 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving GAN Formulations for Higher Quality Image Synthesis
Feb 17, 2021

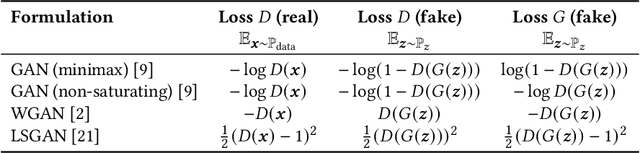
Generative Adversarial Networks (GANs) have extended deep learning to complex generation and translation tasks across different data modalities. However, GANs are notoriously difficult to train: Mode collapse and other instabilities in the training process often degrade the quality of the generated results, such as images. This paper presents a new technique called TaylorGAN for improving GANs by discovering customized loss functions for each of its two networks. The loss functions are parameterized as Taylor expansions and optimized through multiobjective evolution. On an image-to-image translation benchmark task, this approach qualitatively improves generated image quality and quantitatively improves two independent GAN performance metrics. It therefore forms a promising approach for applying GANs to more challenging tasks in the future.
Effective Regularization Through Loss-Function Metalearning
Oct 02, 2020
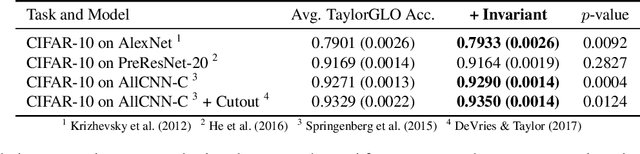
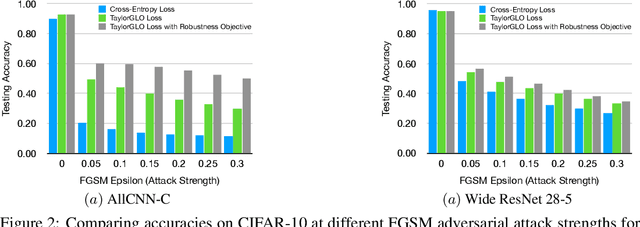
Loss-function metalearning can be used to discover novel, customized loss functions for deep neural networks, resulting in improved performance, faster training, and improved data utilization. A likely explanation is that such functions discourage overfitting, leading to effective regularization. This paper theoretically demonstrates that this is indeed the case: decomposition of learning rules makes it possible to characterize the training dynamics and show that loss functions evolved through TaylorGLO regularize both in the beginning and end of learning, and maintain an invariant in between. The invariant can be utilized to make the metalearning process more efficient in practice, and the regularization can train networks that are robust against adversarial attacks. Loss-function optimization can thus be seen as a well-founded new aspect of metalearning in neural networks.
Effective Reinforcement Learning through Evolutionary Surrogate-Assisted Prescription
Feb 13, 2020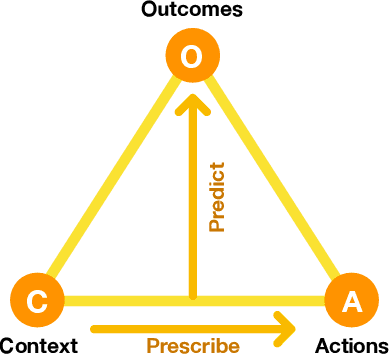
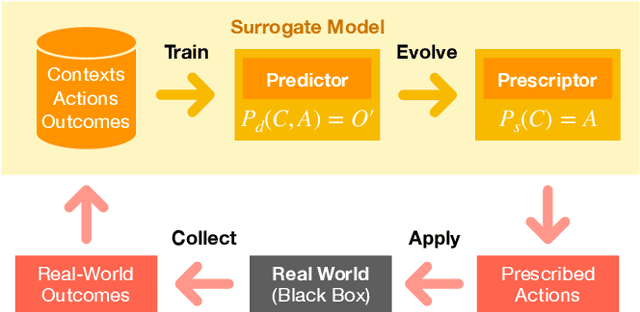

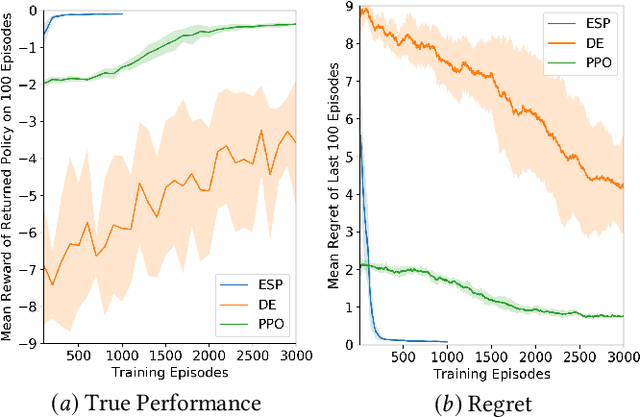
There is now significant historical data available on decision making in organizations, consisting of the decision problem, what decisions were made, and how desirable the outcomes were. Using this data, it is possible to learn a surrogate model, and with that model, evolve a decision strategy that optimizes the outcomes. This paper introduces a general such approach, called Evolutionary Surrogate-Assisted Prescription, or ESP. The surrogate is, for example, a random forest or a neural network trained with gradient descent, and the strategy is a neural network that is evolved to maximize the predictions of the surrogate model. ESP is further extended in this paper to sequential decision-making tasks, which makes it possible to evaluate the framework in reinforcement learning (RL) benchmarks. Because the majority of evaluations are done on the surrogate, ESP is more sample efficient, has lower variance, and lower regret than standard RL approaches. Surprisingly, its solutions are also better because both the surrogate and the strategy network regularize the decision-making behavior. ESP thus forms a promising foundation to decision optimization in real-world problems.
Population-Based Training for Loss Function Optimization
Feb 11, 2020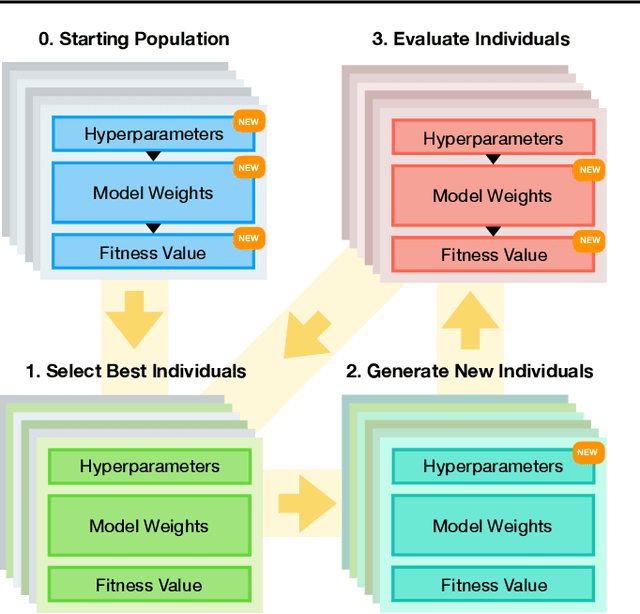

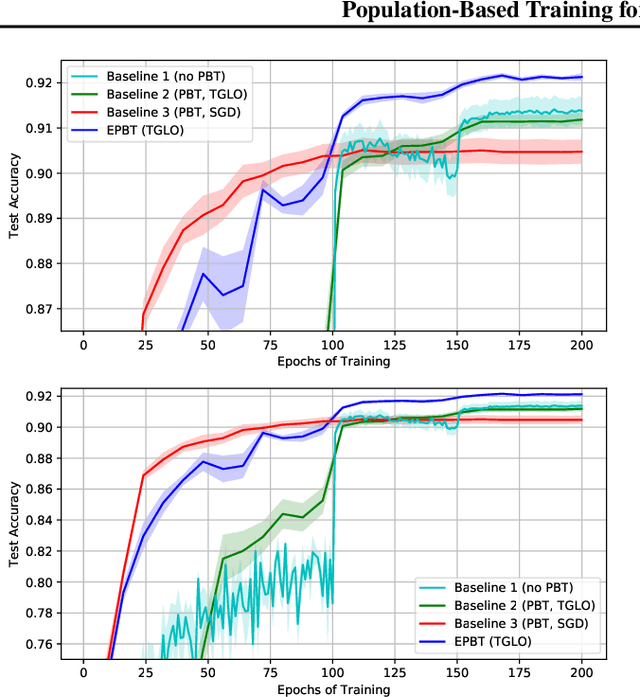

Metalearning of deep neural network (DNN) architectures and hyperparameters has become an increasingly important area of research. Loss functions are a type of metaknowledge that is crucial to effective training of DNNs and their potential role in metalearning has not yet been fully explored. This paper presents an algorithm called Enhanced Population-Based Training (EPBT) that interleaves the training of a DNN's weights with the metalearning of optimal hyperparameters and loss functions. Loss functions use a TaylorGLO parameterization, based on multivariate Taylor expansions, that EPBT can directly optimize. On the CIFAR-10 and SVHN image classification benchmarks, EPBT discovers loss function schedules that enable faster, more accurate learning. The discovered functions adapt to the training process and serve to regularize the learning task by discouraging overfitting to the labels. EPBT thus demonstrates a promising synergy of simultaneous training and metalearning.
Evolving Loss Functions with Multivariate Taylor Polynomial Parameterizations
Feb 10, 2020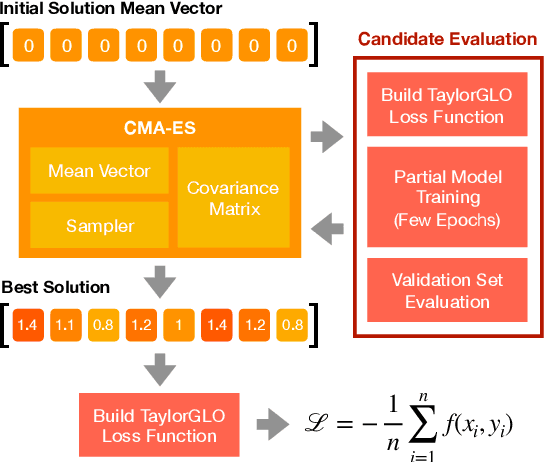
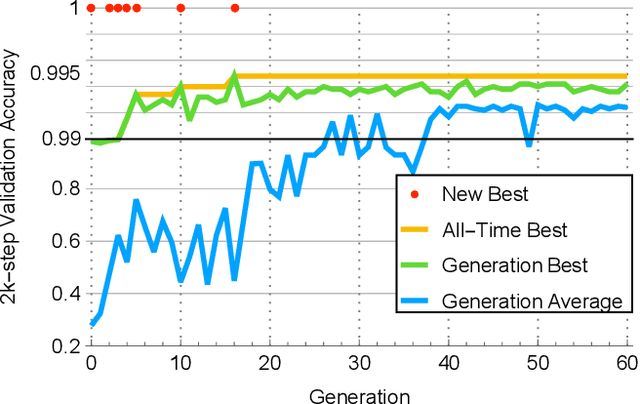
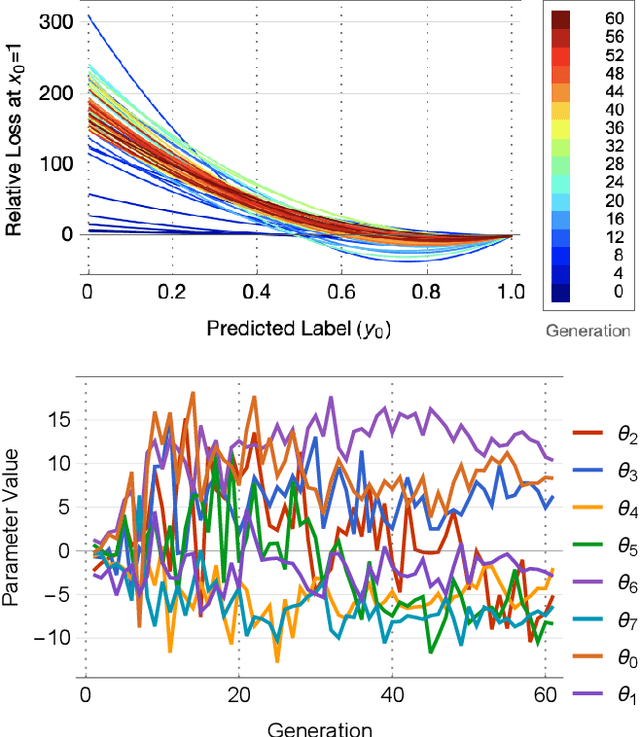
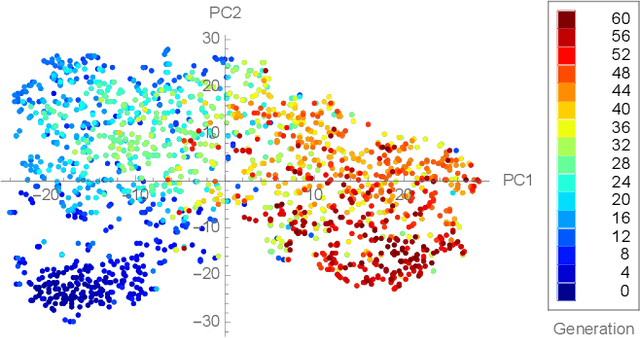
Loss function optimization for neural networks has recently emerged as a new direction for metalearning, with Genetic Loss Optimization (GLO) providing a general approach for the discovery and optimization of such functions. GLO represents loss functions as trees that are evolved and further optimized using evolutionary strategies. However, searching in this space is difficult because most candidates are not valid loss functions. In this paper, a new technique, Multivariate Taylor expansion-based genetic loss-function optimization (TaylorGLO), is introduced to solve this problem. It represents functions using a novel parameterization based on Taylor expansions, making the search more effective. TaylorGLO is able to find new loss functions that outperform those found by GLO in many fewer generations, demonstrating that loss function optimization is a productive avenue for metalearning.
Improved Training Speed, Accuracy, and Data Utilization Through Loss Function Optimization
May 27, 2019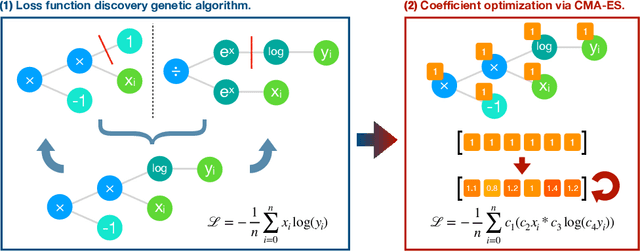

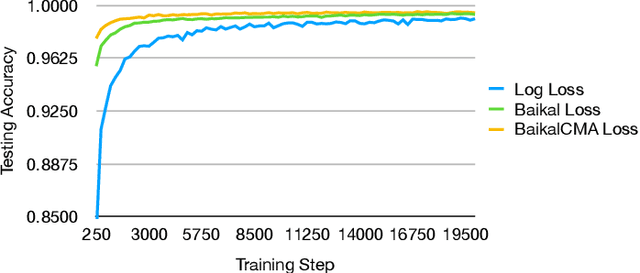
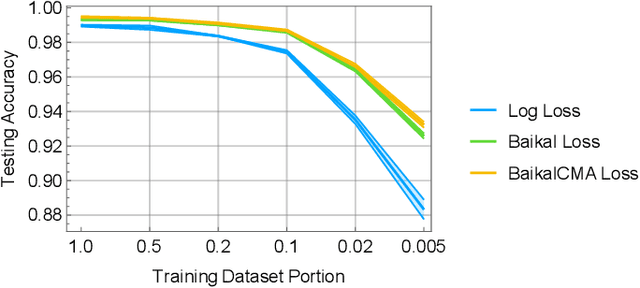
As the complexity of neural network models has grown, it has become increasingly important to optimize their design automatically through metalearning. Methods for discovering hyperparameters, topologies, and learning rate schedules have lead to significant increases in performance. This paper shows that loss functions can be optimized with metalearning as well, and result in similar improvements. The method, Genetic Loss-function Optimization (GLO), discovers loss functions de novo, and optimizes them for a target task. Leveraging techniques from genetic programming, GLO builds loss functions hierarchically from a set of operators and leaf nodes. These functions are repeatedly recombined and mutated to find an optimal structure, and then a covariance-matrix adaptation evolutionary strategy (CMA-ES) is used to find optimal coefficients. Networks trained with GLO loss functions are found to outperform the standard cross-entropy loss on standard image classification tasks. Training with these new loss functions requires fewer steps, results in lower test error, and allows for smaller datasets to be used. Loss-function optimization thus provides a new dimension of metalearning, and constitutes an important step towards AutoML.