 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Model for Tensor Core Units
Paper and Code
Aug 19, 2019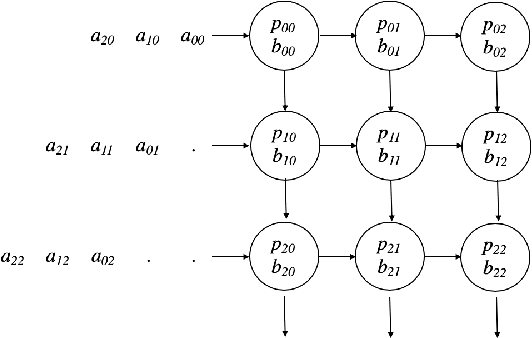
To respond to the need of efficient training and inference of deep neural networks, a pletora of domain-specific hardware architectures have been introduced, such as Google Tensor Processing Units and NVIDIA Tensor Cores. A common feature of these architectures is a hardware circuit for efficiently computing a dense matrix multiplication of a given small size. In order to broad the class of algorithms that exploit these systems, we propose a computational model, named TCU model, that captures the ability to natively multiply small matrices. We then use the TCU model for designing fast algorithms for linear algebra problems, including dense and sparse matrix multiplication, FFT, integer multiplication, and polynomial evaluation. We finally highlight a relation between the TCU model and the external memory model.