 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackbox Post-Processing for Multiclass Fairness
Jan 12, 2022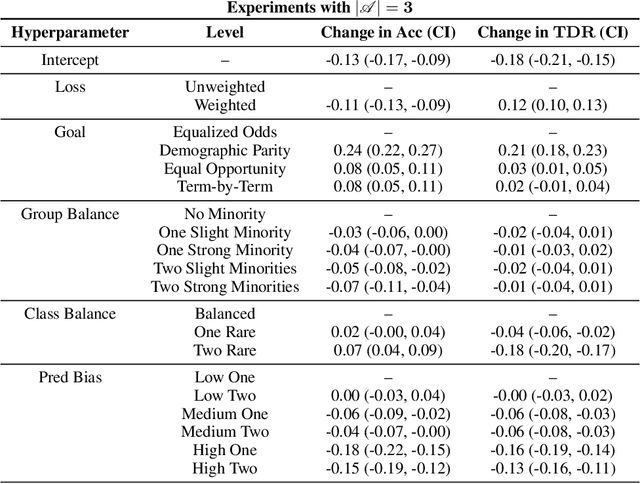
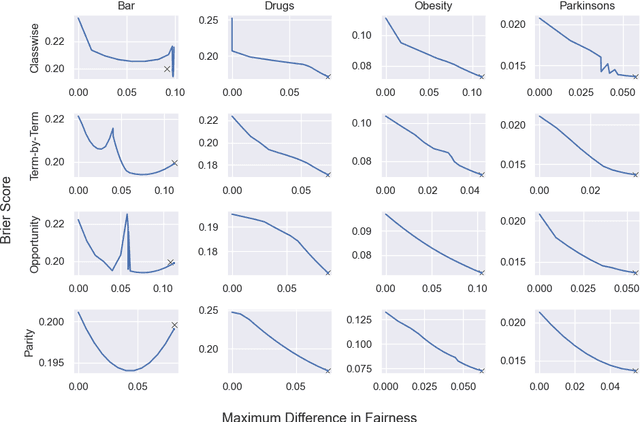
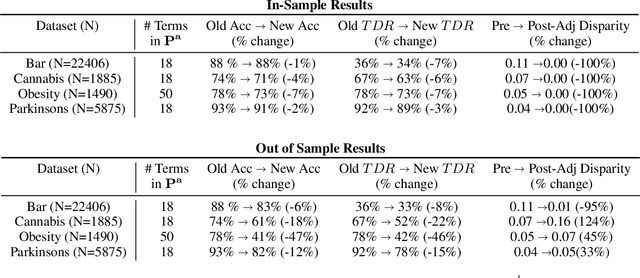
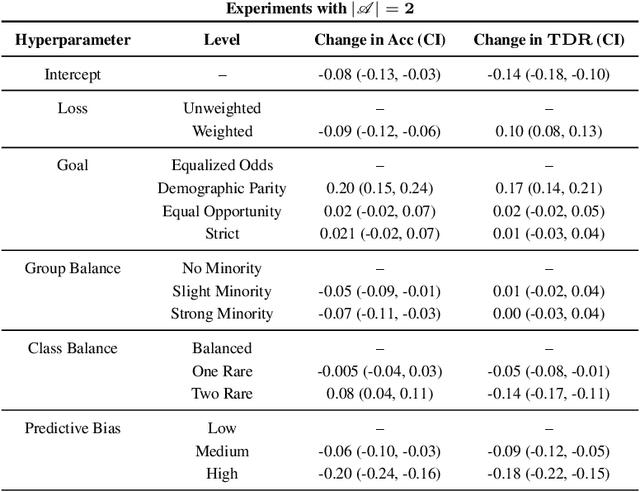
Applying standard machine learning approaches for classification can produce unequal results across different demographic groups. When then used in real-world settings, these inequities can have negative societal impacts. This has motivated the development of various approaches to fair classification with machine learning models in recent years. In this paper, we consider the problem of modifying the predictions of a blackbox machine learning classifier in order to achieve fairness in a multiclass setting. To accomplish this, we extend the 'post-processing' approach in Hardt et al. 2016, which focuses on fairness for binary classification, to the setting of fair multiclass classification. We explore when our approach produces both fair and accurate predictions through systematic synthetic experiments and also evaluate discrimination-fairness tradeoffs on several publicly available real-world application datasets. We find that overall, our approach produces minor drops in accuracy and enforces fairness when the number of individuals in the dataset is high relative to the number of classes and protected groups.
NBDT: Neural-Backed Decision Trees
Apr 01, 2020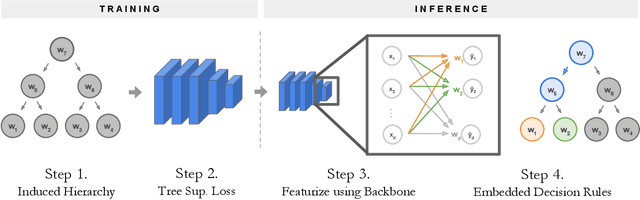
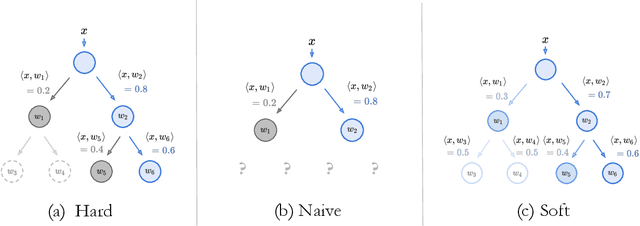
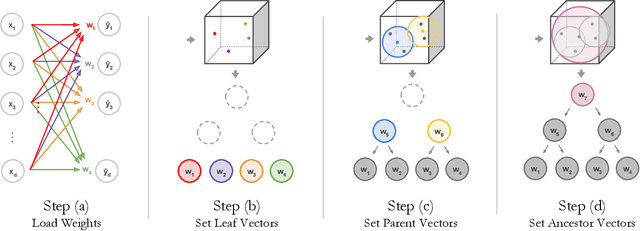

Deep learning is being adopted in settings where accurate and justifiable predictions are required, ranging from finance to medical imaging. While there has been recent work providing post-hoc explanations for model predictions, there has been relatively little work exploring more directly interpretable models that can match state-of-the-art accuracy. Historically, decision trees have been the gold standard in balancing interpretability and accuracy. However, recent attempts to combine decision trees with deep learning have resulted in models that (1) achieve accuracies far lower than that of modern neural networks (e.g. ResNet) even on small datasets (e.g. MNIST), and (2) require significantly different architectures, forcing practitioners pick between accuracy and interpretability. We forgo this dilemma by creating Neural-Backed Decision Trees (NBDTs) that (1) achieve neural network accuracy and (2) require no architectural changes to a neural network. NBDTs achieve accuracy within 1% of the base neural network on CIFAR10, CIFAR100, TinyImageNet, using recently state-of-the-art WideResNet; and within 2% of EfficientNet on ImageNet. This yields state-of-the-art explainable models on ImageNet, with NBDTs improving the baseline by ~14% to 75.30% top-1 accuracy. Furthermore, we show interpretability of our model's decisions both qualitatively and quantitatively via a semi-automatic process. Code and pretrained NBDTs can be found at https://github.com/alvinwan/neural-backed-decision-trees.
The Many AI Challenges of Hearthstone
Jul 15, 2019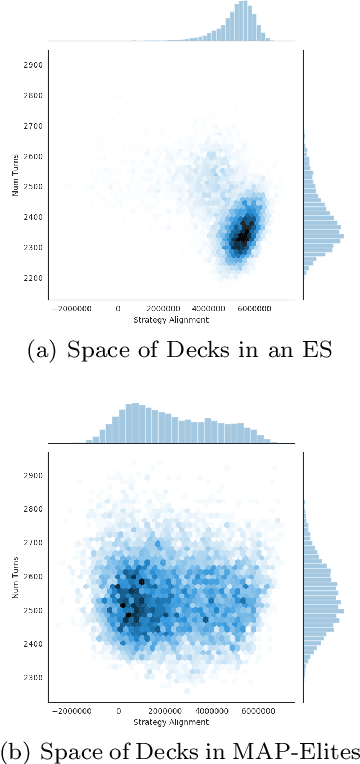
Games have benchmarked AI methods since the inception of the field, with classic board games such as Chess and Go recently leaving room for video games with related yet different sets of challenges. The set of AI problems associated with video games has in recent decades expanded from simply playing games to win, to playing games in particular styles, generating game content, modeling players etc. Different games pose very different challenges for AI systems, and several different AI challenges can typically be posed by the same game. In this article we analyze the popular collectible card game Hearthstone (Blizzard 2014) and describe a varied set of interesting AI challenges posed by this game. Collectible card games are relatively understudied in the AI community, despite their popularity and the interesting challenges they pose. Analyzing a single game in-depth in the manner we do here allows us to see the entire field of AI and Games through the lens of a single game, discovering a few new variations on existing research topics.
Evolving the Hearthstone Meta
Jul 02, 2019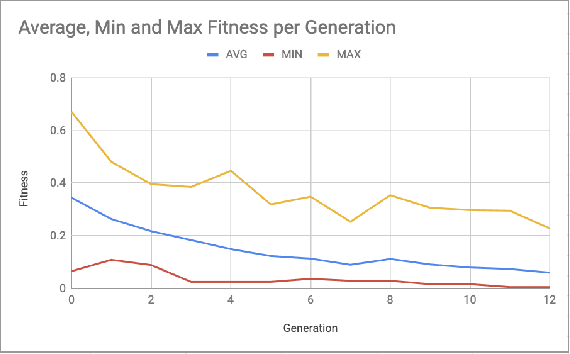
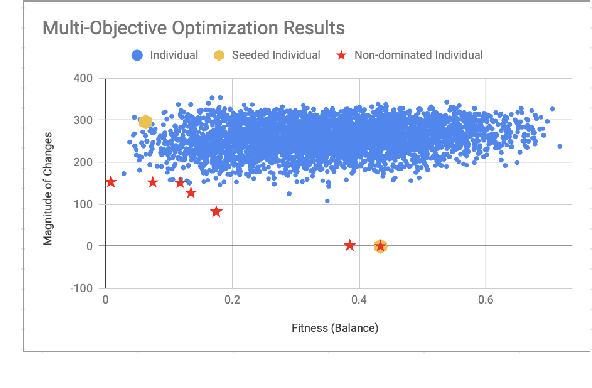
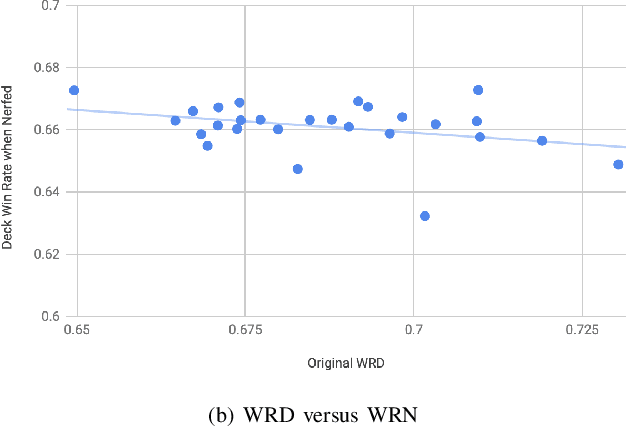
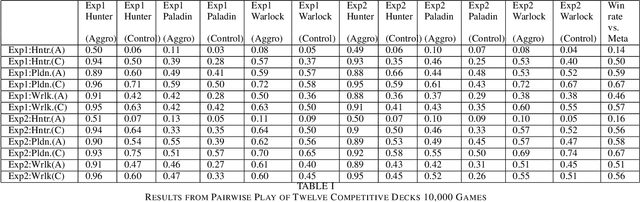
Balancing an ever growing strategic game of high complexity, such as Hearthstone is a complex task. The target of making strategies diverse and customizable results in a delicate intricate system. Tuning over 2000 cards to generate the desired outcome without disrupting the existing environment becomes a laborious challenge. In this paper, we discuss the impacts that changes to existing cards can have on strategy in Hearthstone. By analyzing the win rate on match-ups across different decks, being played by different strategies, we propose to compare their performance before and after changes are made to improve or worsen different cards. Then, using an evolutionary algorithm, we search for a combination of changes to the card attributes that cause the decks to approach equal, 50% win rates. We then expand our evolutionary algorithm to a multi-objective solution to search for this result, while making the minimum amount of changes, and as a consequence disruption, to the existing cards. Lastly, we propose and evaluate metrics to serve as heuristics with which to decide which cards to target with balance changes.
Mapping Hearthstone Deck Spaces through MAP-Elites with Sliding Boundaries
Apr 24, 2019
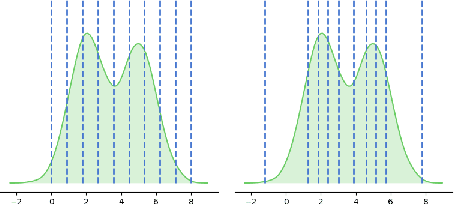
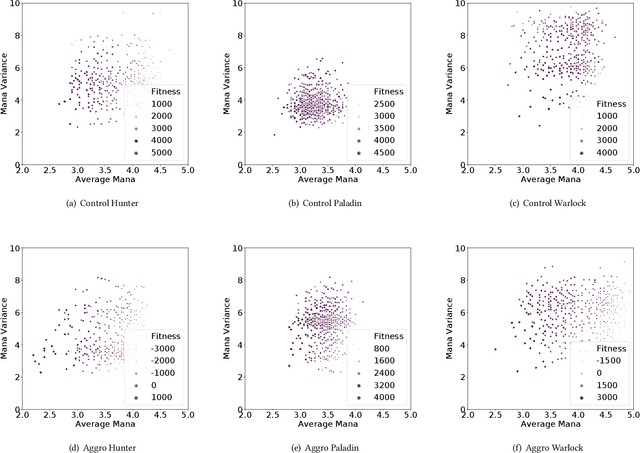
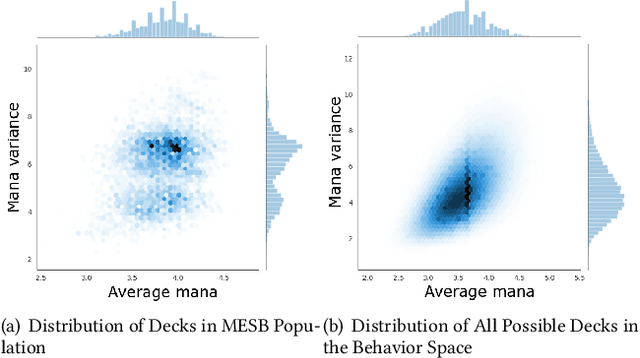
Quality diversity (QD) algorithms such as MAP-Elites have emerged as a powerful alternative to traditional single-objective optimization methods. They were initially applied to evolutionary robotics problems such as locomotion and maze navigation, but have yet to see widespread application. We argue that these algorithms are perfectly suited to the rich domain of video games, which contains many relevant problems with a multitude of successful strategies and often also multiple dimensions along which solutions can vary. This paper introduces a novel modification of the MAP-Elites algorithm called MAP-Elites with Sliding Boundaries (MESB) and applies it to the design and rebalancing of Hearthstone, a popular collectible card game chosen for its number of multidimensional behavior features relevant to particular styles of play. To avoid overpopulating cells with conflated behaviors, MESB slides the boundaries of cells based on the distribution of evolved individuals. Experiments in this paper demonstrate the performance of MESB in Hearthstone. Results suggest MESB finds diverse ways of playing the game well along the selected behavioral dimensions. Further analysis of the evolved strategies reveals common patterns that recur across behavioral dimensions and explores how MESB can help rebalance the game.
Talakat: Bullet Hell Generation through Constrained Map-Elites
Jun 14, 2018
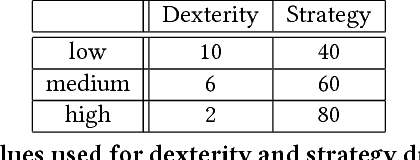

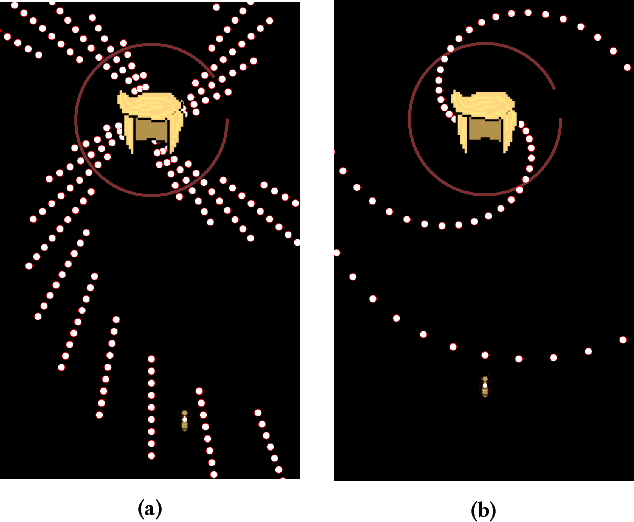
We describe a search-based approach to generating new levels for bullet hell games, which are action games characterized by and requiring avoidance of a very large amount of projectiles. Levels are represented using a domain-specific description language, and search in the space defined by this language is performed by a novel variant of the Map-Elites algorithm which incorporates a feasible- infeasible approach to constraint satisfaction. Simulation-based evaluation is used to gauge the fitness of levels, using an agent based on best-first search. The performance of the agent can be tuned according to the two dimensions of strategy and dexterity, making it possible to search for level configurations that require a specific combination of both. As far as we know, this paper describes the first generator for this game genre, and includes several algorithmic innovations.
Natural Language Generation for Electronic Health Records
Jun 01, 2018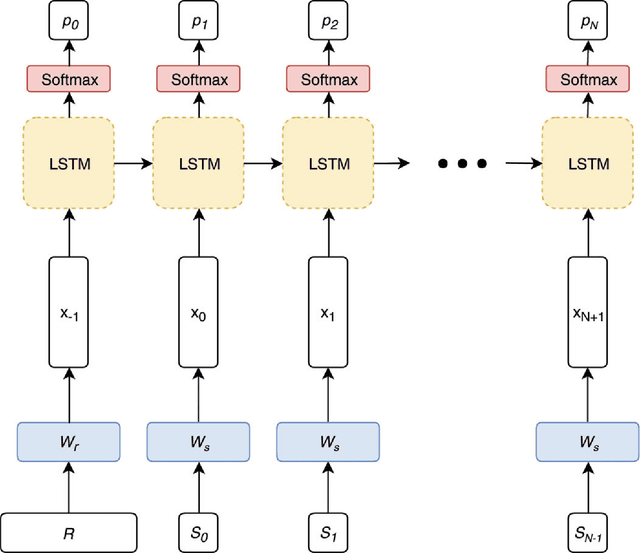
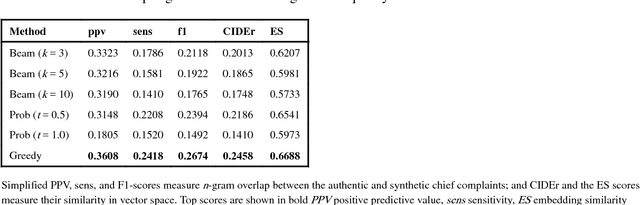
A variety of methods existing for generating synthetic electronic health records (EHRs), but they are not capable of generating unstructured text, like emergency department (ED) chief complaints, history of present illness or progress notes. Here, we use the encoder-decoder model, a deep learning algorithm that features in many contemporary machine translation systems, to generate synthetic chief complaints from discrete variables in EHRs, like age group, gender, and discharge diagnosis. After being trained end-to-end on authentic records, the model can generate realistic chief complaint text that preserves much of the epidemiological information in the original data. As a side effect of the model's optimization goal, these synthetic chief complaints are also free of relatively uncommon abbreviation and misspellings, and they include none of the personally-identifiable information (PII) that was in the training data, suggesting it may be used to support the de-identification of text in EHRs. When combined with algorithms like generative adversarial networks (GANs), our model could be used to generate fully-synthetic EHRs, facilitating data sharing between healthcare providers and researchers and improving our ability to develop machine learning methods tailored to the information in healthcare data.