 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisEval: A Benchmark for Data Visualization in the Era of Large Language Models
Jul 01, 2024Translating natural language to visualization (NL2VIS) has shown great promise for visual data analysis, but it remains a challenging task that requires multiple low-level implementations, such as natural language processing and visualization design. Recent advancements in pre-trained large language models (LLMs) are opening new avenues for generating visualizations from natural language. However, the lack of a comprehensive and reliable benchmark hinders our understanding of LLMs' capabilities in visualization generation. In this paper, we address this gap by proposing a new NL2VIS benchmark called VisEval. Firstly, we introduce a high-quality and large-scale dataset. This dataset includes 2,524 representative queries covering 146 databases, paired with accurately labeled ground truths. Secondly, we advocate for a comprehensive automated evaluation methodology covering multiple dimensions, including validity, legality, and readability. By systematically scanning for potential issues with a number of heterogeneous checkers, VisEval provides reliable and trustworthy evaluation outcomes. We run VisEval on a series of state-of-the-art LLMs. Our evaluation reveals prevalent challenges and delivers essential insights for future advancements.
Benchmarking Data Science Agents
Feb 27, 2024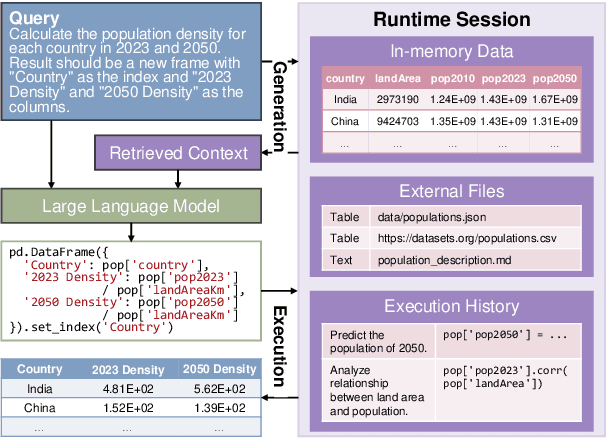
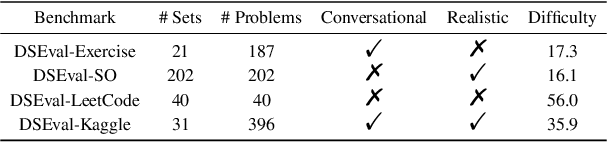


In the era of data-driven decision-making, the complexity of data analysis necessitates advanced expertise and tools of data science, presenting significant challenges even for specialists. Large Language Models (LLMs) have emerged as promising aids as data science agents, assisting humans in data analysis and processing. Yet their practical efficacy remains constrained by the varied demands of real-world applications and complicated analytical process. In this paper, we introduce DSEval -- a novel evaluation paradigm, as well as a series of innovative benchmarks tailored for assessing the performance of these agents throughout the entire data science lifecycle. Incorporating a novel bootstrapped annotation method, we streamline dataset preparation, improve the evaluation coverage, and expand benchmarking comprehensiveness. Our findings uncover prevalent obstacles and provide critical insights to inform future advancements in the field.
MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks
Apr 28, 2023



The field of machine learning (ML) has gained widespread adoption, leading to a significant demand for adapting ML to specific scenarios, which is yet expensive and non-trivial. The predominant approaches towards the automation of solving ML tasks (e.g., AutoML) are often time consuming and hard to understand for human developers. In contrast, though human engineers have the incredible ability to understand tasks and reason about solutions, their experience and knowledge are often sparse and difficult to utilize by quantitative approaches. In this paper, we aim to bridge the gap between machine intelligence and human knowledge by introducing a novel framework MLCopilot, which leverages the state-of-the-art LLMs to develop ML solutions for novel tasks. We showcase the possibility of extending the capability of LLMs to comprehend structured inputs and perform thorough reasoning for solving novel ML tasks. And we find that, after some dedicated design, the LLM can (i) observe from the existing experiences of ML tasks and (ii) reason effectively to deliver promising results for new tasks. The solution generated can be used directly to achieve high levels of competitiveness.
AutoTaskFormer: Searching Vision Transformers for Multi-task Learning
Apr 20, 2023Vision Transformers have shown great performance in single tasks such as classification and segmentation. However, real-world problems are not isolated, which calls for vision transformers that can perform multiple tasks concurrently. Existing multi-task vision transformers are handcrafted and heavily rely on human expertise. In this work, we propose a novel one-shot neural architecture search framework, dubbed AutoTaskFormer (Automated Multi-Task Vision TransFormer), to automate this process. AutoTaskFormer not only identifies the weights to share across multiple tasks automatically, but also provides thousands of well-trained vision transformers with a wide range of parameters (e.g., number of heads and network depth) for deployment under various resource constraints. Experiments on both small-scale (2-task Cityscapes and 3-task NYUv2) and large-scale (16-task Taskonomy) datasets show that AutoTaskFormer outperforms state-of-the-art handcrafted vision transformers in multi-task learning. The entire code and models will be open-sourced.
Reinforcement Learning with Automated Auxiliary Loss Search
Oct 12, 2022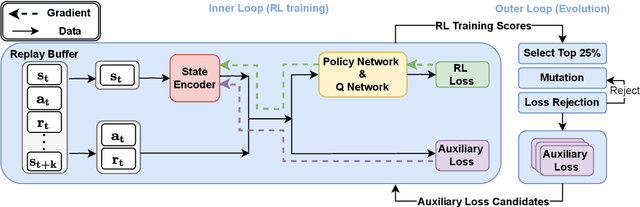

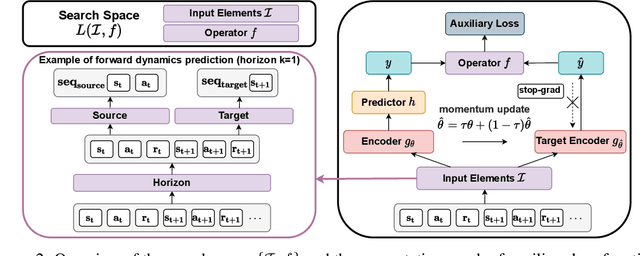

A good state representation is crucial to solving complicated reinforcement learning (RL) challenges. Many recent works focus on designing auxiliary losses for learning informative representations. Unfortunately, these handcrafted objectives rely heavily on expert knowledge and may be sub-optimal. In this paper, we propose a principled and universal method for learning better representations with auxiliary loss functions, named Automated Auxiliary Loss Search (A2LS), which automatically searches for top-performing auxiliary loss functions for RL. Specifically, based on the collected trajectory data, we define a general auxiliary loss space of size $7.5 \times 10^{20}$ and explore the space with an efficient evolutionary search strategy. Empirical results show that the discovered auxiliary loss (namely, A2-winner) significantly improves the performance on both high-dimensional (image) and low-dimensional (vector) unseen tasks with much higher efficiency, showing promising generalization ability to different settings and even different benchmark domains. We conduct a statistical analysis to reveal the relations between patterns of auxiliary losses and RL performance.
Privacy-preserving Online AutoML for Domain-Specific Face Detection
Mar 16, 2022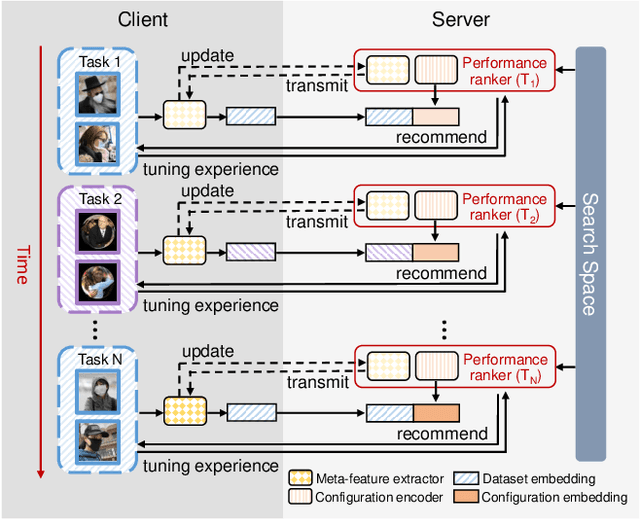
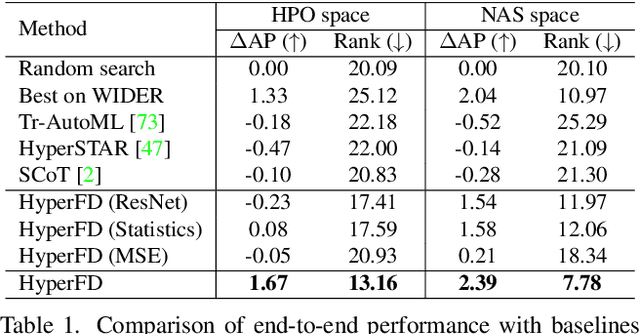
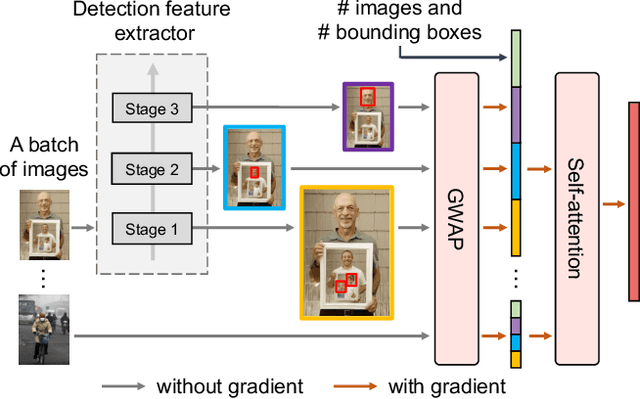
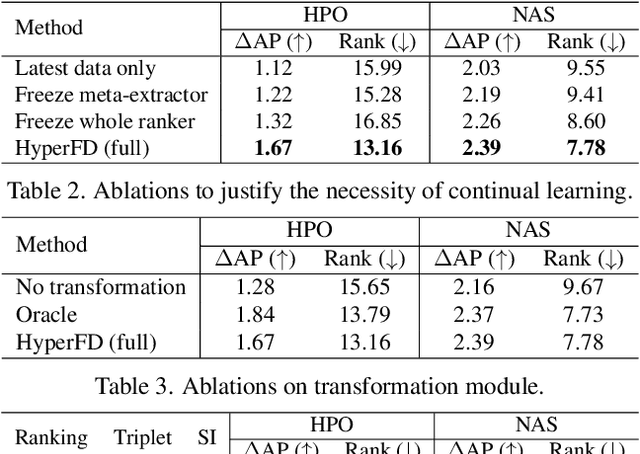
Despite the impressive progress of general face detection, the tuning of hyper-parameters and architectures is still critical for the performance of a domain-specific face detector. Though existing AutoML works can speedup such process, they either require tuning from scratch for a new scenario or do not consider data privacy. To scale up, we derive a new AutoML setting from a platform perspective. In such setting, new datasets sequentially arrive at the platform, where an architecture and hyper-parameter configuration is recommended to train the optimal face detector for each dataset. This, however, brings two major challenges: (1) how to predict the best configuration for any given dataset without touching their raw images due to the privacy concern? and (2) how to continuously improve the AutoML algorithm from previous tasks and offer a better warm-up for future ones? We introduce "HyperFD", a new privacy-preserving online AutoML framework for face detection. At its core part, a novel meta-feature representation of a dataset as well as its learning paradigm is proposed. Thanks to HyperFD, each local task (client) is able to effectively leverage the learning "experience" of previous tasks without uploading raw images to the platform; meanwhile, the meta-feature extractor is continuously learned to better trade off the bias and variance. Extensive experiments demonstrate the effectiveness and efficiency of our design.
Full-Cycle Energy Consumption Benchmark for Low-Carbon Computer Vision
Aug 30, 2021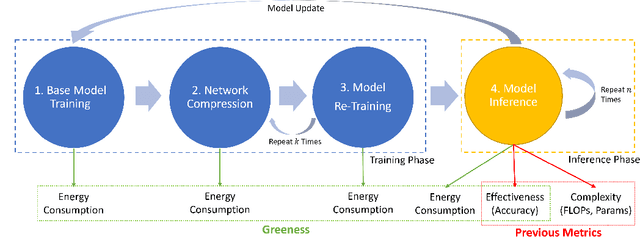
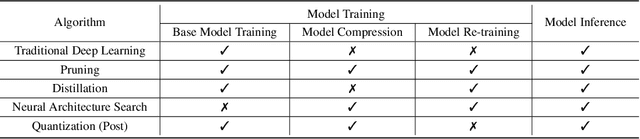

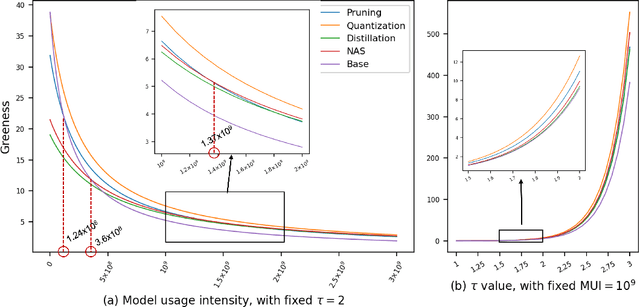
The energy consumption of deep learning models is increasing at a breathtaking rate, which raises concerns due to potential negative effects on carbon neutrality in the context of global warming and climate change. With the progress of efficient deep learning techniques, e.g., model compression, researchers can obtain efficient models with fewer parameters and smaller latency. However, most of the existing efficient deep learning methods do not explicitly consider energy consumption as a key performance indicator. Furthermore, existing methods mostly focus on the inference costs of the resulting efficient models, but neglect the notable energy consumption throughout the entire life cycle of the algorithm. In this paper, we present the first large-scale energy consumption benchmark for efficient computer vision models, where a new metric is proposed to explicitly evaluate the full-cycle energy consumption under different model usage intensity. The benchmark can provide insights for low carbon emission when selecting efficient deep learning algorithms in different model usage scenarios.
AceNAS: Learning to Rank Ace Neural Architectures with Weak Supervision of Weight Sharing
Aug 06, 2021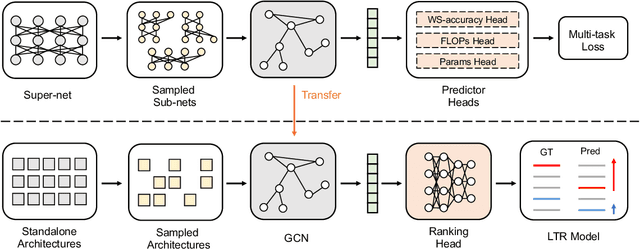
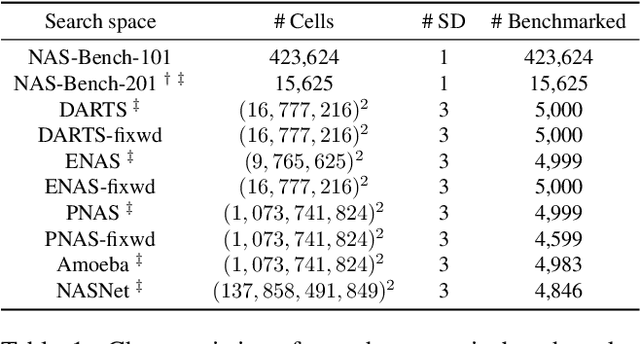
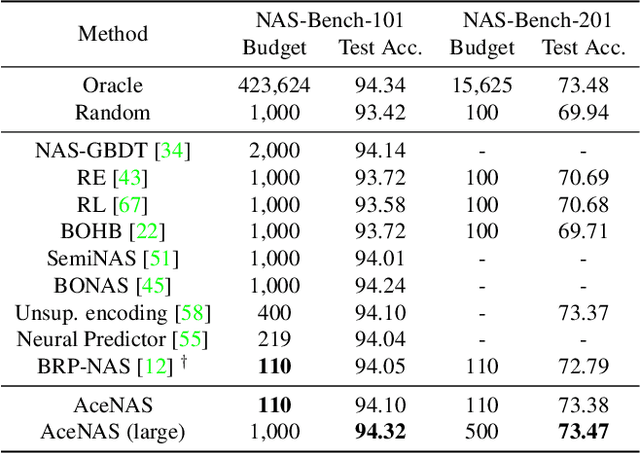
Architecture performance predictors have been widely used in neural architecture search (NAS). Although they are shown to be simple and effective, the optimization objectives in previous arts (e.g., precise accuracy estimation or perfect ranking of all architectures in the space) did not capture the ranking nature of NAS. In addition, a large number of ground-truth architecture-accuracy pairs are usually required to build a reliable predictor, making the process too computationally expensive. To overcome these, in this paper, we look at NAS from a novel point of view and introduce Learning to Rank (LTR) methods to select the best (ace) architectures from a space. Specifically, we propose to use Normalized Discounted Cumulative Gain (NDCG) as the target metric and LambdaRank as the training algorithm. We also propose to leverage weak supervision from weight sharing by pretraining architecture representation on weak labels obtained from the super-net and then finetuning the ranking model using a small number of architectures trained from scratch. Extensive experiments on NAS benchmarks and large-scale search spaces demonstrate that our approach outperforms SOTA with a significantly reduced search cost.
How Does Supernet Help in Neural Architecture Search?
Oct 16, 2020


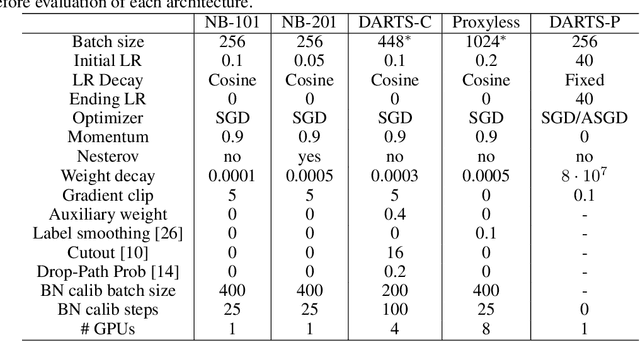
With the success of Neural Architecture Search (NAS), weight sharing, as an approach to speed up architecture performance estimation has received wide attention. Instead of training each architecture separately, weight sharing builds a supernet that assembles all the architectures as its submodels. However, there has been debate over whether the NAS process actually benefits from weight sharing, due to the gap between supernet optimization and the objective of NAS. To further understand the effect of weight sharing on NAS, we conduct a comprehensive analysis on five search spaces, including NAS-Bench-101, NAS-Bench-201, DARTS-CIFAR10, DARTS-PTB, and ProxylessNAS. Moreover, we take a step forward to explore the pruning based NAS algorithms. Some of our key findings are summarized as: (i) A well-trained supernet is not necessarily a good architecture-ranking model. (ii) Supernet is good at finding relatively good (top-10%) architectures but struggles to find the best ones (top-1% or less). (iii) The effectiveness of supernet largely depends on the design of search space itself. (iv) Comparing to selecting the best architectures, supernet is more confident in pruning the worst ones. (v) It is easier to find better architectures from an effectively pruned search space with supernet training. We expect the observations and insights obtained in this work would inspire and help better NAS algorithm design.
Deeper Insights into Weight Sharing in Neural Architecture Search
Jan 06, 2020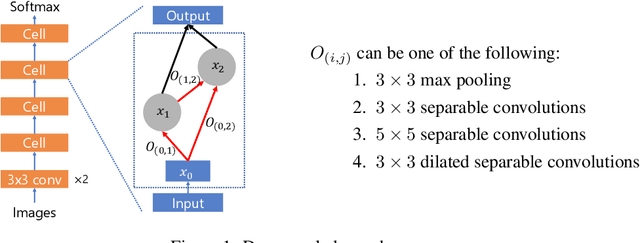
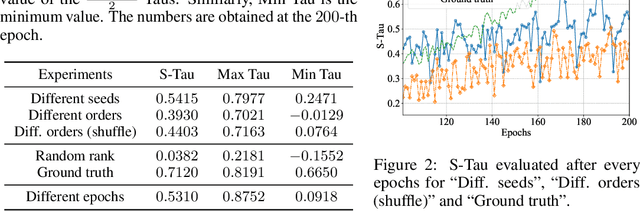
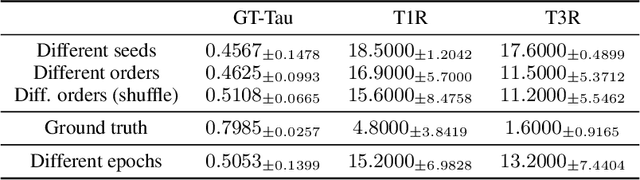
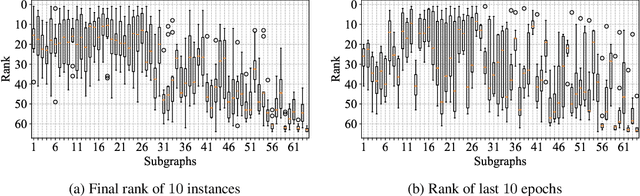
With the success of deep neural networks, Neural Architecture Search (NAS) as a way of automatic model design has attracted wide attention. As training every child model from scratch is very time-consuming, recent works leverage weight-sharing to speed up the model evaluation procedure. These approaches greatly reduce computation by maintaining a single copy of weights on the super-net and share the weights among every child model. However, weight-sharing has no theoretical guarantee and its impact has not been well studied before. In this paper, we conduct comprehensive experiments to reveal the impact of weight-sharing: (1) The best-performing models from different runs or even from consecutive epochs within the same run have significant variance; (2) Even with high variance, we can extract valuable information from training the super-net with shared weights; (3) The interference between child models is a main factor that induces high variance; (4) Properly reducing the degree of weight sharing could effectively reduce variance and improve performance.