 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 The First Challenge on Weather Removal in Videos
Apr 14, 2026This paper presents a review of the LoViF 2026 Challenge on Weather Removal in Videos. The challenge encourages the development of methods for restoring clean videos from inputs degraded by adverse weather conditions such as rain and snow, with an emphasis on achieving visually plausible and temporally consistent results while preserving scene structure and motion dynamics. To support this task, we introduce a new short-form WRV dataset tailored for video weather removal. It consists of 18 videos 1,216 synthesized frames paired with 1,216 real-world ground-truth frames at a resolution of 832 x 480, and is split into training, validation, and test sets with a ratio of 1:1:1. The goal of this challenge is to advance robust and realistic video restoration under real-world weather conditions, with evaluation protocols that jointly consider fidelity and perceptual quality. The challenge attracted 37 participants and received 5 valid final submissions with corresponding fact sheets, contributing to progress in weather removal for videos. The project is publicly available at https://www.codabench.org/competitions/13462/.
Convolutional Gaussian Embeddings for Personalized Recommendation with Uncertainty
Jun 19, 2020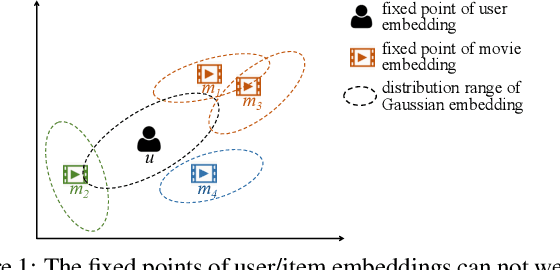

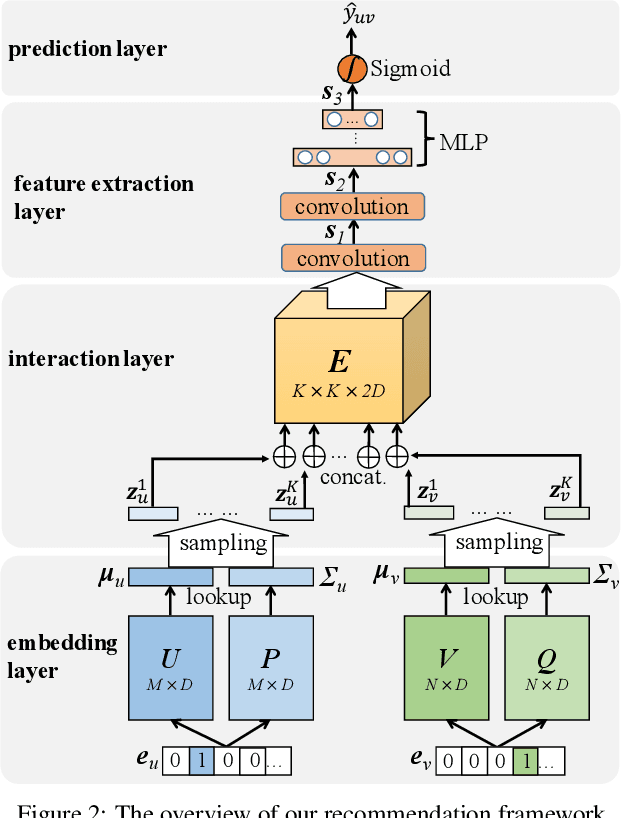
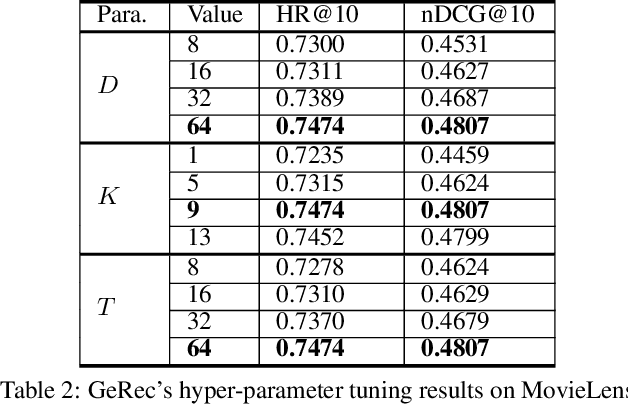
Most of existing embedding based recommendation models use embeddings (vectors) corresponding to a single fixed point in low-dimensional space, to represent users and items. Such embeddings fail to precisely represent the users/items with uncertainty often observed in recommender systems. Addressing this problem, we propose a unified deep recommendation framework employing Gaussian embeddings, which are proven adaptive to uncertain preferences exhibited by some users, resulting in better user representations and recommendation performance. Furthermore, our framework adopts Monte-Carlo sampling and convolutional neural networks to compute the correlation between the objective user and the candidate item, based on which precise recommendations are achieved. Our extensive experiments on two benchmark datasets not only justify that our proposed Gaussian embeddings capture the uncertainty of users very well, but also demonstrate its superior performance over the state-of-the-art recommendation models.
Deeper Insights into Weight Sharing in Neural Architecture Search
Jan 06, 2020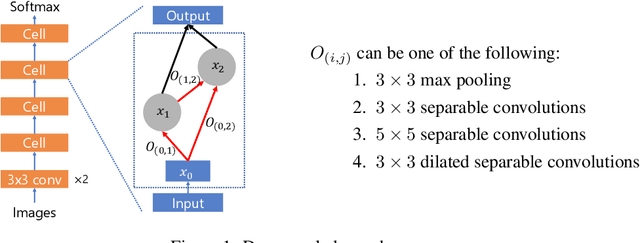
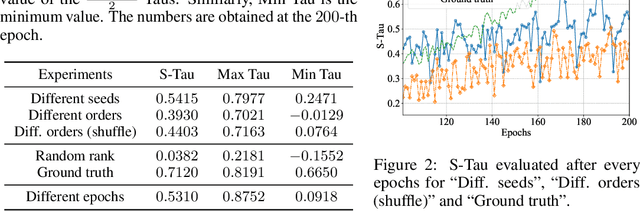
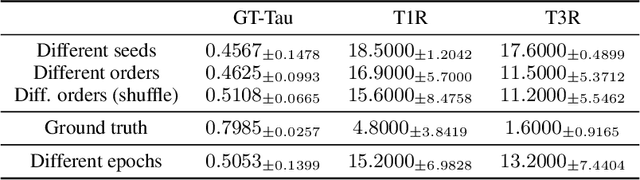
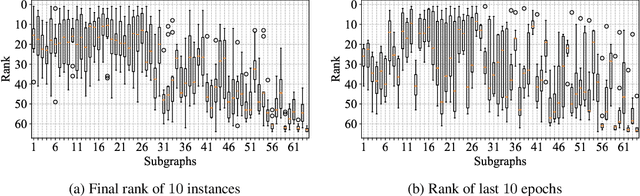
With the success of deep neural networks, Neural Architecture Search (NAS) as a way of automatic model design has attracted wide attention. As training every child model from scratch is very time-consuming, recent works leverage weight-sharing to speed up the model evaluation procedure. These approaches greatly reduce computation by maintaining a single copy of weights on the super-net and share the weights among every child model. However, weight-sharing has no theoretical guarantee and its impact has not been well studied before. In this paper, we conduct comprehensive experiments to reveal the impact of weight-sharing: (1) The best-performing models from different runs or even from consecutive epochs within the same run have significant variance; (2) Even with high variance, we can extract valuable information from training the super-net with shared weights; (3) The interference between child models is a main factor that induces high variance; (4) Properly reducing the degree of weight sharing could effectively reduce variance and improve performance.