 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3D-Stereo: A Multiple-Medium and Multiple-Degradation Dataset for Stereo Image Restoration
Apr 14, 2026Image restoration under adverse conditions, such as underwater, haze or fog, and low-light environments, remains a highly challenging problem due to complex physical degradations and severe information loss. Existing datasets are predominantly limited to a single degradation type or heavily rely on synthetic data without stereo consistency, inherently restricting their applicability in real-world scenarios. To address this, we introduce M3D-Stereo, a stereo dataset with 7904 high-resolution image pairs for image restoration research acquired in multiple media with multiple controlled degradation levels. It encompasses four degradation scenarios: underwater scatter, haze/fog, underwater low-light, and haze low-light. Each scenario forms a subset, and is divided into six levels of progressive degradation, allowing fine-grained evaluations of restoration methods with increasing severity of degradation. Collected via a laboratory setup, the dataset provides aligned stereo image pairs along with their pixel-wise consistent clear ground truths. Two restoration tasks, single-level and mixed-level degradation, were performed to verify its validity. M3D-Stereo establishes a better controlled and more realistic benchmark to evaluate image restoration and stereo matching methods in complex degradation environments. It is made public under LGPLv3 license.
Good Reasoning Makes Good Demonstrations: Implicit Reasoning Quality Supervision via In-Context Reinforcement Learning
Mar 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) improves reasoning in large language models but treats all correct solutions equally, potentially reinforcing flawed traces that get correct answers by chance. We observe that better reasoning are better teachers: high-quality solutions serve as more effective demonstrations than low-quality ones. We term this teaching ability Demonstration Utility, and show that the policy model's own in-context learning ability provides an efficient way to measure it, yielding a quality signal termed Evidence Gain. To employ this signal during training, we introduce In-Context RLVR. By Bayesian analysis, we show that this objective implicitly reweights rewards by Evidence Gain, assigning higher weights to high-quality traces and lower weights to low-quality ones, without requiring costly computation or external evaluators. Experiments on mathematical benchmarks show improvements in both accuracy and reasoning quality over standard RLVR.
Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents
Feb 13, 2026Large language models (LLMs) are increasingly deployed as autonomous agents for multi-turn decision-making tasks. However, current agents typically rely on fixed cognitive patterns: non-thinking models generate immediate responses, while thinking models engage in deep reasoning uniformly. This rigidity is inefficient for long-horizon tasks, where cognitive demands vary significantly from step to step, with some requiring strategic planning and others only routine execution. In this paper, we introduce CogRouter, a framework that trains agents to dynamically adapt cognitive depth at each step. Grounded in ACT-R theory, we design four hierarchical cognitive levels ranging from instinctive responses to strategic planning. Our two-stage training approach includes Cognition-aware Supervised Fine-tuning (CoSFT) to instill stable level-specific patterns, and Cognition-aware Policy Optimization (CoPO) for step-level credit assignment via confidence-aware advantage reweighting. The key insight is that appropriate cognitive depth should maximize the confidence of the resulting action. Experiments on ALFWorld and ScienceWorld demonstrate that CogRouter achieves state-of-the-art performance with superior efficiency. With Qwen2.5-7B, it reaches an 82.3% success rate, outperforming GPT-4o (+40.3%), OpenAI-o3 (+18.3%), and GRPO (+14.0%), while using 62% fewer tokens.
Outcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Jan 12, 2026Group Relative Policy Optimization (GRPO) has emerged as a promising critic-free reinforcement learning paradigm for reasoning tasks. However, standard GRPO employs a coarse-grained credit assignment mechanism that propagates group-level rewards uniformly to to every token in a sequence, neglecting the varying contribution of individual reasoning steps. We address this limitation by introducing Outcome-grounded Advantage Reshaping (OAR), a fine-grained credit assignment mechanism that redistributes advantages based on how much each token influences the model's final answer. We instantiate OAR via two complementary strategies: (1) OAR-P, which estimates outcome sensitivity through counterfactual token perturbations, serving as a high-fidelity attribution signal; (2) OAR-G, which uses an input-gradient sensitivity proxy to approximate the influence signal with a single backward pass. These importance signals are integrated with a conservative Bi-Level advantage reshaping scheme that suppresses low-impact tokens and boosts pivotal ones while preserving the overall advantage mass. Empirical results on extensive mathematical reasoning benchmarks demonstrate that while OAR-P sets the performance upper bound, OAR-G achieves comparable gains with negligible computational overhead, both significantly outperforming a strong GRPO baseline, pushing the boundaries of critic-free LLM reasoning.
Confidence Estimation for LLMs in Multi-turn Interactions
Jan 05, 2026While confidence estimation is a promising direction for mitigating hallucinations in Large Language Models (LLMs), current research dominantly focuses on single-turn settings. The dynamics of model confidence in multi-turn conversations, where context accumulates and ambiguity is progressively resolved, remain largely unexplored. Reliable confidence estimation in multi-turn settings is critical for many downstream applications, such as autonomous agents and human-in-the-loop systems. This work presents the first systematic study of confidence estimation in multi-turn interactions, establishing a formal evaluation framework grounded in two key desiderata: per-turn calibration and monotonicity of confidence as more information becomes available. To facilitate this, we introduce novel metrics, including a length-normalized Expected Calibration Error (InfoECE), and a new "Hinter-Guesser" paradigm for generating controlled evaluation datasets. Our experiments reveal that widely-used confidence techniques struggle with calibration and monotonicity in multi-turn dialogues. We propose P(Sufficient), a logit-based probe that achieves comparatively better performance, although the task remains far from solved. Our work provides a foundational methodology for developing more reliable and trustworthy conversational agents.
ComLQ: Benchmarking Complex Logical Queries in Information Retrieval
Nov 15, 2025

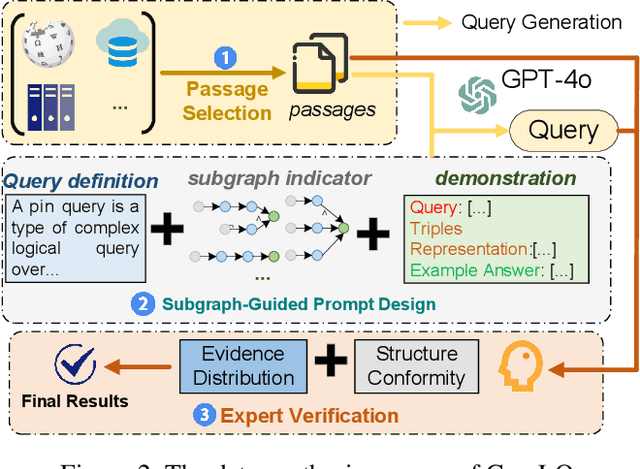

Information retrieval (IR) systems play a critical role in navigating information overload across various applications. Existing IR benchmarks primarily focus on simple queries that are semantically analogous to single- and multi-hop relations, overlooking \emph{complex logical queries} involving first-order logic operations such as conjunction ($\land$), disjunction ($\lor$), and negation ($\lnot$). Thus, these benchmarks can not be used to sufficiently evaluate the performance of IR models on complex queries in real-world scenarios. To address this problem, we propose a novel method leveraging large language models (LLMs) to construct a new IR dataset \textbf{ComLQ} for \textbf{Com}plex \textbf{L}ogical \textbf{Q}ueries, which comprises 2,909 queries and 11,251 candidate passages. A key challenge in constructing the dataset lies in capturing the underlying logical structures within unstructured text. Therefore, by designing the subgraph-guided prompt with the subgraph indicator, an LLM (such as GPT-4o) is guided to generate queries with specific logical structures based on selected passages. All query-passage pairs in ComLQ are ensured \emph{structure conformity} and \emph{evidence distribution} through expert annotation. To better evaluate whether retrievers can handle queries with negation, we further propose a new evaluation metric, \textbf{Log-Scaled Negation Consistency} (\textbf{LSNC@$K$}). As a supplement to standard relevance-based metrics (such as nDCG and mAP), LSNC@$K$ measures whether top-$K$ retrieved passages violate negation conditions in queries. Our experimental results under zero-shot settings demonstrate existing retrieval models' limited performance on complex logical queries, especially on queries with negation, exposing their inferior capabilities of modeling exclusion.
Accelerated Evolving Set Processes for Local PageRank Computation
Oct 09, 2025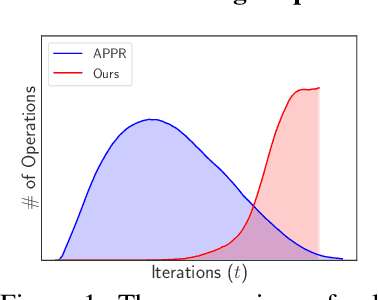

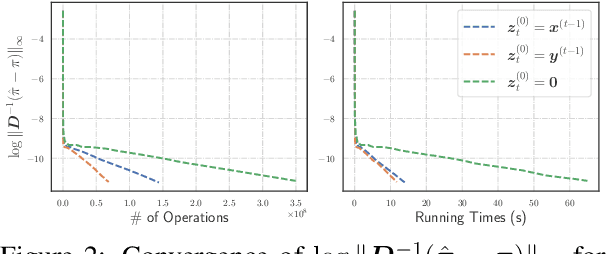
This work proposes a novel framework based on nested evolving set processes to accelerate Personalized PageRank (PPR) computation. At each stage of the process, we employ a localized inexact proximal point iteration to solve a simplified linear system. We show that the time complexity of such localized methods is upper bounded by $\min\{\tilde{\mathcal{O}}(R^2/\epsilon^2), \tilde{\mathcal{O}}(m)\}$ to obtain an $\epsilon$-approximation of the PPR vector, where $m$ denotes the number of edges in the graph and $R$ is a constant defined via nested evolving set processes. Furthermore, the algorithms induced by our framework require solving only $\tilde{\mathcal{O}}(1/\sqrt{\alpha})$ such linear systems, where $\alpha$ is the damping factor. When $1/\epsilon^2\ll m$, this implies the existence of an algorithm that computes an $\ epsilon $-approximation of the PPR vector with an overall time complexity of $\tilde{\mathcal{O}}\left(R^2 / (\sqrt{\alpha}\epsilon^2)\right)$, independent of the underlying graph size. Our result resolves an open conjecture from existing literature. Experimental results on real-world graphs validate the efficiency of our methods, demonstrating significant convergence in the early stages.
Curse of Knowledge: When Complex Evaluation Context Benefits yet Biases LLM Judges
Sep 03, 2025As large language models (LLMs) grow more capable, they face increasingly diverse and complex tasks, making reliable evaluation challenging. The paradigm of LLMs as judges has emerged as a scalable solution, yet prior work primarily focuses on simple settings. Their reliability in complex tasks--where multi-faceted rubrics, unstructured reference answers, and nuanced criteria are critical--remains understudied. In this paper, we constructed ComplexEval, a challenge benchmark designed to systematically expose and quantify Auxiliary Information Induced Biases. We systematically investigated and validated 6 previously unexplored biases across 12 basic and 3 advanced scenarios. Key findings reveal: (1) all evaluated models exhibit significant susceptibility to these biases, with bias magnitude scaling with task complexity; (2) notably, Large Reasoning Models (LRMs) show paradoxical vulnerability. Our in-depth analysis offers crucial insights for improving the accuracy and verifiability of evaluation signals, paving the way for more general and robust evaluation models.
GORACS: Group-level Optimal Transport-guided Coreset Selection for LLM-based Recommender Systems
Jun 04, 2025Although large language models (LLMs) have shown great potential in recommender systems, the prohibitive computational costs for fine-tuning LLMs on entire datasets hinder their successful deployment in real-world scenarios. To develop affordable and effective LLM-based recommender systems, we focus on the task of coreset selection which identifies a small subset of fine-tuning data to optimize the test loss, thereby facilitating efficient LLMs' fine-tuning. Although there exist some intuitive solutions of subset selection, including distribution-based and importance-based approaches, they often lead to suboptimal performance due to the misalignment with downstream fine-tuning objectives or weak generalization ability caused by individual-level sample selection. To overcome these challenges, we propose GORACS, which is a novel Group-level Optimal tRAnsport-guided Coreset Selection framework for LLM-based recommender systems. GORACS is designed based on two key principles for coreset selection: 1) selecting the subsets that minimize the test loss to align with fine-tuning objectives, and 2) enhancing model generalization through group-level data selection. Corresponding to these two principles, GORACS has two key components: 1) a Proxy Optimization Objective (POO) leveraging optimal transport and gradient information to bound the intractable test loss, thus reducing computational costs by avoiding repeated LLM retraining, and 2) a two-stage Initialization-Then-Refinement Algorithm (ITRA) for efficient group-level selection. Our extensive experiments across diverse recommendation datasets and tasks validate that GORACS significantly reduces fine-tuning costs of LLMs while achieving superior performance over the state-of-the-art baselines and full data training. The source code of GORACS are available at https://github.com/Mithas-114/GORACS.
Logical Consistency is Vital: Neural-Symbolic Information Retrieval for Negative-Constraint Queries
May 29, 2025

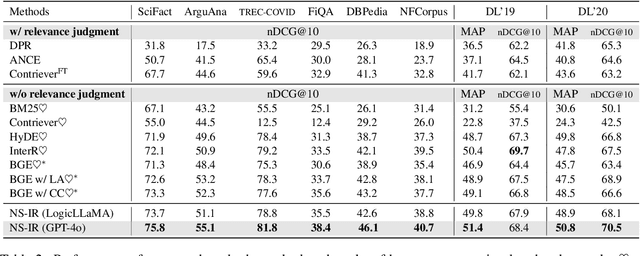
Information retrieval plays a crucial role in resource localization. Current dense retrievers retrieve the relevant documents within a corpus via embedding similarities, which compute similarities between dense vectors mainly depending on word co-occurrence between queries and documents, but overlook the real query intents. Thus, they often retrieve numerous irrelevant documents. Particularly in the scenarios of complex queries such as \emph{negative-constraint queries}, their retrieval performance could be catastrophic. To address the issue, we propose a neuro-symbolic information retrieval method, namely \textbf{NS-IR}, that leverages first-order logic (FOL) to optimize the embeddings of naive natural language by considering the \emph{logical consistency} between queries and documents. Specifically, we introduce two novel techniques, \emph{logic alignment} and \emph{connective constraint}, to rerank candidate documents, thereby enhancing retrieval relevance. Furthermore, we construct a new dataset \textbf{NegConstraint} including negative-constraint queries to evaluate our NS-IR's performance on such complex IR scenarios. Our extensive experiments demonstrate that NS-IR not only achieves superior zero-shot retrieval performance on web search and low-resource retrieval tasks, but also performs better on negative-constraint queries. Our scource code and dataset are available at https://github.com/xgl-git/NS-IR-main.