 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for Temporal-Sensitive Question Answering
Jul 17, 2024



In this study, we explore an emerging research area of Continual Learning for Temporal Sensitive Question Answering (CLTSQA). Previous research has primarily focused on Temporal Sensitive Question Answering (TSQA), often overlooking the unpredictable nature of future events. In real-world applications, it's crucial for models to continually acquire knowledge over time, rather than relying on a static, complete dataset. Our paper investigates strategies that enable models to adapt to the ever-evolving information landscape, thereby addressing the challenges inherent in CLTSQA. To support our research, we first create a novel dataset, divided into five subsets, designed specifically for various stages of continual learning. We then propose a training framework for CLTSQA that integrates temporal memory replay and temporal contrastive learning. Our experimental results highlight two significant insights: First, the CLTSQA task introduces unique challenges for existing models. Second, our proposed framework effectively navigates these challenges, resulting in improved performance.
Re-Temp: Relation-Aware Temporal Representation Learning for Temporal Knowledge Graph Completion
Oct 24, 2023



Temporal Knowledge Graph Completion (TKGC) under the extrapolation setting aims to predict the missing entity from a fact in the future, posing a challenge that aligns more closely with real-world prediction problems. Existing research mostly encodes entities and relations using sequential graph neural networks applied to recent snapshots. However, these approaches tend to overlook the ability to skip irrelevant snapshots according to entity-related relations in the query and disregard the importance of explicit temporal information. To address this, we propose our model, Re-Temp (Relation-Aware Temporal Representation Learning), which leverages explicit temporal embedding as input and incorporates skip information flow after each timestamp to skip unnecessary information for prediction. Additionally, we introduce a two-phase forward propagation method to prevent information leakage. Through the evaluation on six TKGC (extrapolation) datasets, we demonstrate that our model outperforms all eight recent state-of-the-art models by a significant margin.
Graph Neural Networks for Text Classification: A Survey
Apr 27, 2023Text Classification is the most essential and fundamental problem in Natural Language Processing. While numerous recent text classification models applied the sequential deep learning technique, graph neural network-based models can directly deal with complex structured text data and exploit global information. Many real text classification applications can be naturally cast into a graph, which captures words, documents, and corpus global features. In this survey, we bring the coverage of methods up to 2023, including corpus-level and document-level graph neural networks. We discuss each of these methods in detail, dealing with the graph construction mechanisms and the graph-based learning process. As well as the technological survey, we look at issues behind and future directions addressed in text classification using graph neural networks. We also cover datasets, evaluation metrics, and experiment design and present a summary of published performance on the publicly available benchmarks. Note that we present a comprehensive comparison between different techniques and identify the pros and cons of various evaluation metrics in this survey.
InducT-GCN: Inductive Graph Convolutional Networks for Text Classification
Jun 01, 2022
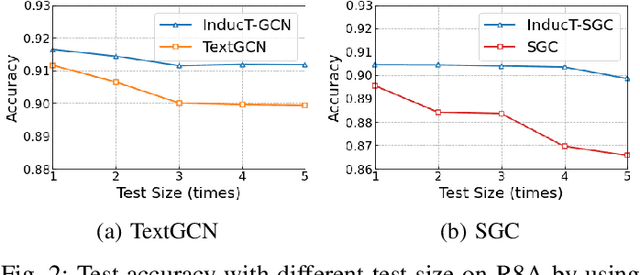
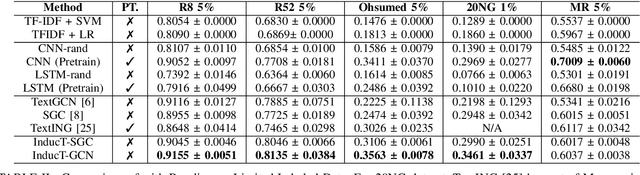
Text classification aims to assign labels to textual units by making use of global information. Recent studies have applied graph neural network (GNN) to capture the global word co-occurrence in a corpus. Existing approaches require that all the nodes (training and test) in a graph are present during training, which are transductive and do not naturally generalise to unseen nodes. To make those models inductive, they use extra resources, like pretrained word embedding. However, high-quality resource is not always available and hard to train. Under the extreme settings with no extra resource and limited amount of training set, can we still learn an inductive graph-based text classification model? In this paper, we introduce a novel inductive graph-based text classification framework, InducT-GCN (InducTive Graph Convolutional Networks for Text classification). Compared to transductive models that require test documents in training, we construct a graph based on the statistics of training documents only and represent document vectors with a weighted sum of word vectors. We then conduct one-directional GCN propagation during testing. Across five text classification benchmarks, our InducT-GCN outperformed state-of-the-art methods that are either transductive in nature or pre-trained additional resources. We also conducted scalability testing by gradually increasing the data size and revealed that our InducT-GCN can reduce the time and space complexity. The code is available on: https://github.com/usydnlp/InductTGCN.
ME-GCN: Multi-dimensional Edge-Embedded Graph Convolutional Networks for Semi-supervised Text Classification
Apr 10, 2022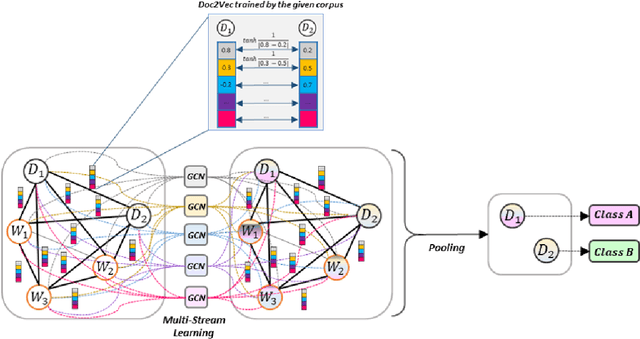
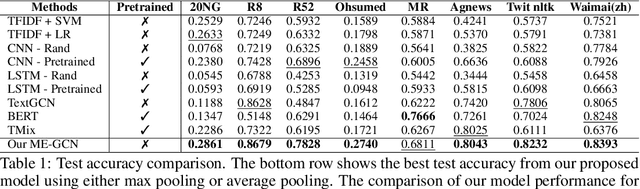
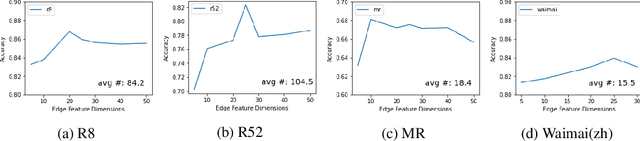

Compared to sequential learning models, graph-based neural networks exhibit excellent ability in capturing global information and have been used for semi-supervised learning tasks. Most Graph Convolutional Networks are designed with the single-dimensional edge feature and failed to utilise the rich edge information about graphs. This paper introduces the ME-GCN (Multi-dimensional Edge-enhanced Graph Convolutional Networks) for semi-supervised text classification. A text graph for an entire corpus is firstly constructed to describe the undirected and multi-dimensional relationship of word-to-word, document-document, and word-to-document. The graph is initialised with corpus-trained multi-dimensional word and document node representation, and the relations are represented according to the distance of those words/documents nodes. Then, the generated graph is trained with ME-GCN, which considers the edge features as multi-stream signals, and each stream performs a separate graph convolutional operation. Our ME-GCN can integrate a rich source of graph edge information of the entire text corpus. The results have demonstrated that our proposed model has significantly outperformed the state-of-the-art methods across eight benchmark datasets.
Understanding Graph Convolutional Networks for Text Classification
Mar 30, 2022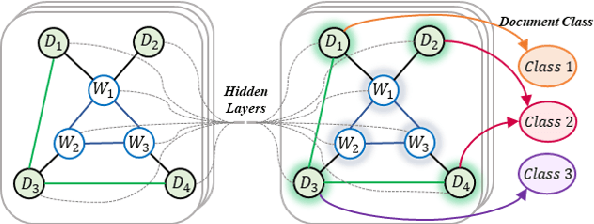
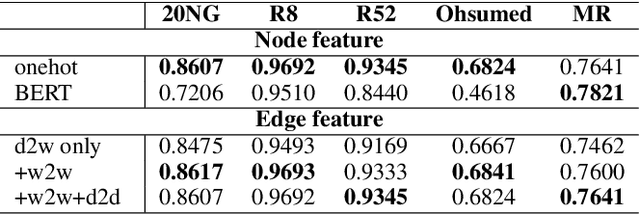
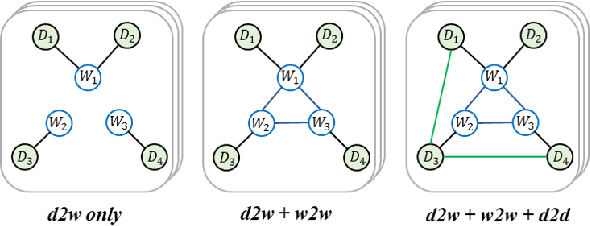
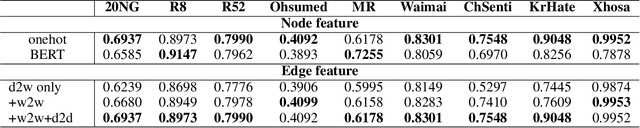
Graph Convolutional Networks (GCN) have been effective at tasks that have rich relational structure and can preserve global structure information of a dataset in graph embeddings. Recently, many researchers focused on examining whether GCNs could handle different Natural Language Processing tasks, especially text classification. While applying GCNs to text classification is well-studied, its graph construction techniques, such as node/edge selection and their feature representation, and the optimal GCN learning mechanism in text classification is rather neglected. In this paper, we conduct a comprehensive analysis of the role of node and edge embeddings in a graph and its GCN learning techniques in text classification. Our analysis is the first of its kind and provides useful insights into the importance of each graph node/edge construction mechanism when applied at the GCN training/testing in different text classification benchmarks, as well as under its semi-supervised environment.
CONDA: a CONtextual Dual-Annotated dataset for in-game toxicity understanding and detection
Jun 11, 2021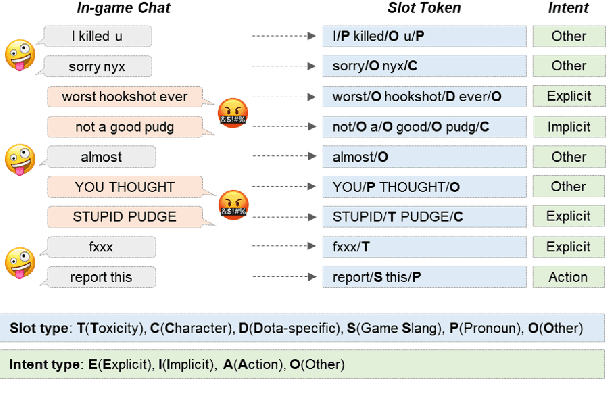
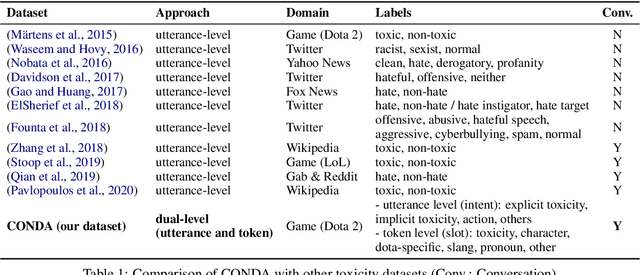

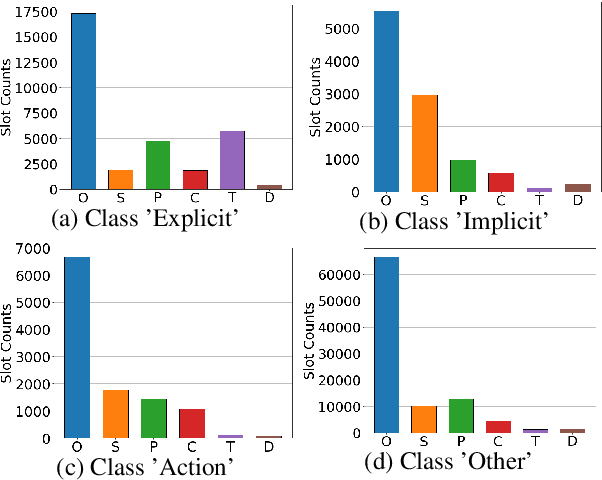
Traditional toxicity detection models have focused on the single utterance level without deeper understanding of context. We introduce CONDA, a new dataset for in-game toxic language detection enabling joint intent classification and slot filling analysis, which is the core task of Natural Language Understanding (NLU). The dataset consists of 45K utterances from 12K conversations from the chat logs of 1.9K completed Dota 2 matches. We propose a robust dual semantic-level toxicity framework, which handles utterance and token-level patterns, and rich contextual chatting history. Accompanying the dataset is a thorough in-game toxicity analysis, which provides comprehensive understanding of context at utterance, token, and dual levels. Inspired by NLU, we also apply its metrics to the toxicity detection tasks for assessing toxicity and game-specific aspects. We evaluate strong NLU models on CONDA, providing fine-grained results for different intent classes and slot classes. Furthermore, we examine the coverage of toxicity nature in our dataset by comparing it with other toxicity datasets.
VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
Oct 25, 2020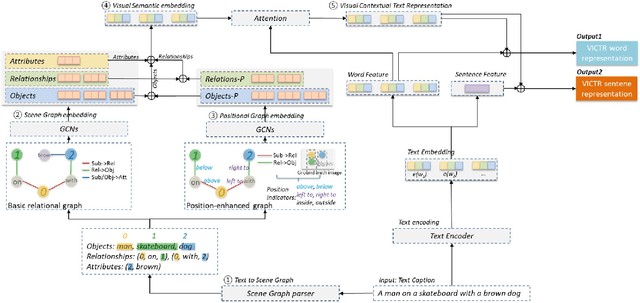
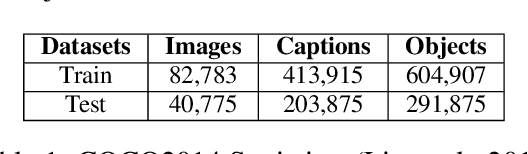
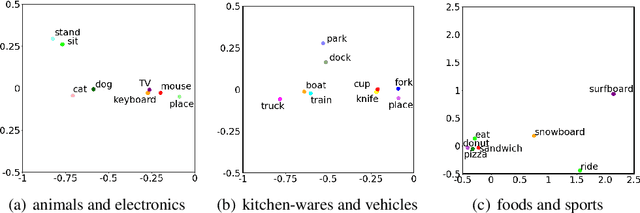
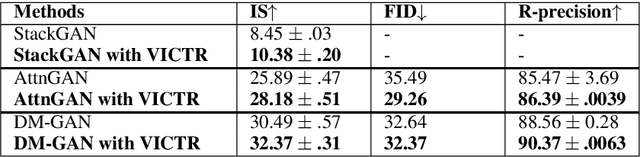
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.
Detect All Abuse! Toward Universal Abusive Language Detection Models
Oct 09, 2020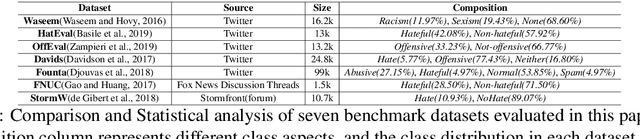
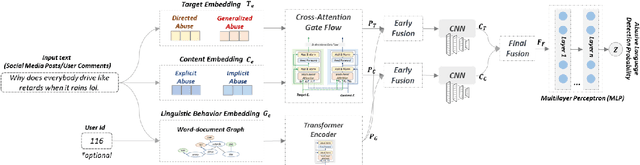

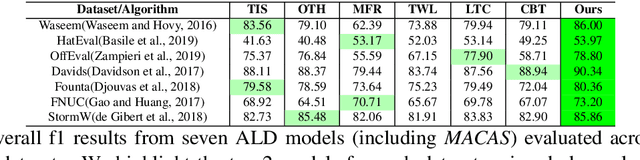
Online abusive language detection (ALD) has become a societal issue of increasing importance in recent years. Several previous works in online ALD focused on solving a single abusive language problem in a single domain, like Twitter, and have not been successfully transferable to the general ALD task or domain. In this paper, we introduce a new generic ALD framework, MACAS, which is capable of addressing several types of ALD tasks across different domains. Our generic framework covers multi-aspect abusive language embeddings that represent the target and content aspects of abusive language and applies a textual graph embedding that analyses the user's linguistic behaviour. Then, we propose and use the cross-attention gate flow mechanism to embrace multiple aspects of abusive language. Quantitative and qualitative evaluation results show that our ALD algorithm rivals or exceeds the six state-of-the-art ALD algorithms across seven ALD datasets covering multiple aspects of abusive language and different online community domains.