing. In this paper we describe an approach to ASP-solving that exploits GPU parallelism. The design of a GPU-based solver poses various challenges due to the peculiarities of GPUs' software and hardware architectures and to the intrinsic nature of the satisfiability problem.
A Computational Model for Tensor Core Units
Aug 19, 2019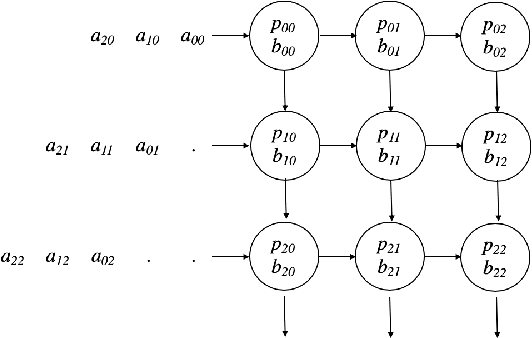
To respond to the need of efficient training and inference of deep neural networks, a pletora of domain-specific hardware architectures have been introduced, such as Google Tensor Processing Units and NVIDIA Tensor Cores. A common feature of these architectures is a hardware circuit for efficiently computing a dense matrix multiplication of a given small size. In order to broad the class of algorithms that exploit these systems, we propose a computational model, named TCU model, that captures the ability to natively multiply small matrices. We then use the TCU model for designing fast algorithms for linear algebra problems, including dense and sparse matrix multiplication, FFT, integer multiplication, and polynomial evaluation. We finally highlight a relation between the TCU model and the external memory model.