 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
HammingMesh: A Network Topology for Large-Scale Deep Learning
Sep 03, 2022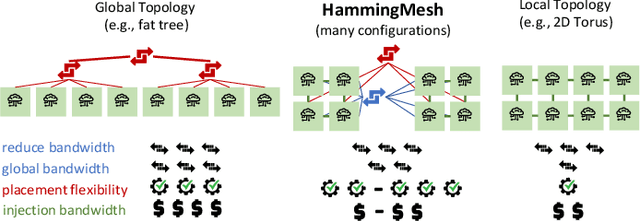
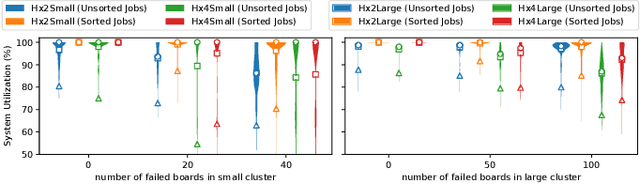
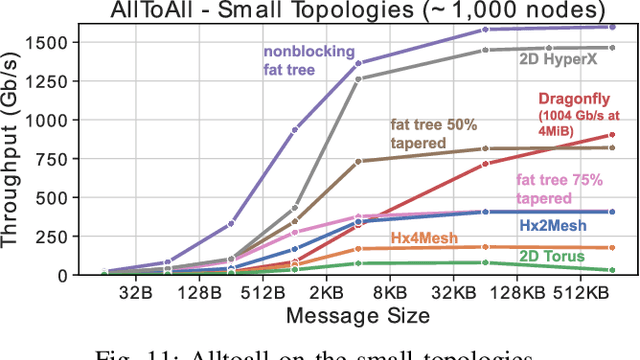
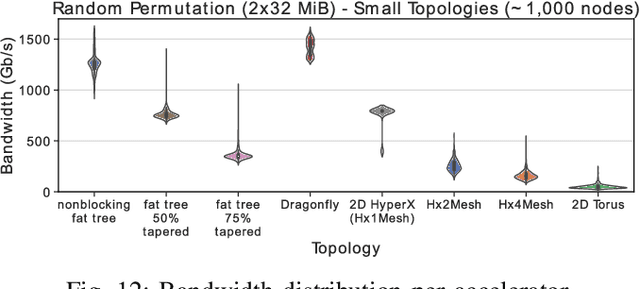
Numerous microarchitectural optimizations unlocked tremendous processing power for deep neural networks that in turn fueled the AI revolution. With the exhaustion of such optimizations, the growth of modern AI is now gated by the performance of training systems, especially their data movement. Instead of focusing on single accelerators, we investigate data-movement characteristics of large-scale training at full system scale. Based on our workload analysis, we design HammingMesh, a novel network topology that provides high bandwidth at low cost with high job scheduling flexibility. Specifically, HammingMesh can support full bandwidth and isolation to deep learning training jobs with two dimensions of parallelism. Furthermore, it also supports high global bandwidth for generic traffic. Thus, HammingMesh will power future large-scale deep learning systems with extreme bandwidth requirements.
Predicting post-operative right ventricular failure using video-based deep learning
Feb 28, 2021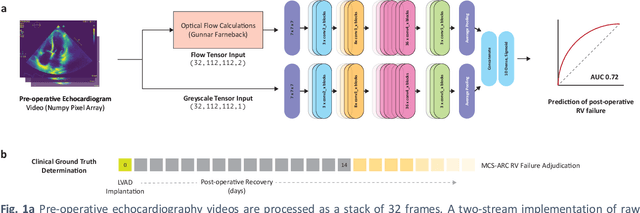
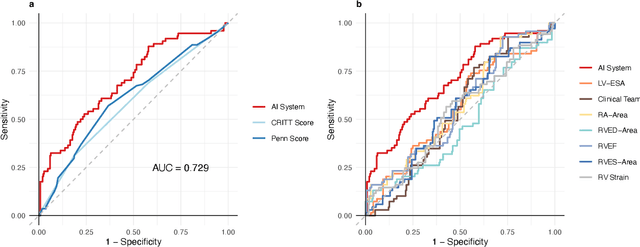
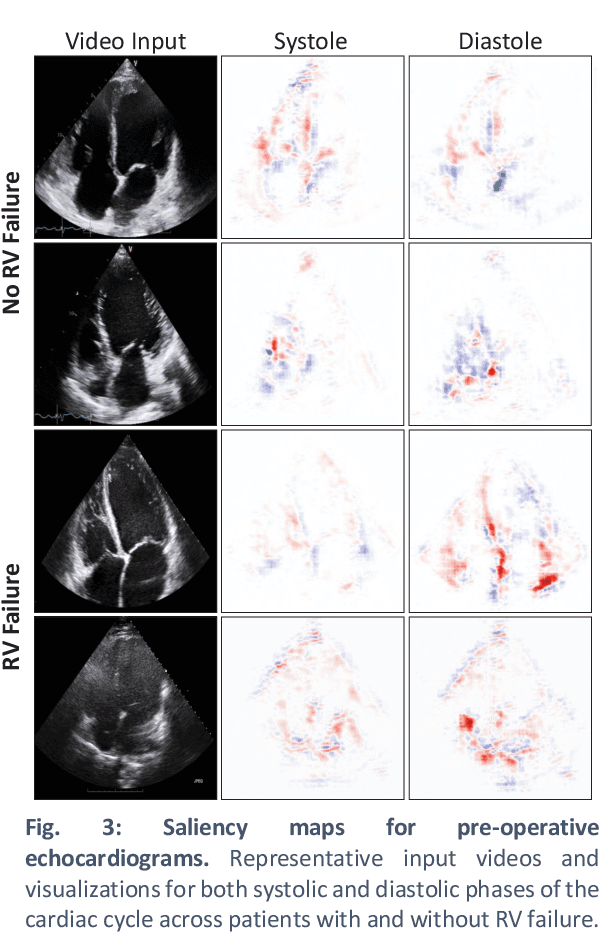
Non-invasive and cost effective in nature, the echocardiogram allows for a comprehensive assessment of the cardiac musculature and valves. Despite progressive improvements over the decades, the rich temporally resolved data in echocardiography videos remain underutilized. Human reads of echocardiograms reduce the complex patterns of cardiac wall motion, to a small list of measurements of heart function. Furthermore, all modern echocardiography artificial intelligence (AI) systems are similarly limited by design - automating measurements of the same reductionist metrics rather than utilizing the wealth of data embedded within each echo study. This underutilization is most evident in situations where clinical decision making is guided by subjective assessments of disease acuity, and tools that predict disease onset within clinically actionable timeframes are unavailable. Predicting the likelihood of developing post-operative right ventricular failure (RV failure) in the setting of mechanical circulatory support is one such clinical example. To address this, we developed a novel video AI system trained to predict post-operative right ventricular failure (RV failure), using the full spatiotemporal density of information from pre-operative echocardiography scans. We achieve an AUC of 0.729, specificity of 52% at 80% sensitivity and 46% sensitivity at 80% specificity. Furthermore, we show that our ML system significantly outperforms a team of human experts tasked with predicting RV failure on independent clinical evaluation. Finally, the methods we describe are generalizable to any cardiac clinical decision support application where treatment or patient selection is guided by qualitative echocardiography assessments.