 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignVerse-2M: A Two-Million-Clip Pose-Native Universe of 55+ Sign Languages
May 06, 2026Existing large-scale sign language resources typically provide supervision only at the level of raw video-text alignment and are often produced in laboratory settings. While such resources are important for semantic understanding, they do not directly provide a unified interface for open-world recognition and translation, or for modern pose-driven sign language video generation frameworks: 1. RGB-based pretrained recognition models depend heavily on fixed backgrounds or clothing conditions during recording, and are less robust in open-world settings than style-agnostic pose-processing models. 2. Recent pose-guided image/video generation models mostly use a unified keypoint representation such as DWPose as their control interface. At present, the sign language field still lacks a data resource that can directly interface with this modern pose-native paradigm while also targeting real-world open scenarios. We present SignVerse-2M, a large-scale multilingual pose-native dataset for sign language pose modeling and evaluation. Built from publicly available multilingual sign language video resources, it applies DWPose in a unified preprocessing pipeline to convert raw videos into 2D pose sequences that can be used directly for modeling, resulting in a consolidated corpus of about two million clips covering more than 55 sign languages. Unlike many laboratory datasets, this resource preserves the recording conditions and speaker diversity of real-world videos while reducing appearance variation through a unified pose representation. Toward this goal, we further provide the data construction pipeline, task definitions, and a simple SignDW Transformer baseline, demonstrating the feasibility of this resource for multilingual pose-space modeling and its compatibility with modern pose-driven pipelines, while discussing the evaluation claims it can support as well as its current limitations.
MAB-DQA: Addressing Query Aspect Importance in Document Question Answering with Multi-Armed Bandits
Apr 10, 2026Document Question Answering (DQA) involves generating answers from a document based on a user's query, representing a key task in document understanding. This task requires interpreting visual layouts, which has prompted recent studies to adopt multimodal Retrieval-Augmented Generation (RAG) that processes page images for answer generation. However, in multimodal RAG, visual DQA struggles to utilize a large number of images effectively, as the retrieval stage often retains only a few candidate pages (e.g., Top-4), causing informative but less visually salient content to be overlooked in favor of common yet low-information pages. To address this issue, we propose a Multi-Armed Bandit-based DQA framework (MAB-DQA) to explicitly model the varying importance of multiple implicit aspects in a query. Specifically, MAB-DQA decomposes a query into aspect-aware subqueries and retrieves an aspect-specific candidate set for each. It treats each subquery as an arm and uses preliminary reasoning results from a small number of representative pages as reward signals to estimate aspect utility. Guided by an exploration-exploitation policy, MAB-DQA dynamically reallocates retrieval budgets toward high-value aspects. With the most informative pages and their correlations, MAB-DQA generates the expected results. On four benchmarks, MAB-DQA shows an average improvement of 5%-18% over the state-of-the-art method, consistently enhancing document understanding. Code at https://github.com/ElephantOH/MAB-DQA.
Expert-Choice Routing Enables Adaptive Computation in Diffusion Language Models
Apr 02, 2026Diffusion language models (DLMs) enable parallel, non-autoregressive text generation, yet existing DLM mixture-of-experts (MoE) models inherit token-choice (TC) routing from autoregressive systems, leading to load imbalance and rigid computation allocation. We show that expert-choice (EC) routing is a better fit for DLMs: it provides deterministic load balancing by design, yielding higher throughput and faster convergence than TC. Building on the property that EC capacity is externally controllable, we introduce timestep-dependent expert capacity, which varies expert allocation according to the denoising step. We find that allocating more capacity to low-mask-ratio steps consistently achieves the best performance under matched FLOPs, and provide a mechanistic explanation: tokens in low-mask-ratio contexts exhibit an order-of-magnitude higher learning efficiency, so concentrating compute on these steps yields the largest marginal return. Finally, we show that existing pretrained TC DLMs can be retrofitted to EC by replacing only the router, achieving faster convergence and improved accuracy across diverse downstream tasks. Together, these results establish EC routing as a superior paradigm for DLM MoE models and demonstrate that computation in DLMs can be treated as an adaptive policy rather than a fixed architectural constant. Code is available at https://github.com/zhangshuibai/EC-DLM.
HabitatAgent: An End-to-End Multi-Agent System for Housing Consultation
Apr 01, 2026Housing selection is a high-stakes and largely irreversible decision problem. We study housing consultation as a decision-support interface for housing selection. Existing housing platforms and many LLM-based assistants often reduce this process to ranking or recommendation, resulting in opaque reasoning, brittle multi-constraint handling, and limited guarantees on factuality. We present HabitatAgent, the first LLM-powered multi-agent architecture for end-to-end housing consultation. HabitatAgent comprises four specialized agent roles: Memory, Retrieval, Generation, and Validation. The Memory Agent maintains multi-layer user memory through internal stages for constraint extraction, memory fusion, and verification-gated updates; the Retrieval Agent performs hybrid vector--graph retrieval (GraphRAG); the Generation Agent produces evidence-referenced recommendations and explanations; and the Validation Agent applies multi-tier verification and targeted remediation. Together, these agents provide an auditable and reliable workflow for end-to-end housing consultation. We evaluate HabitatAgent on 100 real user consultation scenarios (300 multi-turn question--answer pairs) under an end-to-end correctness protocol. A strong single-stage baseline (Dense+Rerank) achieves 75% accuracy, while HabitatAgent reaches 95%.
Lingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models
Jan 30, 2026Robust safety of vision-language large models (VLLMs) under joint multilingual and multimodal inputs remains underexplored. Existing benchmarks are typically multilingual but text-only, or multimodal but monolingual. Recent multilingual multimodal red-teaming efforts render harmful prompts into images, yet rely heavily on typography-style visuals and lack semantically grounded image-text pairs, limiting coverage of realistic cross-modal interactions. We introduce Lingua-SafetyBench, a benchmark of 100,440 harmful image-text pairs across 10 languages, explicitly partitioned into image-dominant and text-dominant subsets to disentangle risk sources. Evaluating 11 open-source VLLMs reveals a consistent asymmetry: image-dominant risks yield higher ASR in high-resource languages, while text-dominant risks are more severe in non-high-resource languages. A controlled study on the Qwen series shows that scaling and version upgrades reduce Attack Success Rate (ASR) overall but disproportionately benefit HRLs, widening the gap between HRLs and Non-HRLs under text-dominant risks. This underscores the necessity of language- and modality-aware safety alignment beyond mere scaling.To facilitate reproducibility and future research, we will publicly release our benchmark, model checkpoints, and source code.The code and dataset will be available at https://github.com/zsxr15/Lingua-SafetyBench.Warning: this paper contains examples with unsafe content.
DMAP: Human-Aligned Structural Document Map for Multimodal Document Understanding
Jan 27, 2026Existing multimodal document question-answering (QA) systems predominantly rely on flat semantic retrieval, representing documents as a set of disconnected text chunks and largely neglecting their intrinsic hierarchical and relational structures. Such flattening disrupts logical and spatial dependencies - such as section organization, figure-text correspondence, and cross-reference relations, that humans naturally exploit for comprehension. To address this limitation, we introduce a document-level structural Document MAP (DMAP), which explicitly encodes both hierarchical organization and inter-element relationships within multimodal documents. Specifically, we design a Structured-Semantic Understanding Agent to construct DMAP by organizing textual content together with figures, tables, charts, etc. into a human-aligned hierarchical schema that captures both semantic and layout dependencies. Building upon this representation, a Reflective Reasoning Agent performs structure-aware and evidence-driven reasoning, dynamically assessing the sufficiency of retrieved context and iteratively refining answers through targeted interactions with DMAP. Extensive experiments on MMDocQA benchmarks demonstrate that DMAP yields document-specific structural representations aligned with human interpretive patterns, substantially enhancing retrieval precision, reasoning consistency, and multimodal comprehension over conventional RAG-based approaches. Code is available at https://github.com/Forlorin/DMAP
Frozen LVLMs for Micro-Video Recommendation: A Systematic Study of Feature Extraction and Fusion
Dec 26, 2025Frozen Large Video Language Models (LVLMs) are increasingly employed in micro-video recommendation due to their strong multimodal understanding. However, their integration lacks systematic empirical evaluation: practitioners typically deploy LVLMs as fixed black-box feature extractors without systematically comparing alternative representation strategies. To address this gap, we present the first systematic empirical study along two key design dimensions: (i) integration strategies with ID embeddings, specifically replacement versus fusion, and (ii) feature extraction paradigms, comparing LVLM-generated captions with intermediate decoder hidden states. Extensive experiments on representative LVLMs reveal three key principles: (1) intermediate hidden states consistently outperform caption-based representations, as natural-language summarization inevitably discards fine-grained visual semantics crucial for recommendation; (2) ID embeddings capture irreplaceable collaborative signals, rendering fusion strictly superior to replacement; and (3) the effectiveness of intermediate decoder features varies significantly across layers. Guided by these insights, we propose the Dual Feature Fusion (DFF) Framework, a lightweight and plug-and-play approach that adaptively fuses multi-layer representations from frozen LVLMs with item ID embeddings. DFF achieves state-of-the-art performance on two real-world micro-video recommendation benchmarks, consistently outperforming strong baselines and providing a principled approach to integrating off-the-shelf large vision-language models into micro-video recommender systems.
NeuroScalar: A Deep Learning Framework for Fast, Accurate, and In-the-Wild Cycle-Level Performance Prediction
Sep 26, 2025



The evaluation of new microprocessor designs is constrained by slow, cycle-accurate simulators that rely on unrepresentative benchmark traces. This paper introduces a novel deep learning framework for high-fidelity, ``in-the-wild'' simulation on production hardware. Our core contribution is a DL model trained on microarchitecture-independent features to predict cycle-level performance for hypothetical processor designs. This unique approach allows the model to be deployed on existing silicon to evaluate future hardware. We propose a complete system featuring a lightweight hardware trace collector and a principled sampling strategy to minimize user impact. This system achieves a simulation speed of 5 MIPS on a commodity GPU, imposing a mere 0.1% performance overhead. Furthermore, our co-designed Neutrino on-chip accelerator improves performance by 85x over the GPU. We demonstrate that this framework enables accurate performance analysis and large-scale hardware A/B testing on a massive scale using real-world applications.
AutoFPDesigner: Automated Flight Procedure Design Based on Multi-Agent Large Language Model
Oct 19, 2024Current flight procedure design methods heavily rely on human-led design process, which is not only low auto-mation but also suffer from complex algorithm modelling and poor generalization. To address these challenges, this paper proposes an agent-driven flight procedure design method based on large language model, named Au-toFPDesigner, which utilizes multi-agent collaboration to complete procedure design. The method enables end-to-end automated design of performance-based navigation (PBN) procedures. In this process, the user input the design requirements in natural language, AutoFPDesigner models the flight procedure design by loading the design speci-fications and utilizing tool libraries complete the design. AutoFPDesigner allows users to oversee and seamlessly participate in the design process. Experimental results show that AutoFPDesigner ensures nearly 100% safety in the designed flight procedures and achieves 75% task completion rate, with good adaptability across different design tasks. AutoFPDesigner introduces a new paradigm for flight procedure design and represents a key step towards the automation of this process. Keywords: Flight Procedure Design; Large Language Model; Performance-Based Navigation (PBN); Multi Agent;
Reinforcement Learning from Demonstrations by Novel Interactive Expert and Application to Automatic Berthing Control Systems for Unmanned Surface Vessel
Feb 23, 2022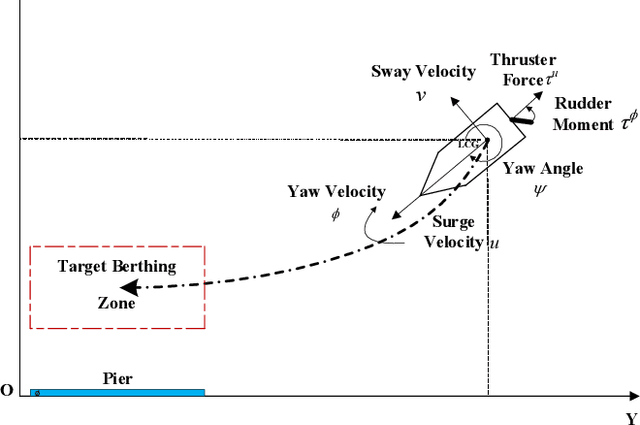
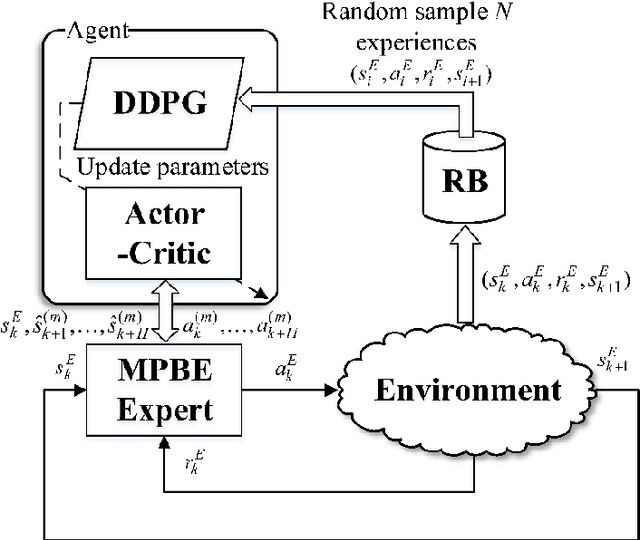
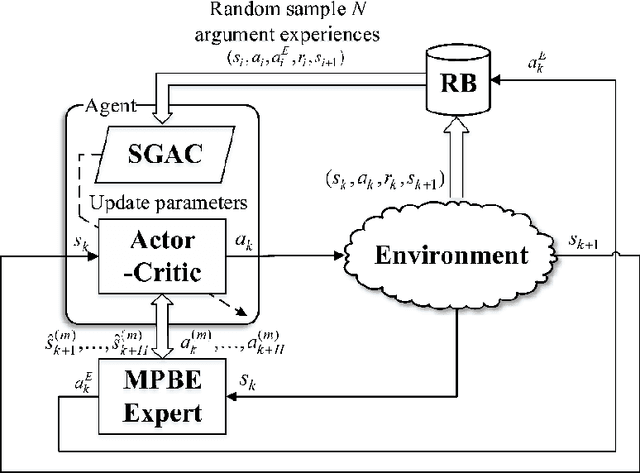
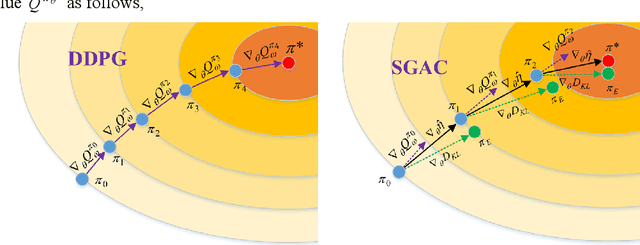
In this paper, two novel practical methods of Reinforcement Learning from Demonstration (RLfD) are developed and applied to automatic berthing control systems for Unmanned Surface Vessel. A new expert data generation method, called Model Predictive Based Expert (MPBE) which combines Model Predictive Control and Deep Deterministic Policy Gradient, is developed to provide high quality supervision data for RLfD algorithms. A straightforward RLfD method, model predictive Deep Deterministic Policy Gradient (MP-DDPG), is firstly introduced by replacing the RL agent with MPBE to directly interact with the environment. Then distribution mismatch problem is analyzed for MP-DDPG, and two techniques that alleviate distribution mismatch are proposed. Furthermore, another novel RLfD algorithm based on the MP-DDPG, called Self-Guided Actor-Critic (SGAC) is present, which can effectively leverage MPBE by continuously querying it to generate high quality expert data online. The distribution mismatch problem leading to unstable learning process is addressed by SGAC in a DAgger manner. In addition, theoretical analysis is given to prove that SGAC algorithm can converge with guaranteed monotonic improvement. Simulation results verify the effectiveness of MP-DDPG and SGAC to accomplish the ship berthing control task, and show advantages of SGAC comparing with other typical reinforcement learning algorithms and MP-DDPG.