 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Distilled Neural Network enabled by Large Language Models for Manufacturing Process-Property Predictive Modeling
Jun 10, 2026Predicting process-property relationships in manufacturing is often challenged by high experimental costs and the limited interpretability of complex 'black-box' models. This paper proposes a novel knowledge distillation framework designed to achieve high-accuracy predictions in data-scarce scenarios. The framework integrates analytical physics priors, which are systematically extracted from scientific literature via Large Language Models, into a privileged teacher model. We employ a Graph-Masked Attention layer to capture the complex physical dependencies among input variables showing strict setpoints or a combination of static and high-frequency temporal signatures. This privileged knowledge is distilled into a lightweight student predictor for inference. The feasibility and robustness of the framework are evaluated through a comprehensive experiment across five diverse manufacturing processes. To ensure statistical reliability, given the small dataset sizes, a repeated K-fold cross-validation technique is employed to quantify model stability and generalization. Results indicate that the proposed framework consistently achieves high predictive accuracy across all evaluated domains. Most importantly, the architecture demonstrates significant fault tolerance by maintaining robust predictive performance even in scenarios where LLM-derived analytical priors are suboptimal or incomplete. Furthermore, the student predictor achieves an inference frequency exceeding 6000 Hz, which facilitates real-time edge deployment on standard industrial hardware. This work provides a scalable solution for bridging the gap between theoretical physics and real-time industrial monitoring in data-limited environments.
Rethinking Visual Neglect: Steering via Context-Preference for MLLM Hallucination Mitigation
May 27, 2026Object hallucination remains a primary obstacle to the reliable deployment of Multimodal Large Language Models (MLLMs). Current inference-time mitigation methods mainly assume hallucinations stem from visual neglect, steering models to enhance visual reliance. In contrast, our systematic interventions on multiple MLLMs show that pushing toward more visual reliance may exacerbate hallucinations on some models, while less may mitigate hallucinations. This result suggests that attributing hallucinations solely to visual insufficiency is underdetermined. We argue that the image, as a context, simultaneously competes with the model's parametric knowledge and the textual context. For this, we propose a training-free framework, Context-Preference Activation Steering (CAS). It extracts two semantically distinct Context Preference Vectors (CPVs) via two small sets of designed conflict samples and applies them via single-pass signed residual injection at mid-early MLP layers during inference to control information reliance. Experiments show that CAS substantially mitigates object hallucinations without increasing decoding latency and preserves native text-generation quality.
Versioned Late Materialization for Ultra-Long Sequence Training in Recommendation Systems at Scale
Apr 27, 2026Modern Deep Learning Recommendation Models (DLRMs) follow scaling laws with sequence length, driving the frontier toward ultra-long User Interaction History (UIH). However, the industry-standard "Fat Row" paradigm, which pre-materializes these sequences into every training example, creates a storage and I/O wall where data infrastructure usage exceeds GPU training capacity due to data redundancy that is amplified in multi-tenant environments where models with vastly different sequence length requirements share a union dataset. We present a \emph{versioned late materialization} paradigm that eliminates this redundancy by storing UIH once in a normalized, immutable tier and reconstructing sequences just-in-time during training via lightweight versioned pointers. The system ensures Online-to-Offline (O2O) consistency through a bifurcated protocol that prevents future leakage across both streaming and batch training, while a read-optimized immutable storage layer provides multi-dimensional projection pushdown for heterogeneous model tenants. Disaggregated data preprocessing with pipelined I/O prefetching and data-affinity optimizations masks the latency of training-time sequence reconstruction, keeping training throughput compute-bound by GPUs. Deployed on production DLRMs, the system reduces training data infrastructure resource usage while enabling aggressive sequence length scaling that delivers significant model quality gains, serving as the foundational data infrastructure for modern recommendation model architectures, including HSTU and ULTRA-HSTU.
EDU-Net: Retinal Pathological Fluid Segmentation in OCT Images with Multiscale Feature Fusion and Boundary Optimization
Apr 22, 2026Objective: Diabetic macular edema (DME) is the leading cause of severe visual impairment in patients with diabetes. Quantification of retinal fluid, particularly intraretinal fluid (IRF) and subretinal fluid (SRF), plays a critical role in the management of DME. Although optical coherence tomography (OCT) can be used for detection, the variable morphology of fluid accumulation and the blurred boundaries caused by noise interference still limit the accuracy of OCT's automatic segmentation. Methods: Retrospective model development and validation study. This study proposes a novel edge-guided dual-branch encoder-decoder network (EDU-Net) to achieve accurate and efficient automatic segmentation of OCT liquid lesions. The local feature extraction branch is based on the EfficientNet model, which precisely captures tiny lesions by leveraging its lightweight separable convolution and high-resolution feature preservation strategy. The global feature extraction branch is based on the large-kernel efficient convolution (LKEC) module and the downsampling layer design to enhance long-range dependencies and global semantics. EDU-Net applies a multi-category edge-guided attention module to fuse high-frequency boundary detail information to each resolution feature to optimize the boundary segmentation performance. Results: Extensive results on the in-house and public datasets demonstrate that EDU-Net achieves state-of-the-art DSC segmentation performance in terms of efficiency and robustness, especially in the segmentation of IRF lesions. Conclusions: EDU-Net integrates local details with global context and optimizes boundaries, achieving an improvement in the accuracy of automatic segmentation of retinal fluid.
Topology-Guided Biomechanical Profiling: A White-Box Framework for Opportunistic Screening of Spinal Instability on Routine CT
Mar 17, 2026Routine oncologic computed tomography (CT) presents an ideal opportunity for screening spinal instability, yet prophylactic stabilization windows are frequently missed due to the complex geometric reasoning required by the Spinal Instability Neoplastic Score (SINS). Automating SINS is fundamentally hindered by metastatic osteolysis, which induces topological ambiguity that confounds standard segmentation and black-box AI. We propose Topology-Guided Biomechanical Profiling (TGBP), an auditable white-box framework decoupling anatomical perception from structural reasoning. TGBP anchors SINS assessment on two deterministic geometric innovations: (i) canal-referenced partitioning to resolve posterolateral boundary ambiguity, and (ii) context-aware morphometric normalization via covariance-based oriented bounding boxes (OBB) to quantify vertebral collapse. Integrated with auxiliary radiomic and large language model (LLM) modules, TGBP provides an end-to-end, interpretable SINS evaluation. Validated on a multi-center, multi-cancer cohort ($N=482$), TGBP achieved 90.2\% accuracy in 3-tier stability triage. In a blinded reader study ($N=30$), TGBP significantly outperformed medical oncologists on complex structural features ($κ=0.857$ vs.\ $0.570$) and prevented compounding errors in Total Score estimation ($κ=0.625$ vs.\ $0.207$), democratizing expert-level opportunistic screening.
AutoFPDesigner: Automated Flight Procedure Design Based on Multi-Agent Large Language Model
Oct 19, 2024Current flight procedure design methods heavily rely on human-led design process, which is not only low auto-mation but also suffer from complex algorithm modelling and poor generalization. To address these challenges, this paper proposes an agent-driven flight procedure design method based on large language model, named Au-toFPDesigner, which utilizes multi-agent collaboration to complete procedure design. The method enables end-to-end automated design of performance-based navigation (PBN) procedures. In this process, the user input the design requirements in natural language, AutoFPDesigner models the flight procedure design by loading the design speci-fications and utilizing tool libraries complete the design. AutoFPDesigner allows users to oversee and seamlessly participate in the design process. Experimental results show that AutoFPDesigner ensures nearly 100% safety in the designed flight procedures and achieves 75% task completion rate, with good adaptability across different design tasks. AutoFPDesigner introduces a new paradigm for flight procedure design and represents a key step towards the automation of this process. Keywords: Flight Procedure Design; Large Language Model; Performance-Based Navigation (PBN); Multi Agent;
Annotation of Sleep Depth Index with Scalable Deep Learning Yields Novel Digital Biomarkers for Sleep Health
Jul 05, 2024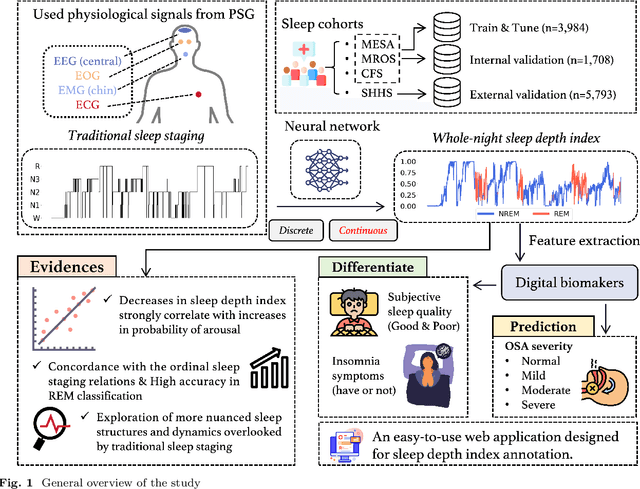

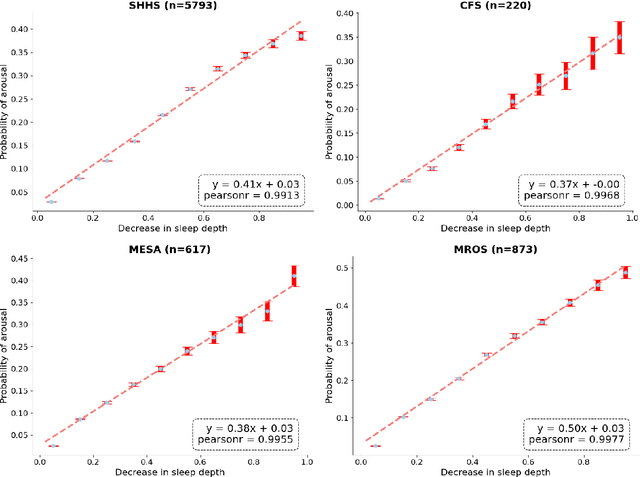
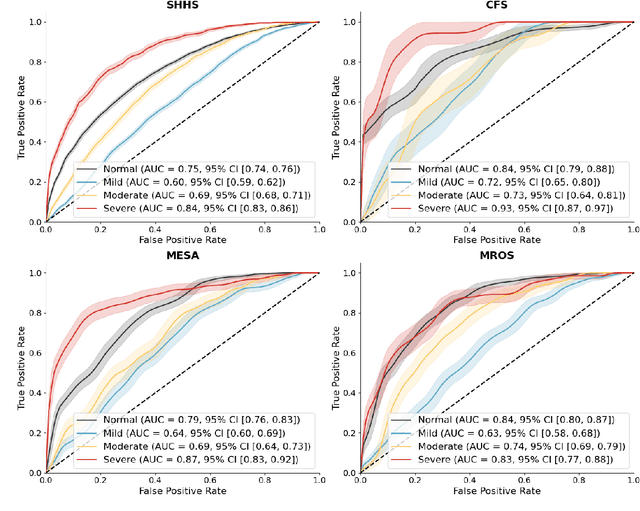
Traditional sleep staging categorizes sleep and wakefulness into five coarse-grained classes, overlooking subtle variations within each stage. It provides limited information about the probability of arousal and may hinder the diagnosis of sleep disorders, such as insomnia. To address this issue, we propose a deep-learning method for automatic and scalable annotation of sleep depth index using existing sleep staging labels. Our approach is validated using polysomnography from over ten thousand recordings across four large-scale cohorts. The results show a strong correlation between the decrease in sleep depth index and the increase in arousal likelihood. Several case studies indicate that the sleep depth index captures more nuanced sleep structures than conventional sleep staging. Sleep biomarkers extracted from the whole-night sleep depth index exhibit statistically significant differences with medium-to-large effect sizes across groups of varied subjective sleep quality and insomnia symptoms. These sleep biomarkers also promise utility in predicting the severity of obstructive sleep apnea, particularly in severe cases. Our study underscores the utility of the proposed method for continuous sleep depth annotation, which could reveal more detailed structures and dynamics within whole-night sleep and yield novel digital biomarkers beneficial for sleep health.
EMPL: A novel Efficient Meta Prompt Learning Framework for Few-shot Unsupervised Domain Adaptation
Jul 04, 2024



Few-shot unsupervised domain adaptation (FS-UDA) utilizes few-shot labeled source domain data to realize effective classification in unlabeled target domain. However, current FS-UDA methods are still suffer from two issues: 1) the data from different domains can not be effectively aligned by few-shot labeled data due to the large domain gaps, 2) it is unstable and time-consuming to generalize to new FS-UDA tasks.To address this issue, we put forward a novel Efficient Meta Prompt Learning Framework for FS-UDA. Within this framework, we use pre-trained CLIP model as the feature learning base model. First, we design domain-shared prompt learning vectors composed of virtual tokens, which mainly learns the meta knowledge from a large number of meta tasks to mitigate domain gaps. Secondly, we also design a task-shared prompt learning network to adaptively learn specific prompt vectors for each task, which aims to realize fast adaptation and task generalization. Thirdly, we learn a task-specific cross-domain alignment projection and a task-specific classifier with closed-form solutions for each meta task, which can efficiently adapt the model to new tasks in one step. The whole learning process is formulated as a bilevel optimization problem, and a good initialization of model parameters is learned through meta-learning. Extensive experimental study demonstrates the promising performance of our framework on benchmark datasets. Our method has the large improvement of at least 15.4% on 5-way 1-shot and 8.7% on 5-way 5-shot, compared with the state-of-the-art methods. Also, the performance of our method on all the test tasks is more stable than the other methods.
Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval
Jul 01, 2024



In this paper, we study the problem of zero-shot sketch-based image retrieval (ZS-SBIR). The prior methods tackle the problem in a two-modality setting with only category labels or even no textual information involved. However, the growing prevalence of Large-scale pre-trained Language Models (LLMs), which have demonstrated great knowledge learned from web-scale data, can provide us with an opportunity to conclude collective textual information. Our key innovation lies in the usage of text data as auxiliary information for images, thus leveraging the inherent zero-shot generalization ability that language offers. To this end, we propose an approach called Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval. The network consists of three components: (i) a Description Generation Module that generates textual descriptions for each training category by prompting an LLM with several interrogative sentences, (ii) a Feature Extraction Module that includes two ViTs for sketch and image data, a transformer for extracting tokens of sentences of each training category, finally (iii) a Cross-modal Alignment Module that exchanges the token features of both text-sketch and text-image using cross-attention mechanism, and align the tokens locally and globally. Extensive experiments on three benchmark datasets show our superior performances over the state-of-the-art ZS-SBIR methods.
Cross-target Stance Detection by Exploiting Target Analytical Perspectives
Jan 04, 2024



Cross-target stance detection (CTSD) is an important task, which infers the attitude of the destination target by utilizing annotated data derived from the source target. One important approach in CTSD is to extract domain-invariant features to bridge the knowledge gap between multiple targets. However, the analysis of informal and short text structure, and implicit expressions, complicate the extraction of domain-invariant knowledge. In this paper, we propose a Multi-Perspective Prompt-Tuning (MPPT) model for CTSD that uses the analysis perspective as a bridge to transfer knowledge. First, we develop a two-stage instruct-based chain-of-thought method (TsCoT) to elicit target analysis perspectives and provide natural language explanations (NLEs) from multiple viewpoints by formulating instructions based on large language model (LLM). Second, we propose a multi-perspective prompt-tuning framework (MultiPLN) to fuse the NLEs into the stance predictor. Extensive experiments results demonstrate the superiority of MPPT against the state-of-the-art baseline methods.