 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Language Model Benchmarks with Pairwise Preferences
Feb 02, 2026Language model benchmarks are pervasive and computationally-efficient proxies for real-world performance. However, many recent works find that benchmarks often fail to predict real utility. Towards bridging this gap, we introduce benchmark alignment, where we use limited amounts of information about model performance to automatically update offline benchmarks, aiming to produce new static benchmarks that predict model pairwise preferences in given test settings. We then propose BenchAlign, the first solution to this problem, which learns preference-aligned weight- ings for benchmark questions using the question-level performance of language models alongside ranked pairs of models that could be collected during deployment, producing new benchmarks that rank previously unseen models according to these preferences. Our experiments show that our aligned benchmarks can accurately rank unseen models according to models of human preferences, even across different sizes, while remaining interpretable. Overall, our work provides insights into the limits of aligning benchmarks with practical human preferences, which stands to accelerate model development towards real utility.
Convolutional module for heart localization and segmentation in MRI
Jul 19, 2021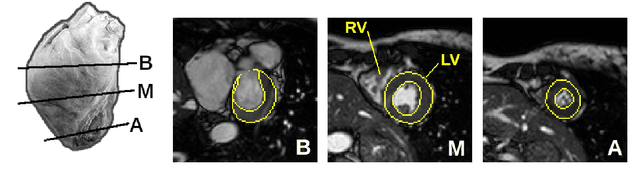
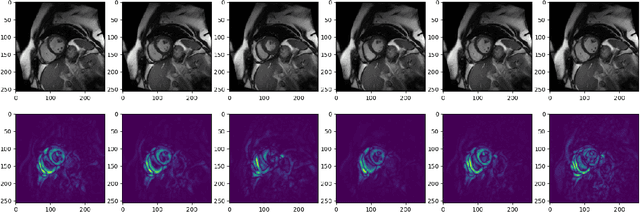
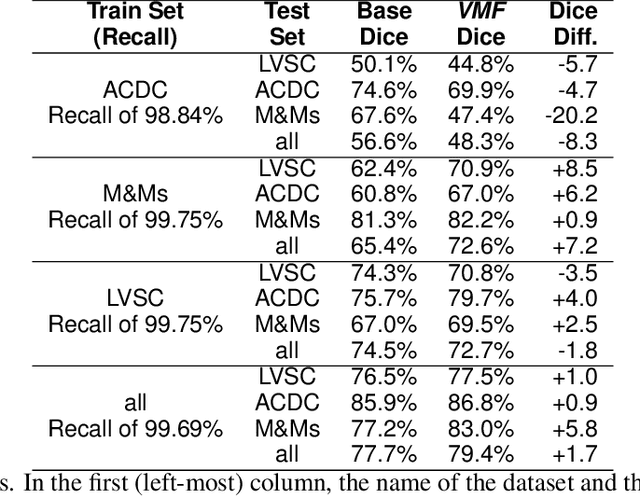
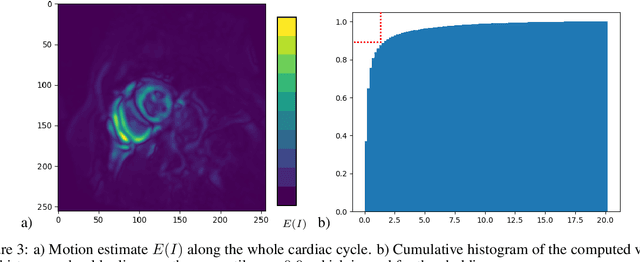
Magnetic resonance imaging (MRI) is a widely known medical imaging technique used to assess the heart function. Deep learning (DL) models perform several tasks in cardiac MRI (CMR) images with good efficacy, such as segmentation, estimation, and detection of diseases. Many DL models based on convolutional neural networks (CNN) were improved by detecting regions-of-interest (ROI) either automatically or by hand. In this paper we describe Visual-Motion-Focus (VMF), a module that detects the heart motion in the 4D MRI sequence, and highlights ROIs by focusing a Radial Basis Function (RBF) on the estimated motion field. We experimented and evaluated VMF on three CMR datasets, observing that the proposed ROIs cover 99.7% of data labels (Recall score), improved the CNN segmentation (mean Dice score) by 1.7 (p < .001) after the ROI extraction, and improved the overall training speed by 2.5 times (+150%).
A study of CNN capacity applied to Left Venticle Segmentation in Cardiac MRI
Jul 03, 2021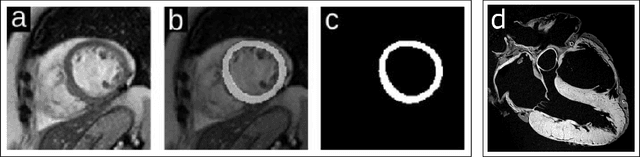

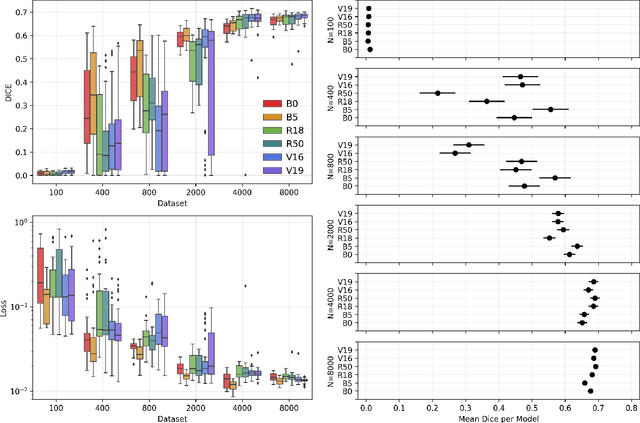

CNN (Convolutional Neural Network) models have been successfully used for segmentation of the left ventricle (LV) in cardiac MRI (Magnetic Resonance Imaging), providing clinical measurements.In practice, two questions arise with deployment of CNNs: 1) when is it better to use a shallow model instead of a deeper one? 2) how the size of a dataset might change the network performance? We propose a framework to answer them, by experimenting with deep and shallow versions of three U-Net families, trained from scratch in six subsets varying from 100 to 10,000 images, different network sizes, learning rates and regularization values. 1620 models were evaluated using 5-foldcross-validation by loss and DICE. The results indicate that: sample size affects performance more than architecture or hyper-parameters; in small samples the performance is more sensitive to hyper-parameters than architecture; the performance difference between shallow and deeper networks is not the same across families.