 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Language Model Benchmarks with Pairwise Preferences
Feb 02, 2026Language model benchmarks are pervasive and computationally-efficient proxies for real-world performance. However, many recent works find that benchmarks often fail to predict real utility. Towards bridging this gap, we introduce benchmark alignment, where we use limited amounts of information about model performance to automatically update offline benchmarks, aiming to produce new static benchmarks that predict model pairwise preferences in given test settings. We then propose BenchAlign, the first solution to this problem, which learns preference-aligned weight- ings for benchmark questions using the question-level performance of language models alongside ranked pairs of models that could be collected during deployment, producing new benchmarks that rank previously unseen models according to these preferences. Our experiments show that our aligned benchmarks can accurately rank unseen models according to models of human preferences, even across different sizes, while remaining interpretable. Overall, our work provides insights into the limits of aligning benchmarks with practical human preferences, which stands to accelerate model development towards real utility.
Narrative Analysis of True Crime Podcasts With Knowledge Graph-Augmented Large Language Models
Nov 01, 2024
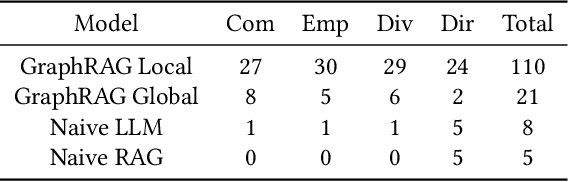

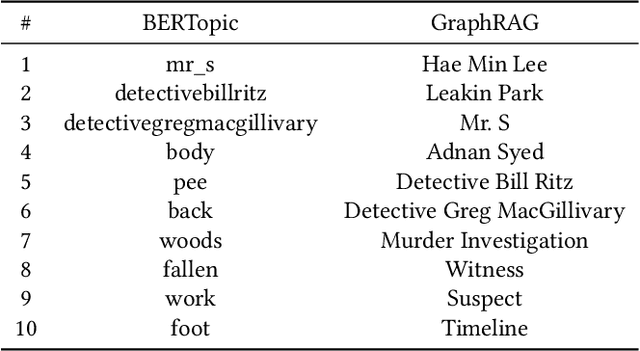
Narrative data spans all disciplines and provides a coherent model of the world to the reader or viewer. Recent advancement in machine learning and Large Language Models (LLMs) have enable great strides in analyzing natural language. However, Large language models (LLMs) still struggle with complex narrative arcs as well as narratives containing conflicting information. Recent work indicates LLMs augmented with external knowledge bases can improve the accuracy and interpretability of the resulting models. In this work, we analyze the effectiveness of applying knowledge graphs (KGs) in understanding true-crime podcast data from both classical Natural Language Processing (NLP) and LLM approaches. We directly compare KG-augmented LLMs (KGLLMs) with classical methods for KG construction, topic modeling, and sentiment analysis. Additionally, the KGLLM allows us to query the knowledge base in natural language and test its ability to factually answer questions. We examine the robustness of the model to adversarial prompting in order to test the model's ability to deal with conflicting information. Finally, we apply classical methods to understand more subtle aspects of the text such as the use of hearsay and sentiment in narrative construction and propose future directions. Our results indicate that KGLLMs outperform LLMs on a variety of metrics, are more robust to adversarial prompts, and are more capable of summarizing the text into topics.