 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study of CNN capacity applied to Left Venticle Segmentation in Cardiac MRI
Paper and Code
Jul 03, 2021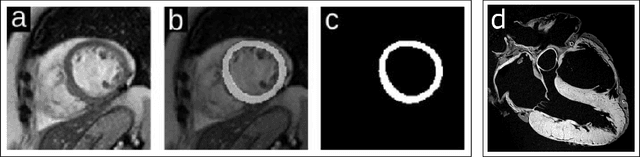

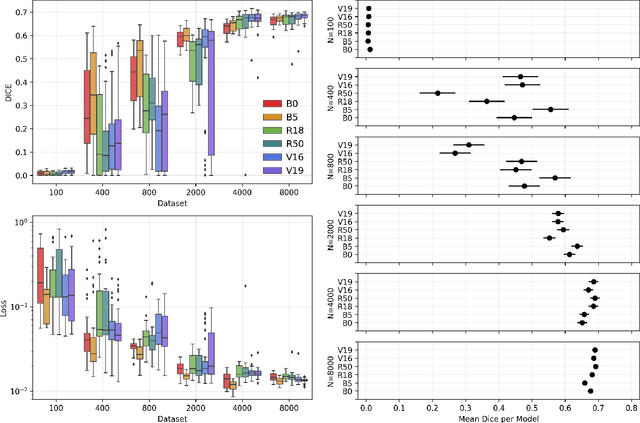

CNN (Convolutional Neural Network) models have been successfully used for segmentation of the left ventricle (LV) in cardiac MRI (Magnetic Resonance Imaging), providing clinical measurements.In practice, two questions arise with deployment of CNNs: 1) when is it better to use a shallow model instead of a deeper one? 2) how the size of a dataset might change the network performance? We propose a framework to answer them, by experimenting with deep and shallow versions of three U-Net families, trained from scratch in six subsets varying from 100 to 10,000 images, different network sizes, learning rates and regularization values. 1620 models were evaluated using 5-foldcross-validation by loss and DICE. The results indicate that: sample size affects performance more than architecture or hyper-parameters; in small samples the performance is more sensitive to hyper-parameters than architecture; the performance difference between shallow and deeper networks is not the same across families.