 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecGPT-V2 Technical Report
Dec 16, 2025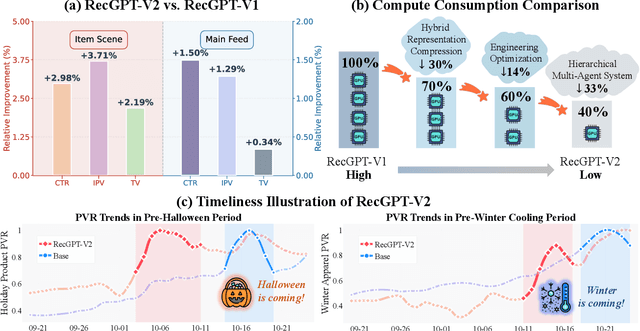
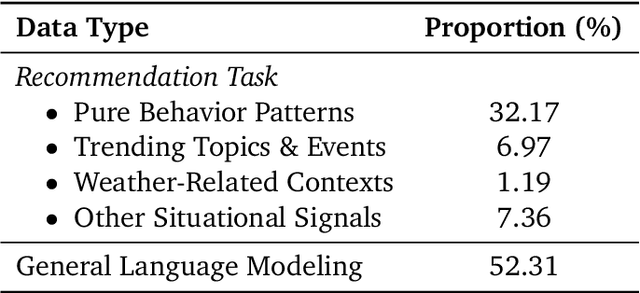
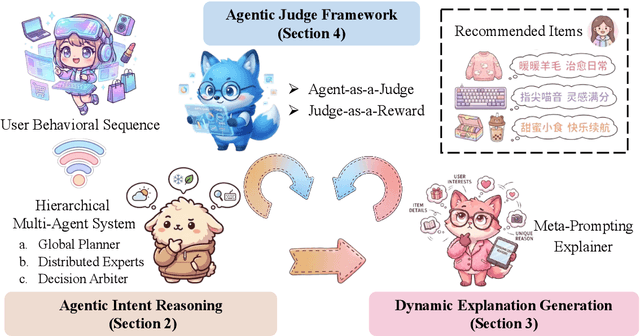

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
FlashThink: An Early Exit Method For Efficient Reasoning
May 20, 2025Large Language Models (LLMs) have shown impressive performance in reasoning tasks. However, LLMs tend to generate excessively long reasoning content, leading to significant computational overhead. Our observations indicate that even on simple problems, LLMs tend to produce unnecessarily lengthy reasoning content, which is against intuitive expectations. Preliminary experiments show that at a certain point during the generation process, the model is already capable of producing the correct solution without completing the full reasoning content. Therefore, we consider that the reasoning process of the model can be exited early to achieve the purpose of efficient reasoning. We introduce a verification model that identifies the exact moment when the model can stop reasoning and still provide the correct answer. Comprehensive experiments on four different benchmarks demonstrate that our proposed method, FlashThink, effectively shortens the reasoning content while preserving the model accuracy. For the Deepseek-R1 and QwQ-32B models, we reduced the length of reasoning content by 77.04% and 77.47%, respectively, without reducing the accuracy.
RLAP: A Reinforcement Learning Enhanced Adaptive Planning Framework for Multi-step NLP Task Solving
May 17, 2025Multi-step planning has been widely employed to enhance the performance of large language models (LLMs) on downstream natural language processing (NLP) tasks, which decomposes the original task into multiple subtasks and guide LLMs to solve them sequentially without additional training. When addressing task instances, existing methods either preset the order of steps or attempt multiple paths at each step. However, these methods overlook instances' linguistic features and rely on the intrinsic planning capabilities of LLMs to evaluate intermediate feedback and then select subtasks, resulting in suboptimal outcomes. To better solve multi-step NLP tasks with LLMs, in this paper we propose a Reinforcement Learning enhanced Adaptive Planning framework (RLAP). In our framework, we model an NLP task as a Markov decision process (MDP) and employ an LLM directly into the environment. In particular, a lightweight Actor model is trained to estimate Q-values for natural language sequences consisting of states and actions through reinforcement learning. Therefore, during sequential planning, the linguistic features of each sequence in the MDP can be taken into account, and the Actor model interacts with the LLM to determine the optimal order of subtasks for each task instance. We apply RLAP on three different types of NLP tasks and conduct extensive experiments on multiple datasets to verify RLAP's effectiveness and robustness.
Benchmarking Language Model Creativity: A Case Study on Code Generation
Jul 12, 2024



As LLMs become increasingly prevalent, it is interesting to consider how ``creative'' these models can be. From cognitive science, creativity consists of at least two key characteristics: \emph{convergent} thinking (purposefulness to achieve a given goal) and \emph{divergent} thinking (adaptability to new environments or constraints) \citep{runco2003critical}. In this work, we introduce a framework for quantifying LLM creativity that incorporates the two characteristics. This is achieved by (1) Denial Prompting pushes LLMs to come up with more creative solutions to a given problem by incrementally imposing new constraints on the previous solution, compelling LLMs to adopt new strategies, and (2) defining and computing the NeoGauge metric which examines both convergent and divergent thinking in the generated creative responses by LLMs. We apply the proposed framework on Codeforces problems, a natural data source for collecting human coding solutions. We quantify NeoGauge for various proprietary and open-source models and find that even the most creative model, GPT-4, still falls short of demonstrating human-like creativity. We also experiment with advanced reasoning strategies (MCTS, self-correction, etc.) and observe no significant improvement in creativity. As a by-product of our analysis, we release NeoCoder dataset for reproducing our results on future models.
Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization
May 27, 2024Large Language Models (LLMs) have shown remarkable capabilities in language understanding and generation. Nonetheless, it was also witnessed that LLMs tend to produce inaccurate responses to specific queries. This deficiency can be traced to the tokenization step LLMs must undergo, which is an inevitable limitation inherent to all LLMs. In fact, incorrect tokenization is the critical point that hinders LLMs in understanding the input precisely, thus leading to unsatisfactory output. To demonstrate this flaw of LLMs, we construct an adversarial dataset, named as $\textbf{ADT (Adversarial Dataset for Tokenizer)}$, which draws upon the vocabularies of various open-source LLMs to challenge LLMs' tokenization. ADT consists of two subsets: the manually constructed ADT-Human and the automatically generated ADT-Auto. Our empirical results reveal that our ADT is highly effective on challenging the tokenization of leading LLMs, including GPT-4o, Llama-3, Qwen2.5-max and so on, thus degrading these LLMs' capabilities. Moreover, our method of automatic data generation has been proven efficient and robust, which can be applied to any open-source LLMs. To the best of our knowledge, our study is the first to investigating LLMs' vulnerability in terms of challenging their token segmentation, which will shed light on the subsequent research of improving LLMs' capabilities through optimizing their tokenization process and algorithms.
ToNER: Type-oriented Named Entity Recognition with Generative Language Model
Apr 14, 2024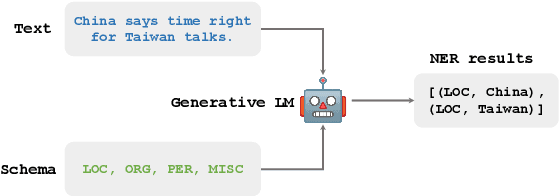

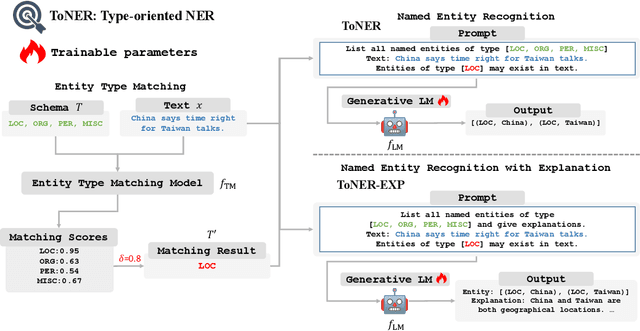

In recent years, the fine-tuned generative models have been proven more powerful than the previous tagging-based or span-based models on named entity recognition (NER) task. It has also been found that the information related to entities, such as entity types, can prompt a model to achieve NER better. However, it is not easy to determine the entity types indeed existing in the given sentence in advance, and inputting too many potential entity types would distract the model inevitably. To exploit entity types' merit on promoting NER task, in this paper we propose a novel NER framework, namely ToNER based on a generative model. In ToNER, a type matching model is proposed at first to identify the entity types most likely to appear in the sentence. Then, we append a multiple binary classification task to fine-tune the generative model's encoder, so as to generate the refined representation of the input sentence. Moreover, we add an auxiliary task for the model to discover the entity types which further fine-tunes the model to output more accurate results. Our extensive experiments on some NER benchmarks verify the effectiveness of our proposed strategies in ToNER that are oriented towards entity types' exploitation.
Reason from Fallacy: Enhancing Large Language Models' Logical Reasoning through Logical Fallacy Understanding
Apr 04, 2024



Large Language Models (LLMs) have demonstrated good performance in many reasoning tasks, but they still struggle with some complicated reasoning tasks including logical reasoning. One non-negligible reason for LLMs' suboptimal performance on logical reasoning is their overlooking of understanding logical fallacies correctly. To evaluate LLMs' capability of logical fallacy understanding (LFU), we propose five concrete tasks from three cognitive dimensions of WHAT, WHY, and HOW in this paper. Towards these LFU tasks, we have successfully constructed a new dataset LFUD based on GPT-4 accompanied by a little human effort. Our extensive experiments justify that our LFUD can be used not only to evaluate LLMs' LFU capability, but also to fine-tune LLMs to obtain significantly enhanced performance on logical reasoning.