 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of LLMs in Time Series Forecasting
Feb 16, 2026Large language models (LLMs) have been introduced to time series forecasting (TSF) to incorporate contextual knowledge beyond numerical signals. However, existing studies question whether LLMs provide genuine benefits, often reporting comparable performance without LLMs. We show that such conclusions stem from limited evaluation settings and do not hold at scale. We conduct a large-scale study of LLM-based TSF (LLM4TSF) across 8 billion observations, 17 forecasting scenarios, 4 horizons, multiple alignment strategies, and both in-domain and out-of-domain settings. Our results demonstrate that \emph{LLM4TS indeed improves forecasting performance}, with especially large gains in cross-domain generalization. Pre-alignment outperforming post-alignment in over 90\% of tasks. Both pretrained knowledge and model architecture of LLMs contribute and play complementary roles: pretraining is critical under distribution shifts, while architecture excels at modeling complex temporal dynamics. Moreover, under large-scale mixed distributions, a fully intact LLM becomes indispensable, as confirmed by token-level routing analysis and prompt-based improvements. Overall, Our findings overturn prior negative assessments, establish clear conditions under which LLMs are not only useful, and provide practical guidance for effective model design. We release our code at https://github.com/EIT-NLP/LLM4TSF.
ViCA: Efficient Multimodal LLMs with Vision-Only Cross-Attention
Feb 07, 2026Modern multimodal large language models (MLLMs) adopt a unified self-attention design that processes visual and textual tokens at every Transformer layer, incurring substantial computational overhead. In this work, we revisit the necessity of such dense visual processing and show that projected visual embeddings are already well-aligned with the language space, while effective vision-language interaction occurs in only a small subset of layers. Based on these insights, we propose ViCA (Vision-only Cross-Attention), a minimal MLLM architecture in which visual tokens bypass all self-attention and feed-forward layers, interacting with text solely through sparse cross-attention at selected layers. Extensive evaluations across three MLLM backbones, nine multimodal benchmarks, and 26 pruning-based baselines show that ViCA preserves 98% of baseline accuracy while reducing visual-side computation to 4%, consistently achieving superior performance-efficiency trade-offs. Moreover, ViCA provides a regular, hardware-friendly inference pipeline that yields over 3.5x speedup in single-batch inference and over 10x speedup in multi-batch inference, reducing visual grounding to near-zero overhead compared with text-only LLMs. It is also orthogonal to token pruning methods and can be seamlessly combined for further efficiency gains. Our code is available at https://github.com/EIT-NLP/ViCA.
Quantized Evolution Strategies: High-precision Fine-tuning of Quantized LLMs at Low-precision Cost
Feb 03, 2026Post-Training Quantization (PTQ) is essential for deploying Large Language Models (LLMs) on memory-constrained devices, yet it renders models static and difficult to fine-tune. Standard fine-tuning paradigms, including Reinforcement Learning (RL), fundamentally rely on backpropagation and high-precision weights to compute gradients. Thus they cannot be used on quantized models, where the parameter space is discrete and non-differentiable. While Evolution Strategies (ES) offer a backpropagation-free alternative, optimization of the quantized parameters can still fail due to vanishing or inaccurate gradient. This paper introduces Quantized Evolution Strategies (QES), an optimization paradigm that performs full-parameter fine-tuning directly in the quantized space. QES is based on two innovations: (1) it integrates accumulated error feedback to preserve high-precision gradient signals, and (2) it utilizes a stateless seed replay to reduce memory usage to low-precision inference levels. QES significantly outperforms the state-of-the-art zeroth-order fine-tuning method on arithmetic reasoning tasks, making direct fine-tuning for quantized models possible. It therefore opens up the possibility for scaling up LLMs entirely in the quantized space. The source code is available at https://github.com/dibbla/Quantized-Evolution-Strategies .
Fine-Tuning Language Models to Know What They Know
Feb 02, 2026Metacognition is a critical component of intelligence, specifically regarding the awareness of one's own knowledge. While humans rely on shared internal memory for both answering questions and reporting their knowledge state, this dependency in LLMs remains underexplored. This study proposes a framework to measure metacognitive ability $d_{\rm{type2}}'$ using a dual-prompt method, followed by the introduction of Evolution Strategy for Metacognitive Alignment (ESMA) to bind a model's internal knowledge to its explicit behaviors. ESMA demonstrates robust generalization across diverse untrained settings, indicating a enhancement in the model's ability to reference its own knowledge. Furthermore, parameter analysis attributes these improvements to a sparse set of significant modifications.
The Blessing of Dimensionality in LLM Fine-tuning: A Variance-Curvature Perspective
Jan 30, 2026Weight-perturbation evolution strategies (ES) can fine-tune billion-parameter language models with surprisingly small populations (e.g., $N\!\approx\!30$), contradicting classical zeroth-order curse-of-dimensionality intuition. We also observe a second seemingly separate phenomenon: under fixed hyperparameters, the stochastic fine-tuning reward often rises, peaks, and then degrades in both ES and GRPO. We argue that both effects reflect a shared geometric property of fine-tuning landscapes: they are low-dimensional in curvature. A small set of high-curvature dimensions dominates improvement, producing (i) heterogeneous time scales that yield rise-then-decay under fixed stochasticity, as captured by a minimal quadratic stochastic-ascent model, and (ii) degenerate improving updates, where many random perturbations share similar components along these directions. Using ES as a geometric probe on fine-tuning reward landscapes of GSM8K, ARC-C, and WinoGrande across Qwen2.5-Instruct models (0.5B--7B), we show that reward-improving perturbations remain empirically accessible with small populations across scales. Together, these results reconcile ES scalability with non-monotonic training dynamics and suggest that high-dimensional fine-tuning may admit a broader class of viable optimization methods than worst-case theory implies.
SonicBench: Dissecting the Physical Perception Bottleneck in Large Audio Language Models
Jan 16, 2026Large Audio Language Models (LALMs) excel at semantic and paralinguistic tasks, yet their ability to perceive the fundamental physical attributes of audio such as pitch, loudness, and spatial location remains under-explored. To bridge this gap, we introduce SonicBench, a psychophysically grounded benchmark that systematically evaluates 12 core physical attributes across five perceptual dimensions. Unlike previous datasets, SonicBench uses a controllable generation toolbox to construct stimuli for two complementary paradigms: recognition (absolute judgment) and comparison (relative judgment). This design allows us to probe not only sensory precision but also relational reasoning capabilities, a domain where humans typically exhibit greater proficiency. Our evaluation reveals a substantial deficiency in LALMs' foundational auditory understanding; most models perform near random guessing and, contrary to human patterns, fail to show the expected advantage on comparison tasks. Furthermore, explicit reasoning yields minimal gains. However, our linear probing analysis demonstrates crucially that frozen audio encoders do successfully capture these physical cues (accuracy at least 60%), suggesting that the primary bottleneck lies in the alignment and decoding stages, where models fail to leverage the sensory signals they have already captured.
Solving a Million-Step LLM Task with Zero Errors
Nov 12, 2025LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations, and societies has remained out of reach. The models have a persistent error rate that prevents scale-up: for instance, recent experiments in the Towers of Hanoi benchmark domain showed that the process inevitably becomes derailed after at most a few hundred steps. Thus, although LLM research is often still benchmarked on tasks with relatively few dependent logical steps, there is increasing attention on the ability (or inability) of LLMs to perform long range tasks. This paper describes MAKER, the first system that successfully solves a task with over one million LLM steps with zero errors, and, in principle, scales far beyond this level. The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents. The high level of modularity resulting from the decomposition allows error correction to be applied at each step through an efficient multi-agent voting scheme. This combination of extreme decomposition and error correction makes scaling possible. Thus, the results suggest that instead of relying on continual improvement of current LLMs, massively decomposed agentic processes (MDAPs) may provide a way to efficiently solve problems at the level of organizations and societies.
The Few Govern the Many:Unveiling Few-Layer Dominance for Time Series Models
Nov 10, 2025Large-scale models are at the forefront of time series (TS) forecasting, dominated by two paradigms: fine-tuning text-based Large Language Models (LLM4TS) and training Time Series Foundation Models (TSFMs) from scratch. Both approaches share a foundational assumption that scaling up model capacity and data volume leads to improved performance. However, we observe a \textit{\textbf{scaling paradox}} in TS models, revealing a puzzling phenomenon that larger models do \emph{NOT} achieve better performance. Through extensive experiments on two model families across four scales (100M to 1.7B parameters) and diverse data (up to 6B observations), we rigorously confirm that the scaling paradox is a pervasive issue. We then diagnose its root cause by analyzing internal representations, identifying a phenomenon we call \textit{few-layer dominance}: only a small subset of layers are functionally important, while the majority are redundant, under-utilized, and can even distract training. Based on this discovery, we propose a practical method to automatically identify and retain only these dominant layers. In our models, retaining only 21\% of the parameters achieves up to a 12\% accuracy improvement and a 2.7$\times$ inference speedup. We validate the universality of our method on 8 prominent SOTA models (LLM4TS and TSFMs, 90M to 6B), showing that retaining less than 30\% of layers achieves comparable or superior accuracy in over 95\% of tasks.
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025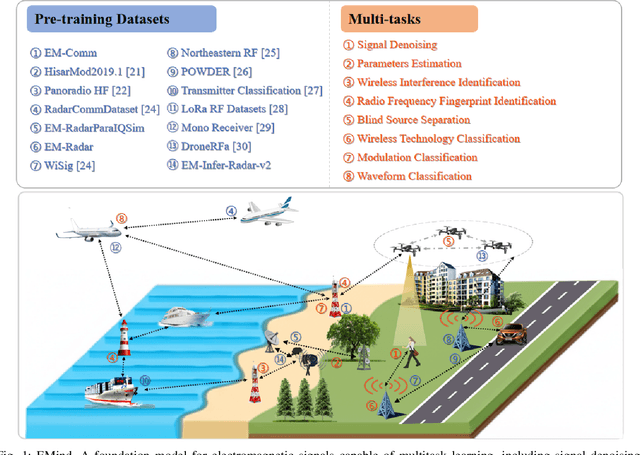
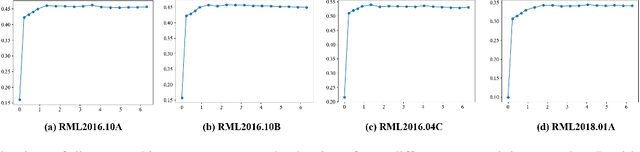
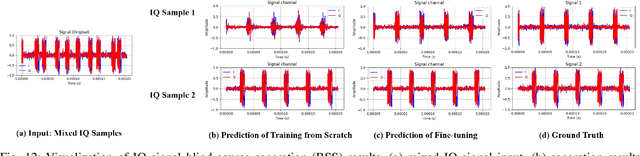
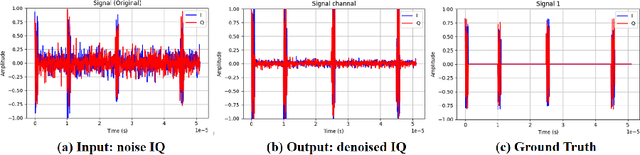
Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
RIS-MAE: A Self-Supervised Modulation Classification Method Based on Raw IQ Signals and Masked Autoencoder
Aug 01, 2025Automatic modulation classification (AMC) is a basic technology in intelligent wireless communication systems. It is important for tasks such as spectrum monitoring, cognitive radio, and secure communications. In recent years, deep learning methods have made great progress in AMC. However, mainstream methods still face two key problems. First, they often use time-frequency images instead of raw signals. This causes loss of key modulation features and reduces adaptability to different communication conditions. Second, most methods rely on supervised learning. This needs a large amount of labeled data, which is hard to get in real-world environments. To solve these problems, we propose a self-supervised learning framework called RIS-MAE. RIS-MAE uses masked autoencoders to learn signal features from unlabeled data. It takes raw IQ sequences as input. By applying random masking and reconstruction, it captures important time-domain features such as amplitude, phase, etc. This helps the model learn useful and transferable representations. RIS-MAE is tested on four datasets. The results show that it performs better than existing methods in few-shot and cross-domain tasks. Notably, it achieves high classification accuracy on previously unseen datasets with only a small number of fine-tuning samples, confirming its generalization ability and potential for real-world deployment.