 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Supernet Help in Neural Architecture Search?
Paper and Code
Oct 16, 2020


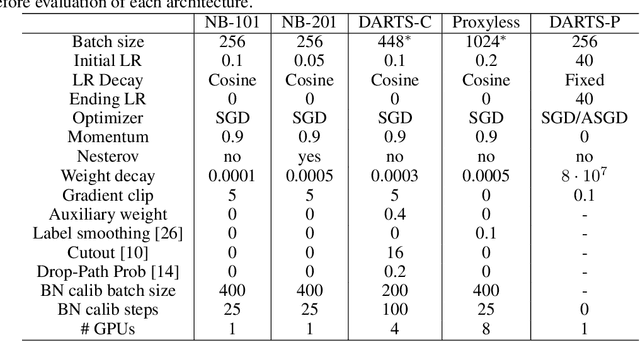
With the success of Neural Architecture Search (NAS), weight sharing, as an approach to speed up architecture performance estimation has received wide attention. Instead of training each architecture separately, weight sharing builds a supernet that assembles all the architectures as its submodels. However, there has been debate over whether the NAS process actually benefits from weight sharing, due to the gap between supernet optimization and the objective of NAS. To further understand the effect of weight sharing on NAS, we conduct a comprehensive analysis on five search spaces, including NAS-Bench-101, NAS-Bench-201, DARTS-CIFAR10, DARTS-PTB, and ProxylessNAS. Moreover, we take a step forward to explore the pruning based NAS algorithms. Some of our key findings are summarized as: (i) A well-trained supernet is not necessarily a good architecture-ranking model. (ii) Supernet is good at finding relatively good (top-10%) architectures but struggles to find the best ones (top-1% or less). (iii) The effectiveness of supernet largely depends on the design of search space itself. (iv) Comparing to selecting the best architectures, supernet is more confident in pruning the worst ones. (v) It is easier to find better architectures from an effectively pruned search space with supernet training. We expect the observations and insights obtained in this work would inspire and help better NAS algorithm design.