 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTPChat: A Multimodal Time-Aware Persona Dataset for Conversational Agents
Feb 09, 2025Understanding temporal dynamics is critical for conversational agents, enabling effective content analysis and informed decision-making. However, time-aware datasets, particularly for persona-grounded conversations, are still limited, which narrows their scope and diminishes their complexity. To address this gap, we introduce MTPChat, a multimodal, time-aware persona dialogue dataset that integrates linguistic, visual, and temporal elements within dialogue and persona memory. Leveraging MTPChat, we propose two time-sensitive tasks: Temporal Next Response Prediction (TNRP) and Temporal Grounding Memory Prediction (TGMP), both designed to assess a model's ability to understand implicit temporal cues and dynamic interactions. Additionally, we present an innovative framework featuring an adaptive temporal module to effectively integrate multimodal streams and capture temporal dependencies. Experimental results validate the challenges posed by MTPChat and demonstrate the effectiveness of our framework in multimodal time-sensitive scenarios.
Who Can Withstand Chat-Audio Attacks? An Evaluation Benchmark for Large Language Models
Nov 22, 2024Adversarial audio attacks pose a significant threat to the growing use of large language models (LLMs) in voice-based human-machine interactions. While existing research has primarily focused on model-specific adversarial methods, real-world applications demand a more generalizable and universal approach to audio adversarial attacks. In this paper, we introduce the Chat-Audio Attacks (CAA) benchmark including four distinct types of audio attacks, which aims to explore the the vulnerabilities of LLMs to these audio attacks in conversational scenarios. To evaluate the robustness of LLMs, we propose three evaluation strategies: Standard Evaluation, utilizing traditional metrics to quantify model performance under attacks; GPT-4o-Based Evaluation, which simulates real-world conversational complexities; and Human Evaluation, offering insights into user perception and trust. We evaluate six state-of-the-art LLMs with voice interaction capabilities, including Gemini-1.5-Pro, GPT-4o, and others, using three distinct evaluation methods on the CAA benchmark. Our comprehensive analysis reveals the impact of four types of audio attacks on the performance of these models, demonstrating that GPT-4o exhibits the highest level of resilience.
Enhancing Temporal Sensitivity and Reasoning for Time-Sensitive Question Answering
Sep 25, 2024Time-Sensitive Question Answering (TSQA) demands the effective utilization of specific temporal contexts, encompassing multiple time-evolving facts, to address time-sensitive questions. This necessitates not only the parsing of temporal information within questions but also the identification and understanding of time-evolving facts to generate accurate answers. However, current large language models still have limited sensitivity to temporal information and their inadequate temporal reasoning capabilities.In this paper, we propose a novel framework that enhances temporal awareness and reasoning through Temporal Information-Aware Embedding and Granular Contrastive Reinforcement Learning. Experimental results on four TSQA datasets demonstrate that our framework significantly outperforms existing LLMs in TSQA tasks, marking a step forward in bridging the performance gap between machine and human temporal understanding and reasoning.
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
Aug 05, 2024



With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
Continual Learning for Temporal-Sensitive Question Answering
Jul 17, 2024



In this study, we explore an emerging research area of Continual Learning for Temporal Sensitive Question Answering (CLTSQA). Previous research has primarily focused on Temporal Sensitive Question Answering (TSQA), often overlooking the unpredictable nature of future events. In real-world applications, it's crucial for models to continually acquire knowledge over time, rather than relying on a static, complete dataset. Our paper investigates strategies that enable models to adapt to the ever-evolving information landscape, thereby addressing the challenges inherent in CLTSQA. To support our research, we first create a novel dataset, divided into five subsets, designed specifically for various stages of continual learning. We then propose a training framework for CLTSQA that integrates temporal memory replay and temporal contrastive learning. Our experimental results highlight two significant insights: First, the CLTSQA task introduces unique challenges for existing models. Second, our proposed framework effectively navigates these challenges, resulting in improved performance.
Adaptive Reinforcement Learning Planning: Harnessing Large Language Models for Complex Information Extraction
Jun 17, 2024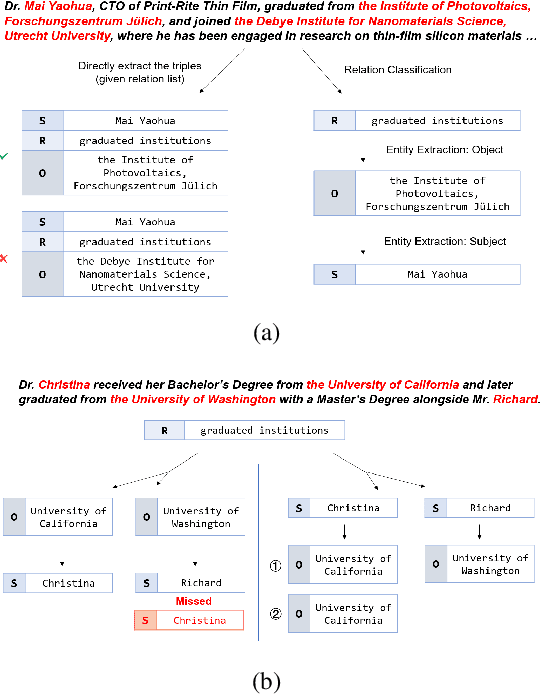
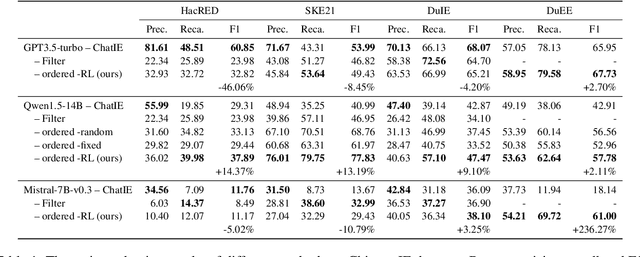
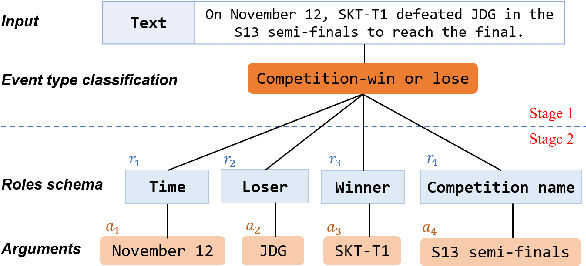
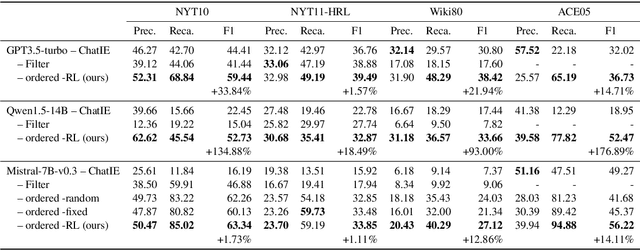
Existing research on large language models (LLMs) shows that they can solve information extraction tasks through multi-step planning. However, their extraction behavior on complex sentences and tasks is unstable, emerging issues such as false positives and missing elements. We observe that decomposing complex extraction tasks and extracting them step by step can effectively improve LLMs' performance, and the extraction orders of entities significantly affect the final results of LLMs. This paper proposes a two-stage multi-step method for LLM-based information extraction and adopts the RL framework to execute the multi-step planning. We regard sequential extraction as a Markov decision process, build an LLM-based extraction environment, design a decision module to adaptively provide the optimal order for sequential entity extraction on different sentences, and utilize the DDQN algorithm to train the decision model. We also design the rewards and evaluation metrics suitable for the extraction results of LLMs. We conduct extensive experiments on multiple public datasets to demonstrate the effectiveness of our method in improving the information extraction capabilities of LLMs.
Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization
May 27, 2024Large Language Models (LLMs) have shown remarkable capabilities in language understanding and generation. Nonetheless, it was also witnessed that LLMs tend to produce inaccurate responses to specific queries. This deficiency can be traced to the tokenization step LLMs must undergo, which is an inevitable limitation inherent to all LLMs. In fact, incorrect tokenization is the critical point that hinders LLMs in understanding the input precisely, thus leading to unsatisfactory output. To demonstrate this flaw of LLMs, we construct an adversarial dataset, named as $\textbf{ADT (Adversarial Dataset for Tokenizer)}$, which draws upon the vocabularies of various open-source LLMs to challenge LLMs' tokenization. ADT consists of two subsets: the manually constructed ADT-Human and the automatically generated ADT-Auto. Our empirical results reveal that our ADT is highly effective on challenging the tokenization of leading LLMs, including GPT-4o, Llama-3, Qwen2.5-max and so on, thus degrading these LLMs' capabilities. Moreover, our method of automatic data generation has been proven efficient and robust, which can be applied to any open-source LLMs. To the best of our knowledge, our study is the first to investigating LLMs' vulnerability in terms of challenging their token segmentation, which will shed light on the subsequent research of improving LLMs' capabilities through optimizing their tokenization process and algorithms.
Reason from Fallacy: Enhancing Large Language Models' Logical Reasoning through Logical Fallacy Understanding
Apr 04, 2024



Large Language Models (LLMs) have demonstrated good performance in many reasoning tasks, but they still struggle with some complicated reasoning tasks including logical reasoning. One non-negligible reason for LLMs' suboptimal performance on logical reasoning is their overlooking of understanding logical fallacies correctly. To evaluate LLMs' capability of logical fallacy understanding (LFU), we propose five concrete tasks from three cognitive dimensions of WHAT, WHY, and HOW in this paper. Towards these LFU tasks, we have successfully constructed a new dataset LFUD based on GPT-4 accompanied by a little human effort. Our extensive experiments justify that our LFUD can be used not only to evaluate LLMs' LFU capability, but also to fine-tune LLMs to obtain significantly enhanced performance on logical reasoning.
StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data
Aug 20, 2023The remarkable multimodal capabilities demonstrated by OpenAI's GPT-4 have sparked significant interest in the development of multimodal Large Language Models (LLMs). A primary research objective of such models is to align visual and textual modalities effectively while comprehending human instructions. Current methodologies often rely on annotations derived from benchmark datasets to construct image-dialogue datasets for training purposes, akin to instruction tuning in LLMs. However, these datasets often exhibit domain bias, potentially constraining the generative capabilities of the models. In an effort to mitigate these limitations, we propose a novel data collection methodology that synchronously synthesizes images and dialogues for visual instruction tuning. This approach harnesses the power of generative models, marrying the abilities of ChatGPT and text-to-image generative models to yield a diverse and controllable dataset with varied image content. This not only provides greater flexibility compared to existing methodologies but also significantly enhances several model capabilities. Our research includes comprehensive experiments conducted on various datasets using the open-source LLAVA model as a testbed for our proposed pipeline. Our results underscore marked enhancements across more than ten commonly assessed capabilities,
Disentangled Pre-training for Image Matting
Apr 03, 2023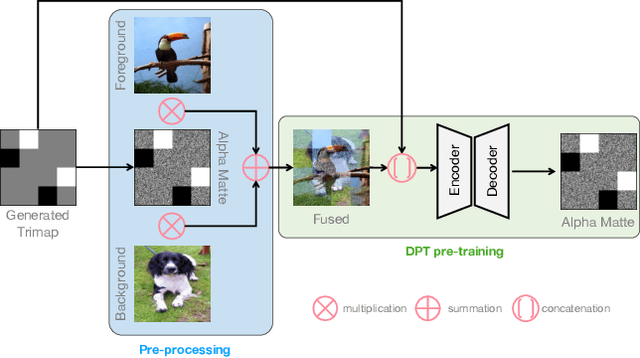



Image matting requires high-quality pixel-level human annotations to support the training of a deep model in recent literature. Whereas such annotation is costly and hard to scale, significantly holding back the development of the research. In this work, we make the first attempt towards addressing this problem, by proposing a self-supervised pre-training approach that can leverage infinite numbers of data to boost the matting performance. The pre-training task is designed in a similar manner as image matting, where random trimap and alpha matte are generated to achieve an image disentanglement objective. The pre-trained model is then used as an initialisation of the downstream matting task for fine-tuning. Extensive experimental evaluations show that the proposed approach outperforms both the state-of-the-art matting methods and other alternative self-supervised initialisation approaches by a large margin. We also show the robustness of the proposed approach over different backbone architectures. The code and models will be publicly available.