 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Range Characterization of Open Text-to-Audio Models
Oct 31, 2025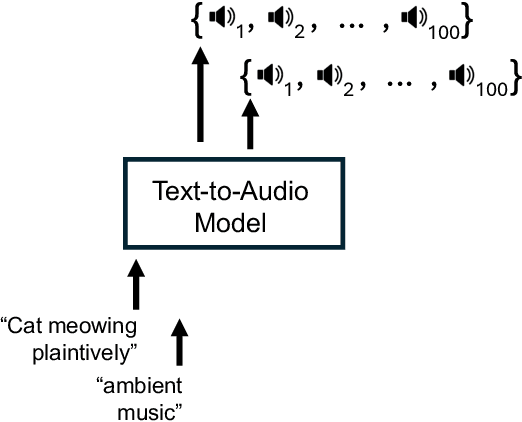
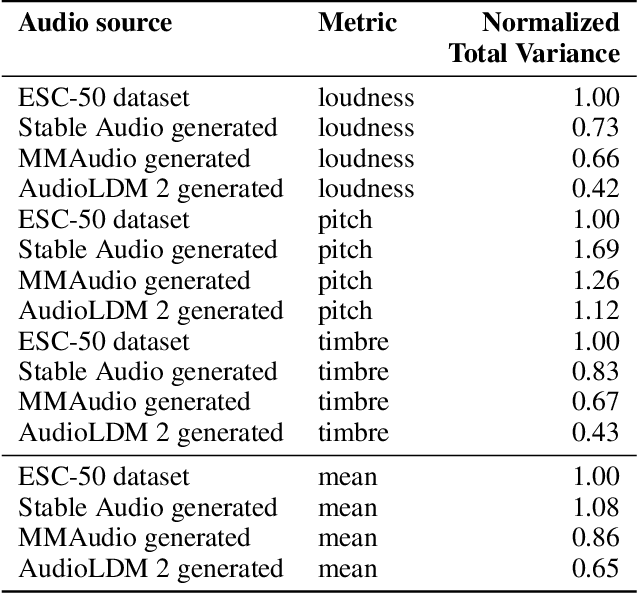
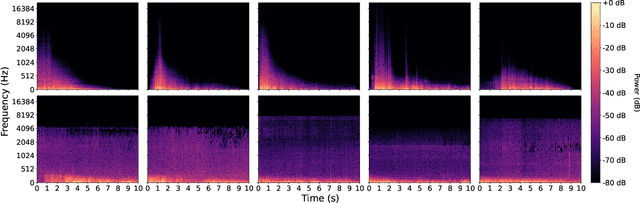
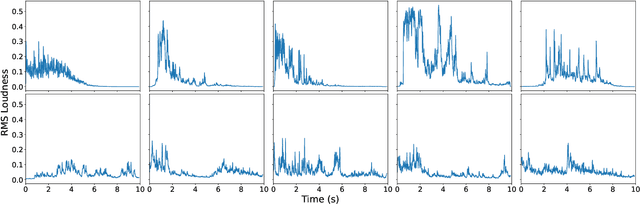
Text-to-audio models are a type of generative model that produces audio output in response to a given textual prompt. Although level generators and the properties of the functional content that they create (e.g., playability) dominate most discourse in procedurally generated content (PCG), games that emotionally resonate with players tend to weave together a range of creative and multimodal content (e.g., music, sounds, visuals, narrative tone), and multimodal models have begun seeing at least experimental use for this purpose. However, it remains unclear what exactly such models generate, and with what degree of variability and fidelity: audio is an extremely broad class of output for a generative system to target. Within the PCG community, expressive range analysis (ERA) has been used as a quantitative way to characterize generators' output space, especially for level generators. This paper adapts ERA to text-to-audio models, making the analysis tractable by looking at the expressive range of outputs for specific, fixed prompts. Experiments are conducted by prompting the models with several standardized prompts derived from the Environmental Sound Classification (ESC-50) dataset. The resulting audio is analyzed along key acoustic dimensions (e.g., pitch, loudness, and timbre). More broadly, this paper offers a framework for ERA-based exploratory evaluation of generative audio models.
Resource-constrained knowledge diffusion processes inspired by human peer learning
Dec 01, 2023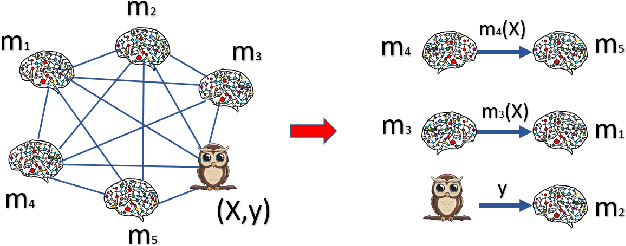
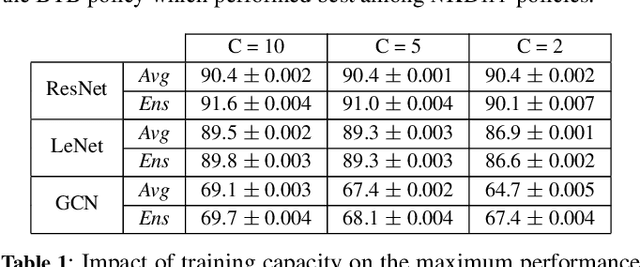
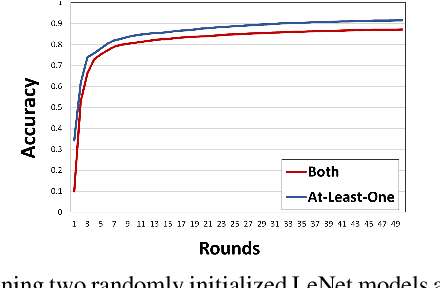
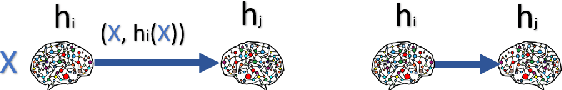
We consider a setting where a population of artificial learners is given, and the objective is to optimize aggregate measures of performance, under constraints on training resources. The problem is motivated by the study of peer learning in human educational systems. In this context, we study natural knowledge diffusion processes in networks of interacting artificial learners. By `natural', we mean processes that reflect human peer learning where the students' internal state and learning process is mostly opaque, and the main degree of freedom lies in the formation of peer learning groups by a coordinator who can potentially evaluate the learners before assigning them to peer groups. Among else, we empirically show that such processes indeed make effective use of the training resources, and enable the design of modular neural models that have the capacity to generalize without being prone to overfitting noisy labels.
Language Model Crossover: Variation through Few-Shot Prompting
Feb 23, 2023This paper pursues the insight that language models naturally enable an intelligent variation operator similar in spirit to evolutionary crossover. In particular, language models of sufficient scale demonstrate in-context learning, i.e. they can learn from associations between a small number of input patterns to generate outputs incorporating such associations (also called few-shot prompting). This ability can be leveraged to form a simple but powerful variation operator, i.e. to prompt a language model with a few text-based genotypes (such as code, plain-text sentences, or equations), and to parse its corresponding output as those genotypes' offspring. The promise of such language model crossover (which is simple to implement and can leverage many different open-source language models) is that it enables a simple mechanism to evolve semantically-rich text representations (with few domain-specific tweaks), and naturally benefits from current progress in language models. Experiments in this paper highlight the versatility of language-model crossover, through evolving binary bit-strings, sentences, equations, text-to-image prompts, and Python code. The conclusion is that language model crossover is a promising method for evolving genomes representable as text.
Watts: Infrastructure for Open-Ended Learning
Apr 28, 2022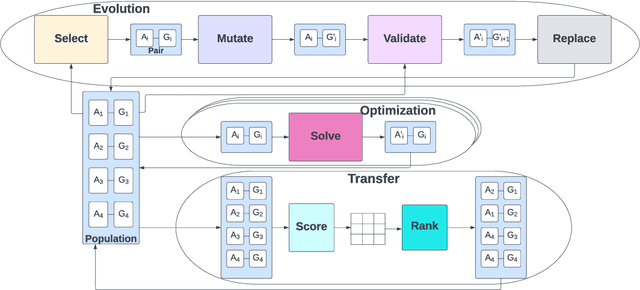

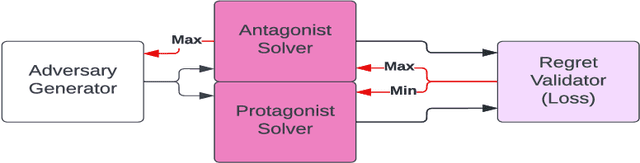
This paper proposes a framework called Watts for implementing, comparing, and recombining open-ended learning (OEL) algorithms. Motivated by modularity and algorithmic flexibility, Watts atomizes the components of OEL systems to promote the study of and direct comparisons between approaches. Examining implementations of three OEL algorithms, the paper introduces the modules of the framework. The hope is for Watts to enable benchmarking and to explore new types of OEL algorithms. The repo is available at \url{https://github.com/aadharna/watts}
Deep Surrogate Assisted MAP-Elites for Automated Hearthstone Deckbuilding
Dec 07, 2021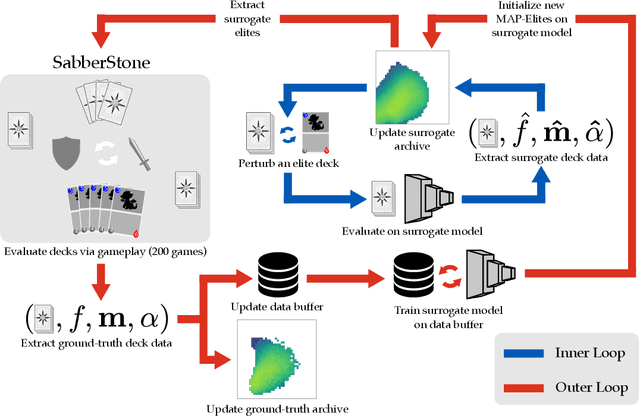
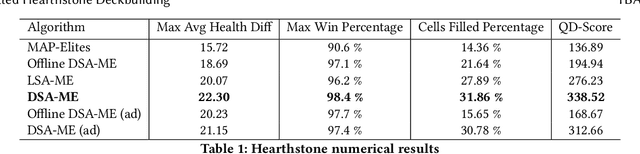
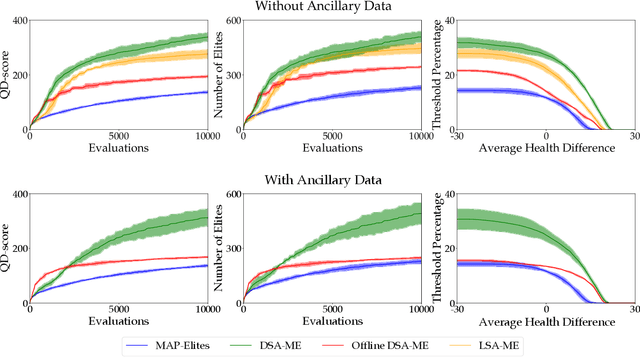
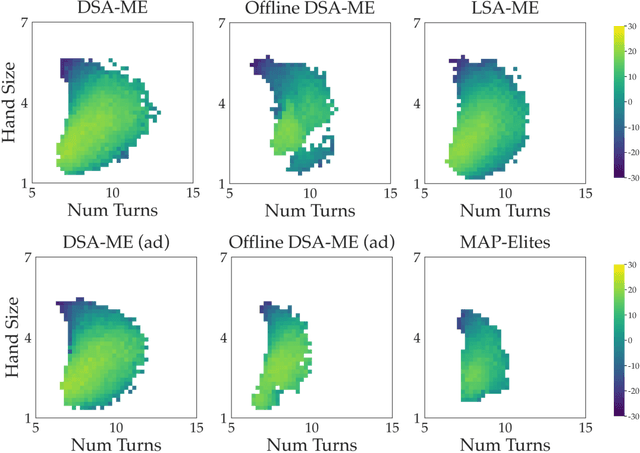
We study the problem of efficiently generating high-quality and diverse content in games. Previous work on automated deckbuilding in Hearthstone shows that the quality diversity algorithm MAP-Elites can generate a collection of high-performing decks with diverse strategic gameplay. However, MAP-Elites requires a large number of expensive evaluations to discover the diverse collection of decks. We propose assisting MAP-Elites with a deep surrogate model trained online to predict game outcomes with respect to candidate decks. MAP-Elites discovers a diverse dataset to improve the surrogate model accuracy, while the surrogate model helps guide MAP-Elites towards promising new content. In a Hearthstone deckbuilding case study, we show that our approach improves the sample efficiency of MAP-Elites and outperforms a model trained offline with random decks, as well as a linear surrogate model baseline, setting a new state-of-the-art for quality diversity approaches in the application domain of automated Hearthstone deckbuilding.
Video Game Level Repair via Mixed Integer Linear Programming
Oct 13, 2020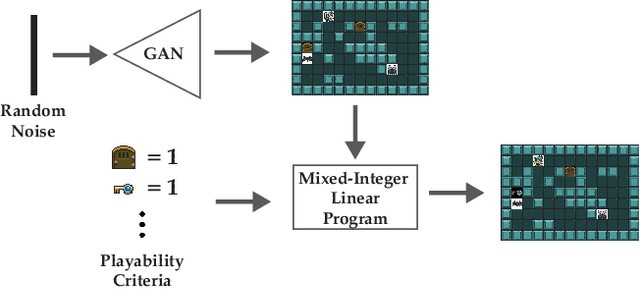


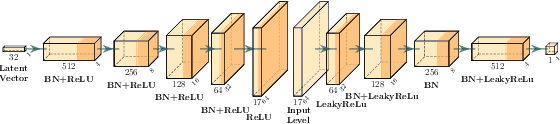
Recent advancements in procedural content generation via machine learning enable the generation of video-game levels that are aesthetically similar to human-authored examples. However, the generated levels are often unplayable without additional editing. We propose a generate-then-repair framework for automatic generation of playable levels adhering to specific styles. The framework constructs levels using a generative adversarial network (GAN) trained with human-authored examples and repairs them using a mixed-integer linear program (MIP) with playability constraints. A key component of the framework is computing minimum cost edits between the GAN generated level and the solution of the MIP solver, which we cast as a minimum cost network flow problem. Results show that the proposed framework generates a diverse range of playable levels, that capture the spatial relationships between objects exhibited in the human-authored levels.
Illuminating Mario Scenes in the Latent Space of a Generative Adversarial Network
Jul 11, 2020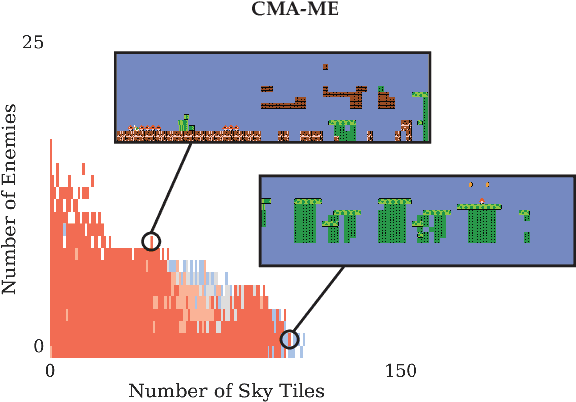


Recent developments in machine learning techniques have allowed automatic generation of video game levels that are stylistically similar to human-designed examples. While the output of machine learning models such as generative adversarial networks (GANs) is notoriously hard to control, the recently proposed latent variable evolution (LVE) technique searches the space of GAN parameters to generate outputs that optimize some objective performance metric, such as level playability. However, the question remains on how to automatically generate a diverse range of high-quality solutions based on a prespecified set of desired characteristics. We introduce a new method called latent space illumination (LSI), which uses state-of-the-art quality diversity algorithms designed to optimize in continuous spaces, i.e., MAP-Elites with a directional variation operator and Covariance Matrix Adaptation MAP-Elites, to effectively search the parameter space of theGAN along a set of multiple level mechanics. We show the performance of LSI algorithms in three experiments in SuperMario Bros., a benchmark domain for procedural content generation. Results suggest that LSI generates sets of Mario levels that are reliably mechanically diverse as well as playable.
Covariance Matrix Adaptation for the Rapid Illumination of Behavior Space
Dec 05, 2019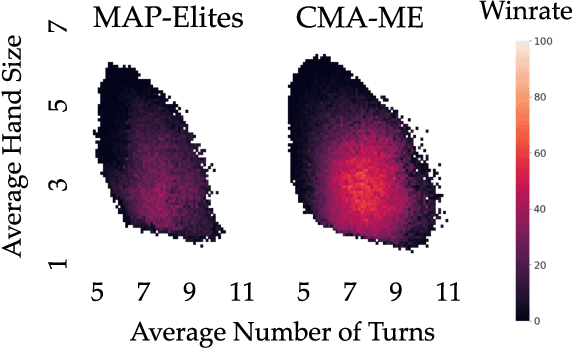
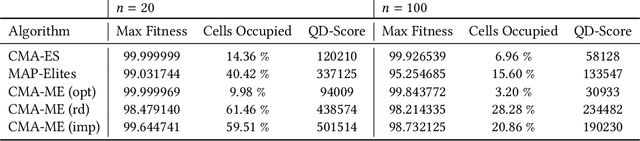
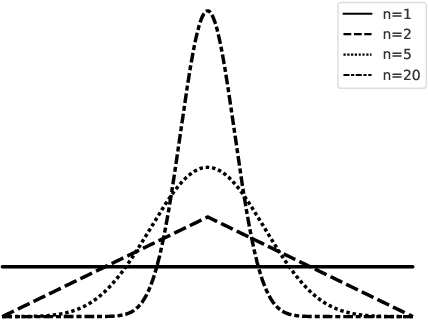
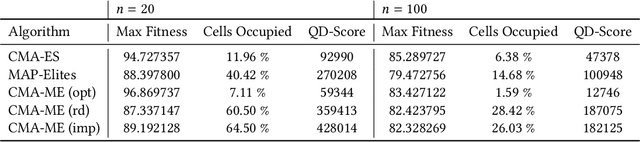
Quality Diversity (QD) algorithms like Novelty Search with Local Competition (NSLC) and MAP-Elites are a new class of population-based stochastic algorithms designed to generate a diverse collection of quality solutions. Meanwhile, variants of the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) are among the best-performing derivative-free optimizers in single-objective continuous domains. This paper proposes a new QD algorithm called Covariance Matrix Adaptation MAP-Elites (CMA-ME). Our new algorithm combines the dynamic self-adaptation techniques of CMA-ES with archiving and mapping techniques for maintaining diversity in QD. Results from experiments with standard continuous optimization benchmarks show that CMA-ME finds better-quality solutions than MAP-Elites; similarly, results on the strategic game Hearthstone show that CMA-ME finds both a higher overall quality and broader diversity of strategies than both CMA-ES and MAP-Elites. Overall, CMA-ME more than doubles the performance of MAP-Elites using standard QD performance metrics. These results suggest that QD algorithms augmented by operators from state-of-the-art optimization algorithms can yield high-performing methods for simultaneously exploring and optimizing continuous search spaces, with significant applications to design, testing, and reinforcement learning among other domains. Code is available for both the continuous optimization benchmark (https://github.com/tehqin/QualDivBenchmark) and Hearthstone (https://github.com/tehqin/EvoStone) domains.
The Many AI Challenges of Hearthstone
Jul 15, 2019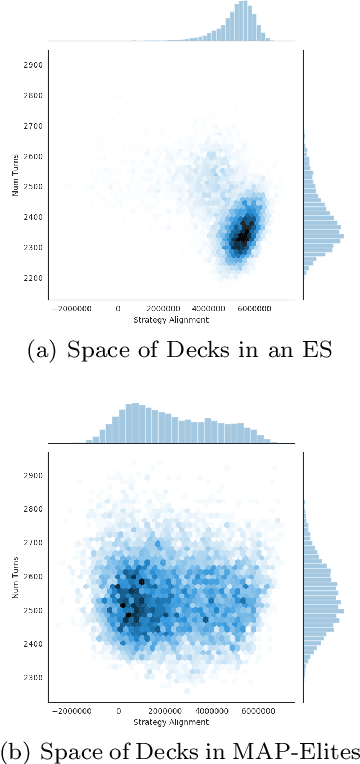
Games have benchmarked AI methods since the inception of the field, with classic board games such as Chess and Go recently leaving room for video games with related yet different sets of challenges. The set of AI problems associated with video games has in recent decades expanded from simply playing games to win, to playing games in particular styles, generating game content, modeling players etc. Different games pose very different challenges for AI systems, and several different AI challenges can typically be posed by the same game. In this article we analyze the popular collectible card game Hearthstone (Blizzard 2014) and describe a varied set of interesting AI challenges posed by this game. Collectible card games are relatively understudied in the AI community, despite their popularity and the interesting challenges they pose. Analyzing a single game in-depth in the manner we do here allows us to see the entire field of AI and Games through the lens of a single game, discovering a few new variations on existing research topics.
Evolving the Hearthstone Meta
Jul 02, 2019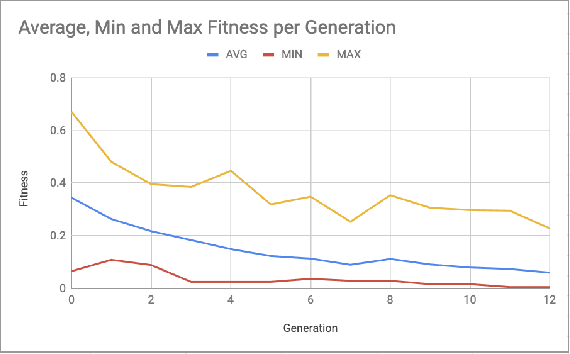
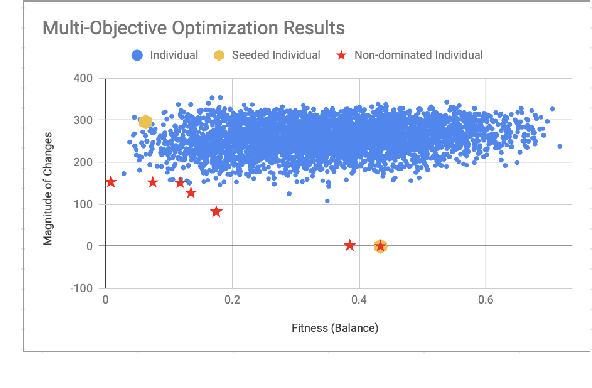
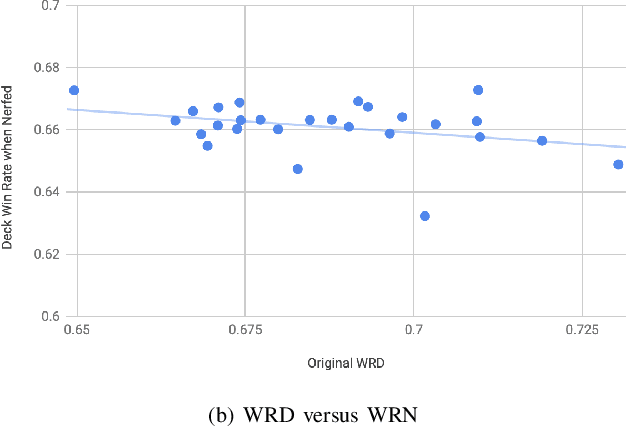
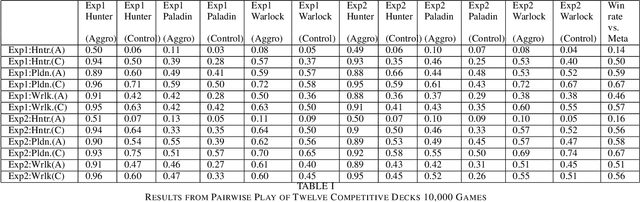
Balancing an ever growing strategic game of high complexity, such as Hearthstone is a complex task. The target of making strategies diverse and customizable results in a delicate intricate system. Tuning over 2000 cards to generate the desired outcome without disrupting the existing environment becomes a laborious challenge. In this paper, we discuss the impacts that changes to existing cards can have on strategy in Hearthstone. By analyzing the win rate on match-ups across different decks, being played by different strategies, we propose to compare their performance before and after changes are made to improve or worsen different cards. Then, using an evolutionary algorithm, we search for a combination of changes to the card attributes that cause the decks to approach equal, 50% win rates. We then expand our evolutionary algorithm to a multi-objective solution to search for this result, while making the minimum amount of changes, and as a consequence disruption, to the existing cards. Lastly, we propose and evaluate metrics to serve as heuristics with which to decide which cards to target with balance changes.