 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Analysis of True Crime Podcasts With Knowledge Graph-Augmented Large Language Models
Nov 01, 2024
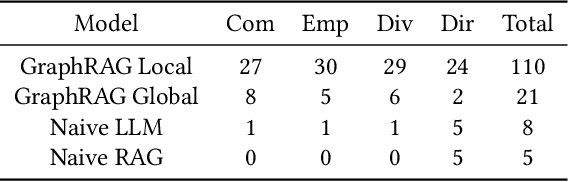

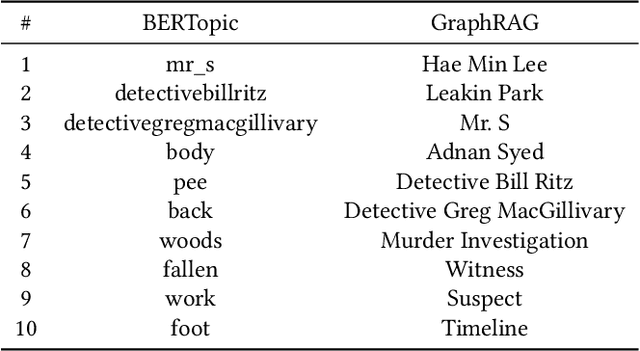
Narrative data spans all disciplines and provides a coherent model of the world to the reader or viewer. Recent advancement in machine learning and Large Language Models (LLMs) have enable great strides in analyzing natural language. However, Large language models (LLMs) still struggle with complex narrative arcs as well as narratives containing conflicting information. Recent work indicates LLMs augmented with external knowledge bases can improve the accuracy and interpretability of the resulting models. In this work, we analyze the effectiveness of applying knowledge graphs (KGs) in understanding true-crime podcast data from both classical Natural Language Processing (NLP) and LLM approaches. We directly compare KG-augmented LLMs (KGLLMs) with classical methods for KG construction, topic modeling, and sentiment analysis. Additionally, the KGLLM allows us to query the knowledge base in natural language and test its ability to factually answer questions. We examine the robustness of the model to adversarial prompting in order to test the model's ability to deal with conflicting information. Finally, we apply classical methods to understand more subtle aspects of the text such as the use of hearsay and sentiment in narrative construction and propose future directions. Our results indicate that KGLLMs outperform LLMs on a variety of metrics, are more robust to adversarial prompts, and are more capable of summarizing the text into topics.
Asynchronous Evolution of Deep Neural Network Architectures
Aug 08, 2023



Many evolutionary algorithms (EAs) take advantage of parallel evaluation of candidates. However, if evaluation times vary significantly, many worker nodes (i.e.,\ compute clients) are idle much of the time, waiting for the next generation to be created. Evolutionary neural architecture search (ENAS), a class of EAs that optimizes the architecture and hyperparameters of deep neural networks, is particularly vulnerable to this issue. This paper proposes a generic asynchronous evaluation strategy (AES) that is then adapted to work with ENAS. AES increases throughput by maintaining a queue of upto $K$ individuals ready to be sent to the workers for evaluation and proceeding to the next generation as soon as $M<<K$ individuals have been evaluated by the workers. A suitable value for $M$ is determined experimentally, balancing diversity and efficiency. To showcase the generality and power of AES, it was first evaluated in 11-bit multiplexer design (a single-population verifiable discovery task) and then scaled up to ENAS for image captioning (a multi-population open-ended-optimization task). In both problems, a multifold performance improvement was observed, suggesting that AES is a promising method for parallelizing the evolution of complex systems with long and variable evaluation times, such as those in ENAS.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022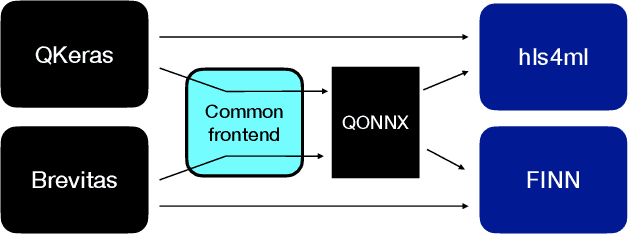
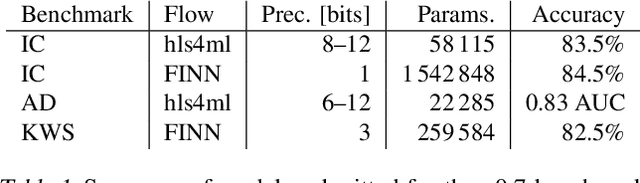
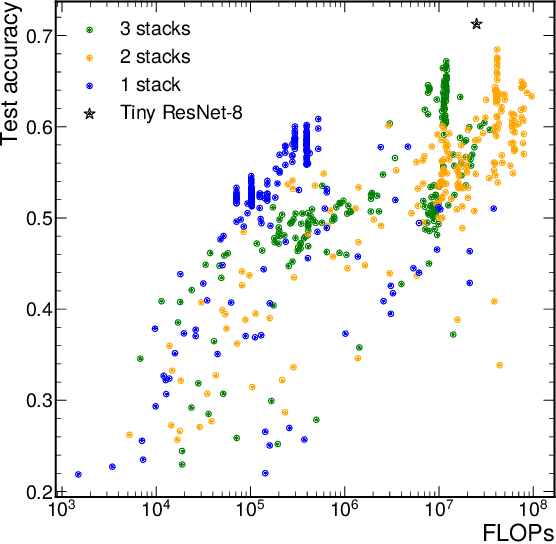
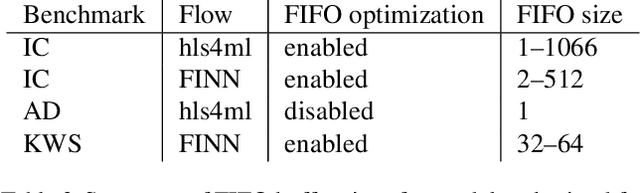
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
Designing Counterfactual Generators using Deep Model Inversion
Oct 05, 2021
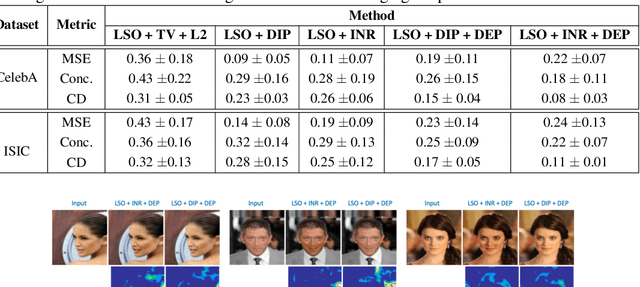
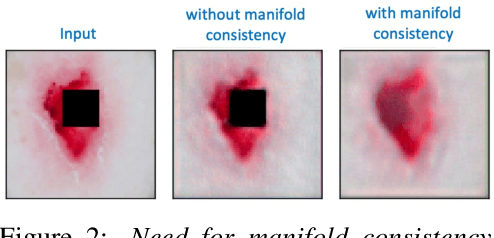

Explanation techniques that synthesize small, interpretable changes to a given image while producing desired changes in the model prediction have become popular for introspecting black-box models. Commonly referred to as counterfactuals, the synthesized explanations are required to contain discernible changes (for easy interpretability) while also being realistic (consistency to the data manifold). In this paper, we focus on the case where we have access only to the trained deep classifier and not the actual training data. While the problem of inverting deep models to synthesize images from the training distribution has been explored, our goal is to develop a deep inversion approach to generate counterfactual explanations for a given query image. Despite their effectiveness in conditional image synthesis, we show that existing deep inversion methods are insufficient for producing meaningful counterfactuals. We propose DISC (Deep Inversion for Synthesizing Counterfactuals) that improves upon deep inversion by utilizing (a) stronger image priors, (b) incorporating a novel manifold consistency objective and (c) adopting a progressive optimization strategy. We find that, in addition to producing visually meaningful explanations, the counterfactuals from DISC are effective at learning classifier decision boundaries and are robust to unknown test-time corruptions.
Training Stacked Denoising Autoencoders for Representation Learning
Feb 16, 2021



We implement stacked denoising autoencoders, a class of neural networks that are capable of learning powerful representations of high dimensional data. We describe stochastic gradient descent for unsupervised training of autoencoders, as well as a novel genetic algorithm based approach that makes use of gradient information. We analyze the performance of both optimization algorithms and also the representation learning ability of the autoencoder when it is trained on standard image classification datasets.
Population-Based Training for Loss Function Optimization
Feb 11, 2020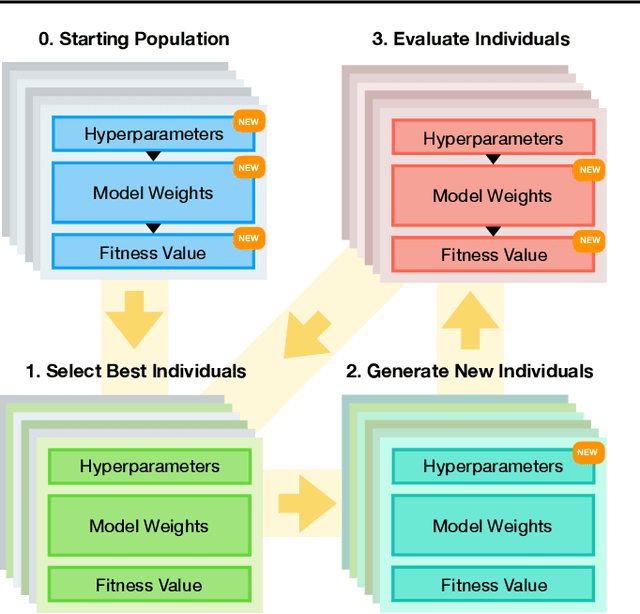

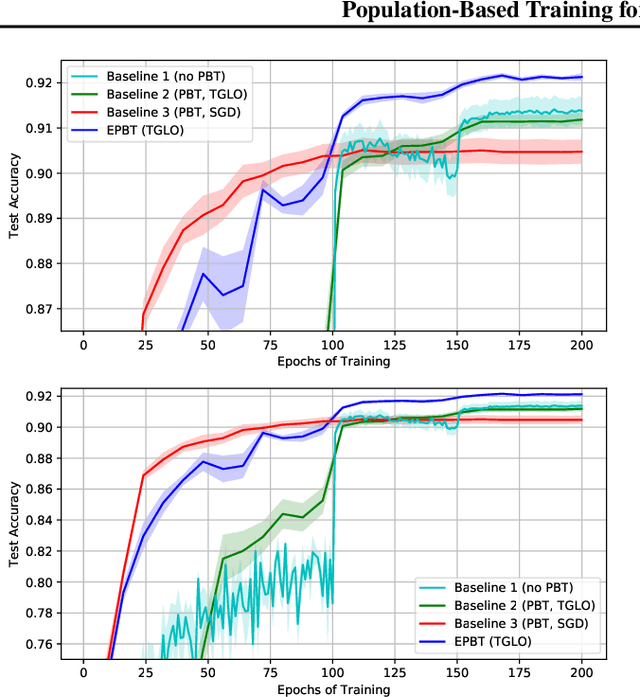

Metalearning of deep neural network (DNN) architectures and hyperparameters has become an increasingly important area of research. Loss functions are a type of metaknowledge that is crucial to effective training of DNNs and their potential role in metalearning has not yet been fully explored. This paper presents an algorithm called Enhanced Population-Based Training (EPBT) that interleaves the training of a DNN's weights with the metalearning of optimal hyperparameters and loss functions. Loss functions use a TaylorGLO parameterization, based on multivariate Taylor expansions, that EPBT can directly optimize. On the CIFAR-10 and SVHN image classification benchmarks, EPBT discovers loss function schedules that enable faster, more accurate learning. The discovered functions adapt to the training process and serve to regularize the learning task by discouraging overfitting to the labels. EPBT thus demonstrates a promising synergy of simultaneous training and metalearning.
Evolutionary Neural AutoML for Deep Learning
Apr 09, 2019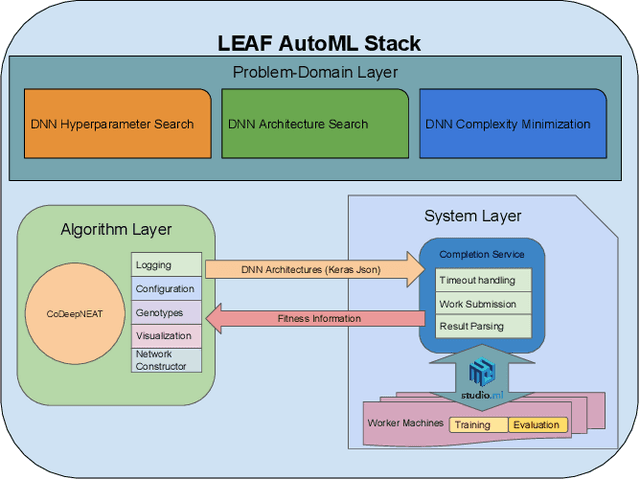
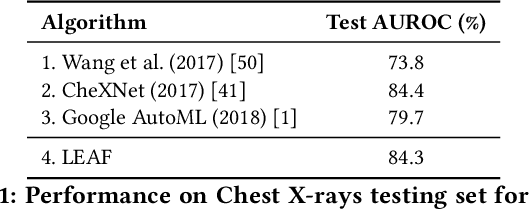

Deep neural networks (DNNs) have produced state-of-the-art results in many benchmarks and problem domains. However, the success of DNNs depends on the proper configuration of its architecture and hyperparameters. Such a configuration is difficult and as a result, DNNs are often not used to their full potential. In addition, DNNs in commercial applications often need to satisfy real-world design constraints such as size or number of parameters. To make configuration easier, automatic machine learning (AutoML) systems for deep learning have been developed, focusing mostly on optimization of hyperparameters. This paper takes AutoML a step further. It introduces an evolutionary AutoML framework called LEAF that not only optimizes hyperparameters but also network architectures and the size of the network. LEAF makes use of both state-of-the-art evolutionary algorithms (EAs) and distributed computing frameworks. Experimental results on medical image classification and natural language analysis show that the framework can be used to achieve state-of-the-art performance. In particular, LEAF demonstrates that architecture optimization provides a significant boost over hyperparameter optimization, and that networks can be minimized at the same time with little drop in performance. LEAF therefore forms a foundation for democratizing and improving AI, as well as making AI practical in future applications.
Evolutionary Architecture Search For Deep Multitask Networks
Apr 17, 2018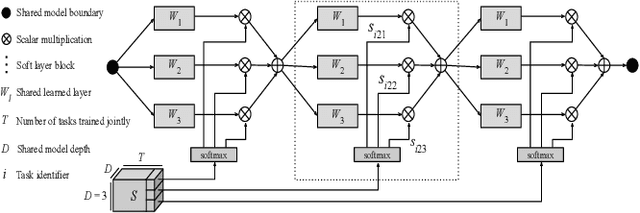
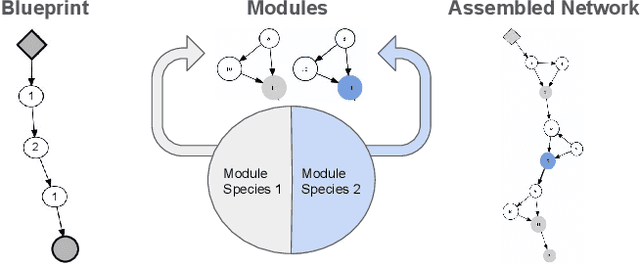
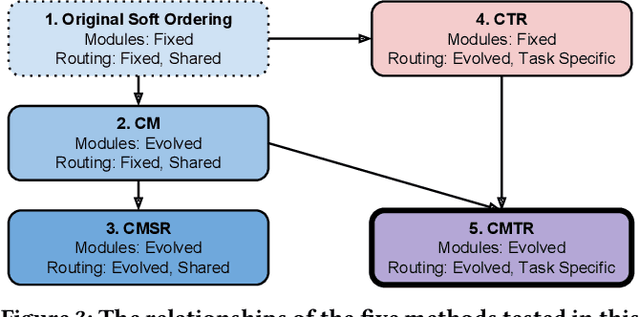
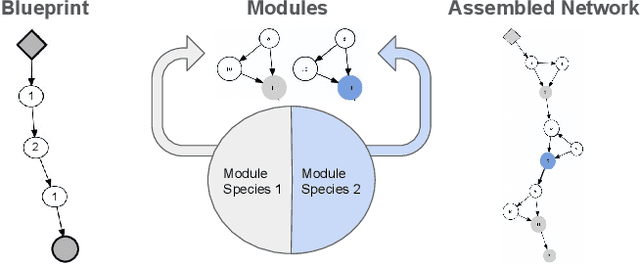
Multitask learning, i.e. learning several tasks at once with the same neural network, can improve performance in each of the tasks. Designing deep neural network architectures for multitask learning is a challenge: There are many ways to tie the tasks together, and the design choices matter. The size and complexity of this problem exceeds human design ability, making it a compelling domain for evolutionary optimization. Using the existing state of the art soft ordering architecture as the starting point, methods for evolving the modules of this architecture and for evolving the overall topology or routing between modules are evaluated in this paper. A synergetic approach of evolving custom routings with evolved, shared modules for each task is found to be very powerful, significantly improving the state of the art in the Omniglot multitask, multialphabet character recognition domain. This result demonstrates how evolution can be instrumental in advancing deep neural network and complex system design in general.
Evolving Deep Neural Networks
Mar 04, 2017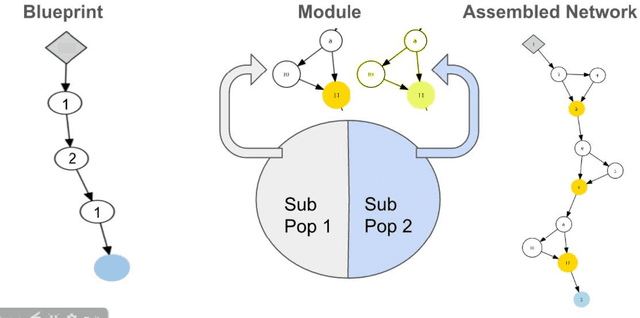
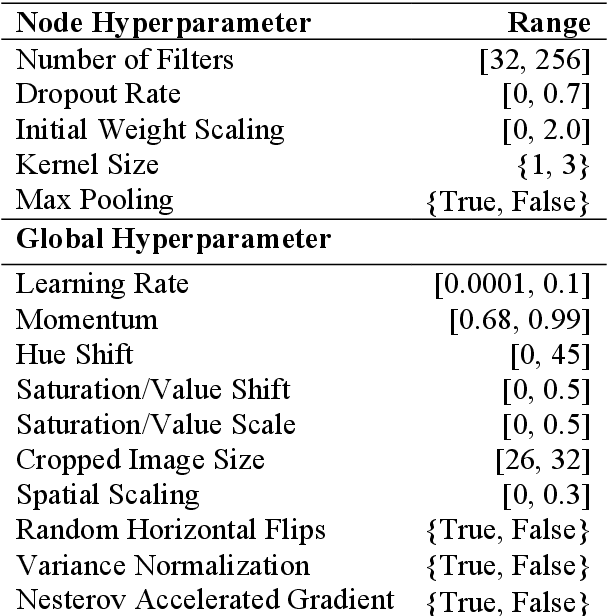
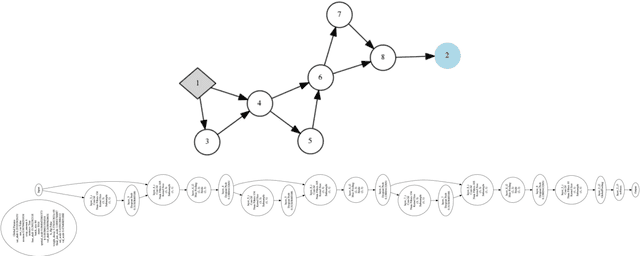
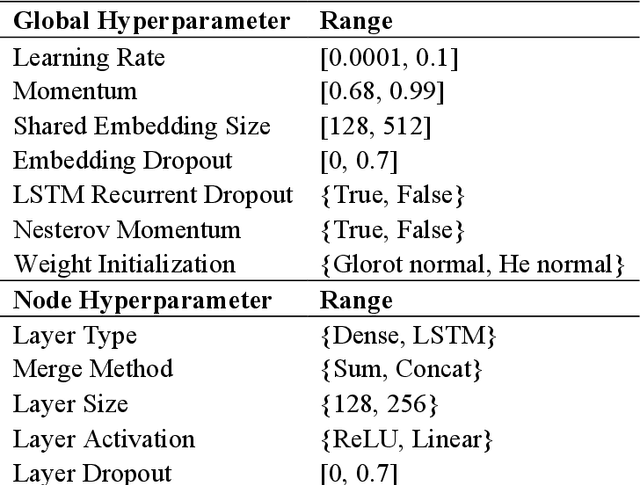
The success of deep learning depends on finding an architecture to fit the task. As deep learning has scaled up to more challenging tasks, the architectures have become difficult to design by hand. This paper proposes an automated method, CoDeepNEAT, for optimizing deep learning architectures through evolution. By extending existing neuroevolution methods to topology, components, and hyperparameters, this method achieves results comparable to best human designs in standard benchmarks in object recognition and language modeling. It also supports building a real-world application of automated image captioning on a magazine website. Given the anticipated increases in available computing power, evolution of deep networks is promising approach to constructing deep learning applications in the future.