 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing and Composing: Towards Efficient Vision-Language Continual Learning via Rank-1 Expert Pool in a Single LoRA
Jan 30, 2026Continual learning (CL) in vision-language models (VLMs) faces significant challenges in improving task adaptation and avoiding catastrophic forgetting. Existing methods usually have heavy inference burden or rely on external knowledge, while Low-Rank Adaptation (LoRA) has shown potential in reducing these issues by enabling parameter-efficient tuning. However, considering directly using LoRA to alleviate the catastrophic forgetting problem is non-trivial, we introduce a novel framework that restructures a single LoRA module as a decomposable Rank-1 Expert Pool. Our method learns to dynamically compose a sparse, task-specific update by selecting from this expert pool, guided by the semantics of the [CLS] token. In addition, we propose an Activation-Guided Orthogonal (AGO) loss that orthogonalizes critical parts of LoRA weights across tasks. This sparse composition and orthogonalization enable fewer parameter updates, resulting in domain-aware learning while minimizing inter-task interference and maintaining downstream task performance. Extensive experiments across multiple settings demonstrate state-of-the-art results in all metrics, surpassing zero-shot upper bounds in generalization. Notably, it reduces trainable parameters by 96.7% compared to the baseline method, eliminating reliance on external datasets or task-ID discriminators. The merged LoRAs retain less weights and incur no inference latency, making our method computationally lightweight.
MTPChat: A Multimodal Time-Aware Persona Dataset for Conversational Agents
Feb 09, 2025Understanding temporal dynamics is critical for conversational agents, enabling effective content analysis and informed decision-making. However, time-aware datasets, particularly for persona-grounded conversations, are still limited, which narrows their scope and diminishes their complexity. To address this gap, we introduce MTPChat, a multimodal, time-aware persona dialogue dataset that integrates linguistic, visual, and temporal elements within dialogue and persona memory. Leveraging MTPChat, we propose two time-sensitive tasks: Temporal Next Response Prediction (TNRP) and Temporal Grounding Memory Prediction (TGMP), both designed to assess a model's ability to understand implicit temporal cues and dynamic interactions. Additionally, we present an innovative framework featuring an adaptive temporal module to effectively integrate multimodal streams and capture temporal dependencies. Experimental results validate the challenges posed by MTPChat and demonstrate the effectiveness of our framework in multimodal time-sensitive scenarios.
Who Can Withstand Chat-Audio Attacks? An Evaluation Benchmark for Large Language Models
Nov 22, 2024Adversarial audio attacks pose a significant threat to the growing use of large language models (LLMs) in voice-based human-machine interactions. While existing research has primarily focused on model-specific adversarial methods, real-world applications demand a more generalizable and universal approach to audio adversarial attacks. In this paper, we introduce the Chat-Audio Attacks (CAA) benchmark including four distinct types of audio attacks, which aims to explore the the vulnerabilities of LLMs to these audio attacks in conversational scenarios. To evaluate the robustness of LLMs, we propose three evaluation strategies: Standard Evaluation, utilizing traditional metrics to quantify model performance under attacks; GPT-4o-Based Evaluation, which simulates real-world conversational complexities; and Human Evaluation, offering insights into user perception and trust. We evaluate six state-of-the-art LLMs with voice interaction capabilities, including Gemini-1.5-Pro, GPT-4o, and others, using three distinct evaluation methods on the CAA benchmark. Our comprehensive analysis reveals the impact of four types of audio attacks on the performance of these models, demonstrating that GPT-4o exhibits the highest level of resilience.
Enhancing Temporal Sensitivity and Reasoning for Time-Sensitive Question Answering
Sep 25, 2024Time-Sensitive Question Answering (TSQA) demands the effective utilization of specific temporal contexts, encompassing multiple time-evolving facts, to address time-sensitive questions. This necessitates not only the parsing of temporal information within questions but also the identification and understanding of time-evolving facts to generate accurate answers. However, current large language models still have limited sensitivity to temporal information and their inadequate temporal reasoning capabilities.In this paper, we propose a novel framework that enhances temporal awareness and reasoning through Temporal Information-Aware Embedding and Granular Contrastive Reinforcement Learning. Experimental results on four TSQA datasets demonstrate that our framework significantly outperforms existing LLMs in TSQA tasks, marking a step forward in bridging the performance gap between machine and human temporal understanding and reasoning.
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
Aug 05, 2024



With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
Continual Learning for Temporal-Sensitive Question Answering
Jul 17, 2024



In this study, we explore an emerging research area of Continual Learning for Temporal Sensitive Question Answering (CLTSQA). Previous research has primarily focused on Temporal Sensitive Question Answering (TSQA), often overlooking the unpredictable nature of future events. In real-world applications, it's crucial for models to continually acquire knowledge over time, rather than relying on a static, complete dataset. Our paper investigates strategies that enable models to adapt to the ever-evolving information landscape, thereby addressing the challenges inherent in CLTSQA. To support our research, we first create a novel dataset, divided into five subsets, designed specifically for various stages of continual learning. We then propose a training framework for CLTSQA that integrates temporal memory replay and temporal contrastive learning. Our experimental results highlight two significant insights: First, the CLTSQA task introduces unique challenges for existing models. Second, our proposed framework effectively navigates these challenges, resulting in improved performance.
EMPL: A novel Efficient Meta Prompt Learning Framework for Few-shot Unsupervised Domain Adaptation
Jul 04, 2024



Few-shot unsupervised domain adaptation (FS-UDA) utilizes few-shot labeled source domain data to realize effective classification in unlabeled target domain. However, current FS-UDA methods are still suffer from two issues: 1) the data from different domains can not be effectively aligned by few-shot labeled data due to the large domain gaps, 2) it is unstable and time-consuming to generalize to new FS-UDA tasks.To address this issue, we put forward a novel Efficient Meta Prompt Learning Framework for FS-UDA. Within this framework, we use pre-trained CLIP model as the feature learning base model. First, we design domain-shared prompt learning vectors composed of virtual tokens, which mainly learns the meta knowledge from a large number of meta tasks to mitigate domain gaps. Secondly, we also design a task-shared prompt learning network to adaptively learn specific prompt vectors for each task, which aims to realize fast adaptation and task generalization. Thirdly, we learn a task-specific cross-domain alignment projection and a task-specific classifier with closed-form solutions for each meta task, which can efficiently adapt the model to new tasks in one step. The whole learning process is formulated as a bilevel optimization problem, and a good initialization of model parameters is learned through meta-learning. Extensive experimental study demonstrates the promising performance of our framework on benchmark datasets. Our method has the large improvement of at least 15.4% on 5-way 1-shot and 8.7% on 5-way 5-shot, compared with the state-of-the-art methods. Also, the performance of our method on all the test tasks is more stable than the other methods.
Domain Generalizable Knowledge Tracing via Concept Aggregation and Relation-Based Attention
Jul 02, 2024
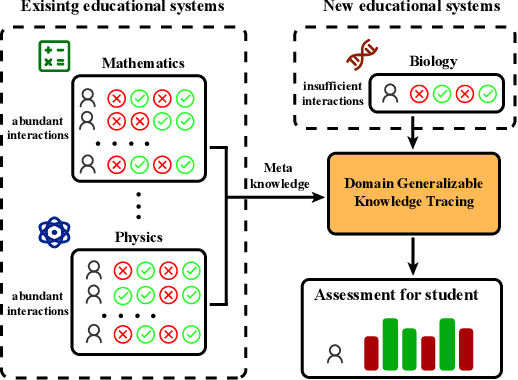


Knowledge Tracing (KT) is a critical task in online education systems, aiming to monitor students' knowledge states throughout a learning period. Common KT approaches involve predicting the probability of a student correctly answering the next question based on their exercise history. However, these methods often suffer from performance degradation when faced with the scarcity of student interactions in new education systems. To address this, we leverage student interactions from existing education systems to mitigate performance degradation caused by limited training data. Nevertheless, these interactions exhibit significant differences since they are derived from different education systems. To address this issue, we propose a domain generalization approach for knowledge tracing, where existing education systems are considered source domains, and new education systems with limited data are considered target domains. Additionally, we design a domain-generalizable knowledge tracing framework (DGKT) that can be applied to any KT model. Specifically, we present a concept aggregation approach designed to reduce conceptual disparities within sequences of student interactions from diverse domains. To further mitigate domain discrepancies, we introduce a novel normalization module called Sequence Instance Normalization (SeqIN). Moreover, to fully leverage exercise information, we propose a new knowledge tracing model tailored for the domain generalization KT task, named Domain-Generalizable Relation-based Knowledge Tracing (DGRKT). Extensive experiments across five benchmark datasets demonstrate that the proposed method performs well despite limited training data.
Hybrid Feature Collaborative Reconstruction Network for Few-Shot Fine-Grained Image Classification
Jul 02, 2024



Our research focuses on few-shot fine-grained image classification, which faces two major challenges: appearance similarity of fine-grained objects and limited number of samples. To preserve the appearance details of images, traditional feature reconstruction networks usually enhance the representation ability of key features by spatial feature reconstruction and minimizing the reconstruction error. However, we find that relying solely on a single type of feature is insufficient for accurately capturing inter-class differences of fine-grained objects in scenarios with limited samples. In contrast, the introduction of channel features provides additional information dimensions, aiding in better understanding and distinguishing the inter-class differences of fine-grained objects. Therefore, in this paper, we design a new Hybrid Feature Collaborative Reconstruction Network (HFCR-Net) for few-shot fine-grained image classification, which includes a Hybrid Feature Fusion Process (HFFP) and a Hybrid Feature Reconstruction Process (HFRP). In HFRP, we fuse the channel features and the spatial features. Through dynamic weight adjustment, we aggregate the spatial dependencies between arbitrary two positions and the correlations between different channels of each image to increase the inter-class differences. Additionally, we introduce the reconstruction of channel dimension in HFRP. Through the collaborative reconstruction of channel dimension and spatial dimension, the inter-class differences are further increased in the process of support-to-query reconstruction, while the intra-class differences are reduced in the process of query-to-support reconstruction. Ultimately, our extensive experiments on three widely used fine-grained datasets demonstrate the effectiveness and superiority of our approach.
Multi-level Reliable Guidance for Unpaired Multi-view Clustering
Jul 02, 2024In this paper, we address the challenging problem of unpaired multi-view clustering (UMC), aiming to perform effective joint clustering using unpaired observed samples across multiple views. Commonly, traditional incomplete multi-view clustering (IMC) methods often depend on paired samples to capture complementary information between views. However, the strategy becomes impractical in UMC due to the absence of paired samples. Although some researchers have attempted to tackle the issue by preserving consistent cluster structures across views, they frequently neglect the confidence of these cluster structures, especially for boundary samples and uncertain cluster structures during the initial training. Therefore, we propose a method called Multi-level Reliable Guidance for UMC (MRG-UMC), which leverages multi-level clustering to aid in learning a trustworthy cluster structure across inner-view, cross-view, and common-view, respectively. Specifically, within each view, multi-level clustering fosters a trustworthy cluster structure across different levels and reduces clustering error. In cross-view learning, reliable view guidance enhances the confidence of the cluster structures in other views. Similarly, within the multi-level framework, the incorporation of a common view aids in aligning different views, thereby reducing the clustering error and uncertainty of cluster structure. Finally, as evidenced by extensive experiments, our method for UMC demonstrates significant efficiency improvements compared to 20 state-of-the-art methods.