 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Language Models to Know What They Know
Feb 02, 2026Metacognition is a critical component of intelligence, specifically regarding the awareness of one's own knowledge. While humans rely on shared internal memory for both answering questions and reporting their knowledge state, this dependency in LLMs remains underexplored. This study proposes a framework to measure metacognitive ability $d_{\rm{type2}}'$ using a dual-prompt method, followed by the introduction of Evolution Strategy for Metacognitive Alignment (ESMA) to bind a model's internal knowledge to its explicit behaviors. ESMA demonstrates robust generalization across diverse untrained settings, indicating a enhancement in the model's ability to reference its own knowledge. Furthermore, parameter analysis attributes these improvements to a sparse set of significant modifications.
Solving a Million-Step LLM Task with Zero Errors
Nov 12, 2025LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations, and societies has remained out of reach. The models have a persistent error rate that prevents scale-up: for instance, recent experiments in the Towers of Hanoi benchmark domain showed that the process inevitably becomes derailed after at most a few hundred steps. Thus, although LLM research is often still benchmarked on tasks with relatively few dependent logical steps, there is increasing attention on the ability (or inability) of LLMs to perform long range tasks. This paper describes MAKER, the first system that successfully solves a task with over one million LLM steps with zero errors, and, in principle, scales far beyond this level. The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents. The high level of modularity resulting from the decomposition allows error correction to be applied at each step through an efficient multi-agent voting scheme. This combination of extreme decomposition and error correction makes scaling possible. Thus, the results suggest that instead of relying on continual improvement of current LLMs, massively decomposed agentic processes (MDAPs) may provide a way to efficiently solve problems at the level of organizations and societies.
Position: Scaling LLM Agents Requires Asymptotic Analysis with LLM Primitives
Feb 04, 2025Decomposing hard problems into subproblems often makes them easier and more efficient to solve. With large language models (LLMs) crossing critical reliability thresholds for a growing slate of capabilities, there is an increasing effort to decompose systems into sets of LLM-based agents, each of whom can be delegated sub-tasks. However, this decomposition (even when automated) is often intuitive, e.g., based on how a human might assign roles to members of a human team. How close are these role decompositions to optimal? This position paper argues that asymptotic analysis with LLM primitives is needed to reason about the efficiency of such decomposed systems, and that insights from such analysis will unlock opportunities for scaling them. By treating the LLM forward pass as the atomic unit of computational cost, one can separate out the (often opaque) inner workings of a particular LLM from the inherent efficiency of how a set of LLMs are orchestrated to solve hard problems. In other words, if we want to scale the deployment of LLMs to the limit, instead of anthropomorphizing LLMs, asymptotic analysis with LLM primitives should be used to reason about and develop more powerful decompositions of large problems into LLM agents.
Surveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
Dec 04, 2024



Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.
Unlocking the Potential of Global Human Expertise
Oct 31, 2024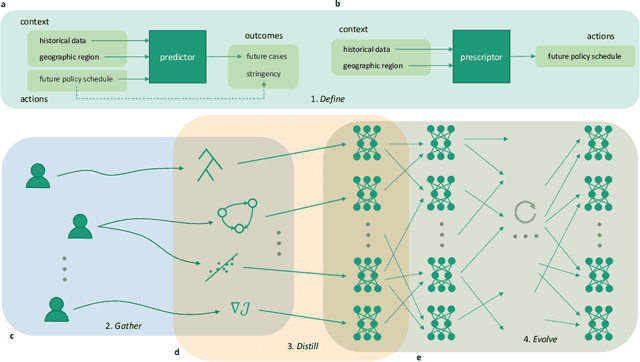
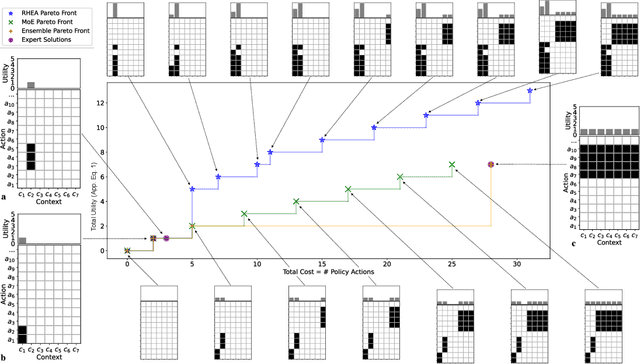
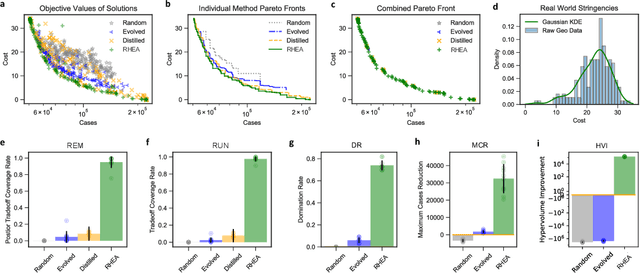
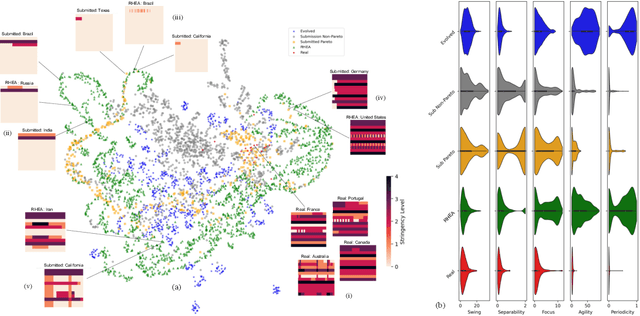
Solving societal problems on a global scale requires the collection and processing of ideas and methods from diverse sets of international experts. As the number and diversity of human experts increase, so does the likelihood that elements in this collective knowledge can be combined and refined to discover novel and better solutions. However, it is difficult to identify, combine, and refine complementary information in an increasingly large and diverse knowledge base. This paper argues that artificial intelligence (AI) can play a crucial role in this process. An evolutionary AI framework, termed RHEA, fills this role by distilling knowledge from diverse models created by human experts into equivalent neural networks, which are then recombined and refined in a population-based search. The framework was implemented in a formal synthetic domain, demonstrating that it is transparent and systematic. It was then applied to the results of the XPRIZE Pandemic Response Challenge, in which over 100 teams of experts across 23 countries submitted models based on diverse methodologies to predict COVID-19 cases and suggest non-pharmaceutical intervention policies for 235 nations, states, and regions across the globe. Building upon this expert knowledge, by recombining and refining the 169 resulting policy suggestion models, RHEA discovered a broader and more effective set of policies than either AI or human experts alone, as evaluated based on real-world data. The results thus suggest that AI can play a crucial role in realizing the potential of human expertise in global problem-solving.
Discovering Effective Policies for Land-Use Planning
Nov 21, 2023How areas of land are allocated for different uses, such as forests, urban, and agriculture, has a large effect on carbon balance, and therefore climate change. Based on available historical data on changes in land use and a simulation of carbon emissions/absorption, a surrogate model can be learned that makes it possible to evaluate the different options available to decision-makers efficiently. An evolutionary search process can then be used to discover effective land-use policies for specific locations. Such a system was built on the Project Resilience platform and evaluated with the Land-Use Harmonization dataset and the BLUE simulator. It generates Pareto fronts that trade off carbon impact and amount of change customized to different locations, thus providing a potentially useful tool for land-use planning.
Language Model Crossover: Variation through Few-Shot Prompting
Feb 23, 2023This paper pursues the insight that language models naturally enable an intelligent variation operator similar in spirit to evolutionary crossover. In particular, language models of sufficient scale demonstrate in-context learning, i.e. they can learn from associations between a small number of input patterns to generate outputs incorporating such associations (also called few-shot prompting). This ability can be leveraged to form a simple but powerful variation operator, i.e. to prompt a language model with a few text-based genotypes (such as code, plain-text sentences, or equations), and to parse its corresponding output as those genotypes' offspring. The promise of such language model crossover (which is simple to implement and can leverage many different open-source language models) is that it enables a simple mechanism to evolve semantically-rich text representations (with few domain-specific tweaks), and naturally benefits from current progress in language models. Experiments in this paper highlight the versatility of language-model crossover, through evolving binary bit-strings, sentences, equations, text-to-image prompts, and Python code. The conclusion is that language model crossover is a promising method for evolving genomes representable as text.
Simple Genetic Operators are Universal Approximators of Probability Distributions (and other Advantages of Expressive Encodings)
Feb 19, 2022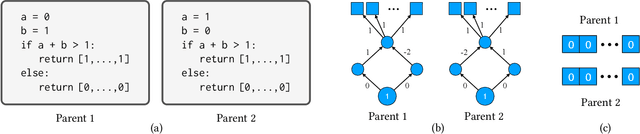

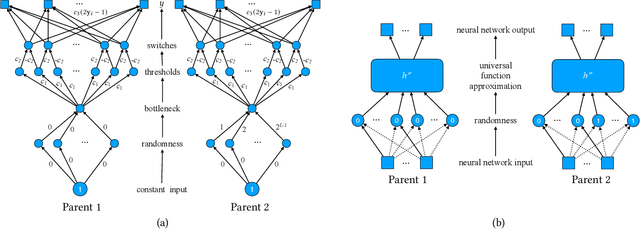
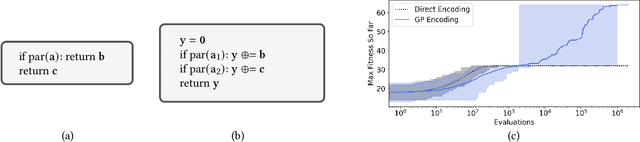
This paper characterizes the inherent power of evolutionary algorithms. This power depends on the computational properties of the genetic encoding. With some encodings, two parents recombined with a simple crossover operator can sample from an arbitrary distribution of child phenotypes. Such encodings are termed \emph{expressive encodings} in this paper. Universal function approximators, including popular evolutionary substrates of genetic programming and neural networks, can be used to construct expressive encodings. Remarkably, this approach need not be applied only to domains where the phenotype is a function: Expressivity can be achieved even when optimizing static structures, such as binary vectors. Such simpler settings make it possible to characterize expressive encodings theoretically: Across a variety of test problems, expressive encodings are shown to achieve up to super-exponential convergence speed-ups over the standard direct encoding. The conclusion is that, across evolutionary computation areas as diverse as genetic programming, neuroevolution, genetic algorithms, and theory, expressive encodings can be a key to understanding and realizing the full power of evolution.
The Traveling Observer Model: Multi-task Learning Through Spatial Variable Embeddings
Oct 05, 2020
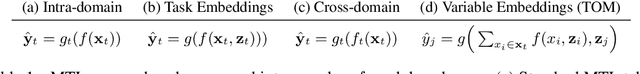
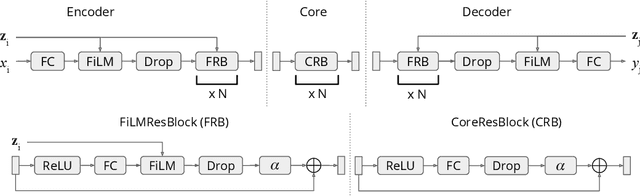

This paper frames a general prediction system as an observer traveling around a continuous space, measuring values at some locations, and predicting them at others. The observer is completely agnostic about any particular task being solved; it cares only about measurement locations and their values. This perspective leads to a machine learning framework in which seemingly unrelated tasks can be solved by a single model, by embedding their input and output variables into a shared space. An implementation of the framework is developed in which these variable embeddings are learned jointly with internal model parameters. In experiments, the approach is shown to (1) recover intuitive locations of variables in space and time, (2) exploit regularities across related datasets with completely disjoint input and output spaces, and (3) exploit regularities across seemingly unrelated tasks, outperforming task-specific single-task models and multi-task learning alternatives. The results suggest that even seemingly unrelated tasks may originate from similar underlying processes, a fact that the traveling observer model can use to make better predictions.
From Prediction to Prescription: AI-Based Optimization of Non-Pharmaceutical Interventions for the COVID-19 Pandemic
May 30, 2020
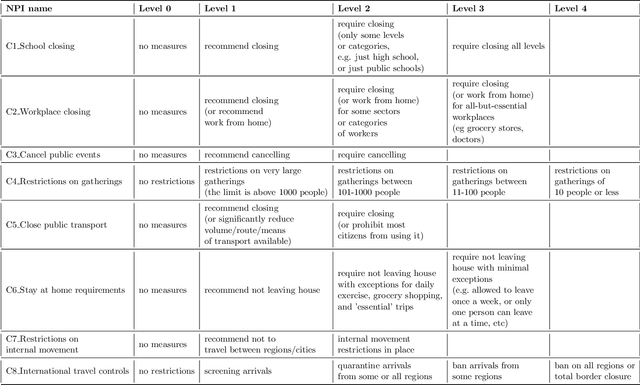
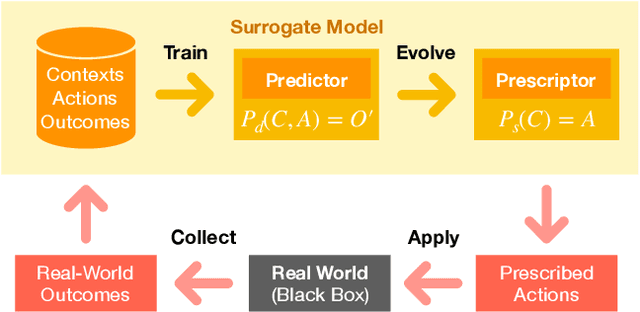

Several models have been developed to predict how the COVID-19 pandemic spreads, and how it could be contained with non-pharmaceutical interventions (NPIs) such as social distancing restrictions and school and business closures. This paper demonstrates how evolutionary AI could be used to facilitate the next step, i.e. determining most effective intervention strategies automatically. Through evolutionary surrogate-assisted prescription (ESP), it is possible to generate a large number of candidate strategies and evaluate them with predictive models. In principle, strategies can be customized for different countries and locales, and balance the need to contain the pandemic and the need to minimize their economic impact. While still limited by available data, early experiments suggest that workplace and school restrictions are the most important and need to be designed carefully. It also demonstrates that results of lifting restrictions can be unreliable, and suggests creative ways in which restrictions can be implemented softly, e.g. by alternating them over time. As more data becomes available, the approach can be increasingly useful in dealing with COVID-19 as well as possible future pandemics.