 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Representation Bending for Large Language Model Safety
Apr 02, 2025Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
The Super Weight in Large Language Models
Nov 11, 2024
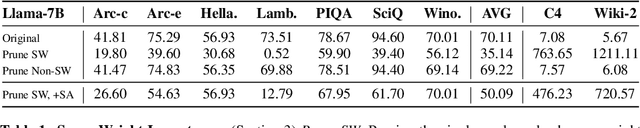
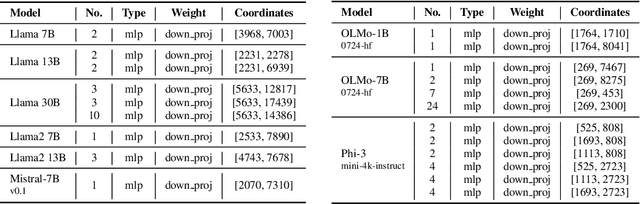

Recent works have shown a surprising result: a small fraction of Large Language Model (LLM) parameter outliers are disproportionately important to the quality of the model. LLMs contain billions of parameters, so these small fractions, such as 0.01%, translate to hundreds of thousands of parameters. In this work, we present an even more surprising finding: Pruning as few as a single parameter can destroy an LLM's ability to generate text -- increasing perplexity by 3 orders of magnitude and reducing zero-shot accuracy to guessing. We propose a data-free method for identifying such parameters, termed super weights, using a single forward pass through the model. We additionally find that these super weights induce correspondingly rare and large activation outliers, termed super activations. When preserved with high precision, super activations can improve simple round-to-nearest quantization to become competitive with state-of-the-art methods. For weight quantization, we similarly find that by preserving the super weight and clipping other weight outliers, round-to-nearest quantization can scale to much larger block sizes than previously considered. To facilitate further research into super weights, we provide an index of super weight coordinates for common, openly available LLMs.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
UPSCALE: Unconstrained Channel Pruning
Jul 17, 2023As neural networks grow in size and complexity, inference speeds decline. To combat this, one of the most effective compression techniques -- channel pruning -- removes channels from weights. However, for multi-branch segments of a model, channel removal can introduce inference-time memory copies. In turn, these copies increase inference latency -- so much so that the pruned model can be slower than the unpruned model. As a workaround, pruners conventionally constrain certain channels to be pruned together. This fully eliminates memory copies but, as we show, significantly impairs accuracy. We now have a dilemma: Remove constraints but increase latency, or add constraints and impair accuracy. In response, our insight is to reorder channels at export time, (1) reducing latency by reducing memory copies and (2) improving accuracy by removing constraints. Using this insight, we design a generic algorithm UPSCALE to prune models with any pruning pattern. By removing constraints from existing pruners, we improve ImageNet accuracy for post-training pruned models by 2.1 points on average -- benefiting DenseNet (+16.9), EfficientNetV2 (+7.9), and ResNet (+6.2). Furthermore, by reordering channels, UPSCALE improves inference speeds by up to 2x over a baseline export.
AutoFocusFormer: Image Segmentation off the Grid
Apr 24, 2023Real world images often have highly imbalanced content density. Some areas are very uniform, e.g., large patches of blue sky, while other areas are scattered with many small objects. Yet, the commonly used successive grid downsampling strategy in convolutional deep networks treats all areas equally. Hence, small objects are represented in very few spatial locations, leading to worse results in tasks such as segmentation. Intuitively, retaining more pixels representing small objects during downsampling helps to preserve important information. To achieve this, we propose AutoFocusFormer (AFF), a local-attention transformer image recognition backbone, which performs adaptive downsampling by learning to retain the most important pixels for the task. Since adaptive downsampling generates a set of pixels irregularly distributed on the image plane, we abandon the classic grid structure. Instead, we develop a novel point-based local attention block, facilitated by a balanced clustering module and a learnable neighborhood merging module, which yields representations for our point-based versions of state-of-the-art segmentation heads. Experiments show that our AutoFocusFormer (AFF) improves significantly over baseline models of similar sizes.
CathAI: Fully Automated Interpretation of Coronary Angiograms Using Neural Networks
Jun 14, 2021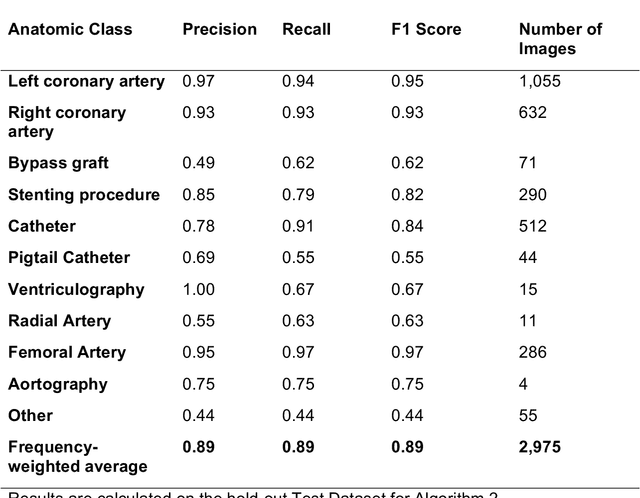
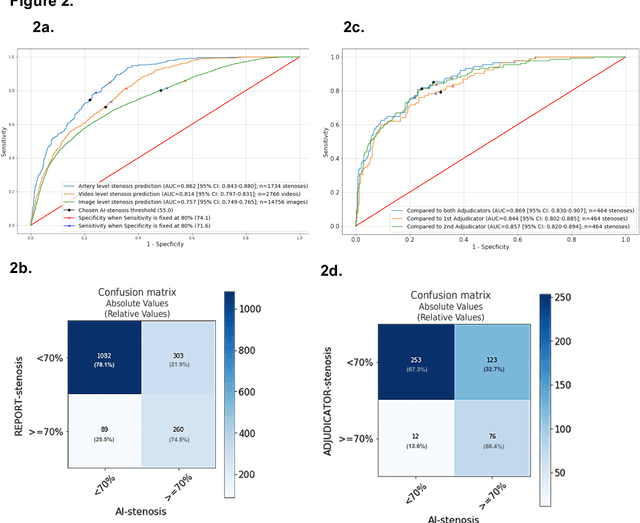
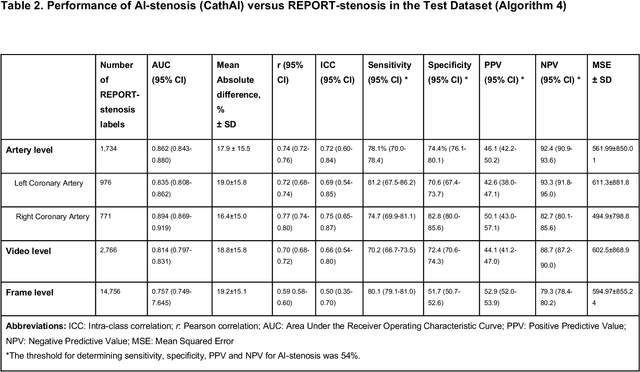
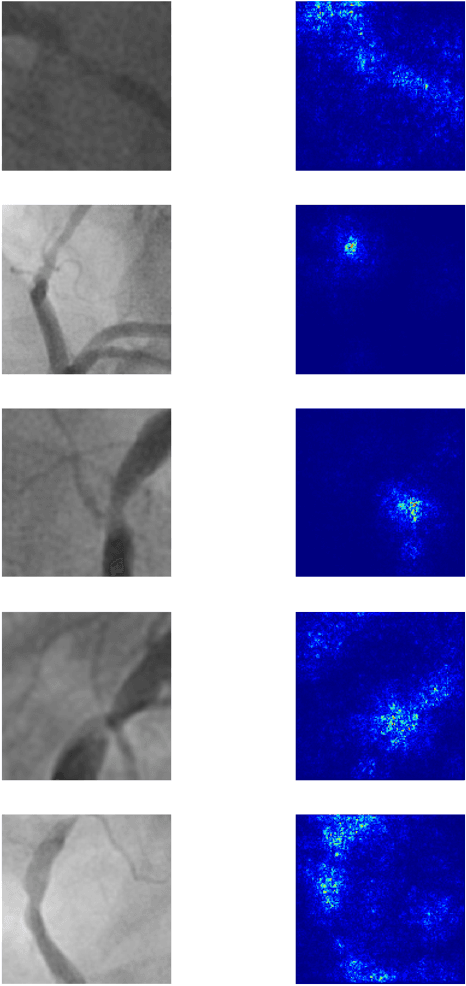
Coronary heart disease (CHD) is the leading cause of adult death in the United States and worldwide, and for which the coronary angiography procedure is the primary gateway for diagnosis and clinical management decisions. The standard-of-care for interpretation of coronary angiograms depends upon ad-hoc visual assessment by the physician operator. However, ad-hoc visual interpretation of angiograms is poorly reproducible, highly variable and bias prone. Here we show for the first time that fully-automated angiogram interpretation to estimate coronary artery stenosis is possible using a sequence of deep neural network algorithms. The algorithmic pipeline we developed--called CathAI--achieves state-of-the art performance across the sequence of tasks required to accomplish automated interpretation of unselected, real-world angiograms. CathAI (Algorithms 1-2) demonstrated positive predictive value, sensitivity and F1 score of >=90% to identify the projection angle overall and >=93% for left or right coronary artery angiogram detection, the primary anatomic structures of interest. To predict obstructive coronary artery stenosis (>=70% stenosis), CathAI (Algorithm 4) exhibited an area under the receiver operating characteristic curve (AUC) of 0.862 (95% CI: 0.843-0.880). When externally validated in a healthcare system in another country, CathAI AUC was 0.869 (95% CI: 0.830-0.907) to predict obstructive coronary artery stenosis. Our results demonstrate that multiple purpose-built neural networks can function in sequence to accomplish the complex series of tasks required for automated analysis of real-world angiograms. Deployment of CathAI may serve to increase standardization and reproducibility in coronary stenosis assessment, while providing a robust foundation to accomplish future tasks for algorithmic angiographic interpretation.
Visual Transformers: Token-based Image Representation and Processing for Computer Vision
Jul 02, 2020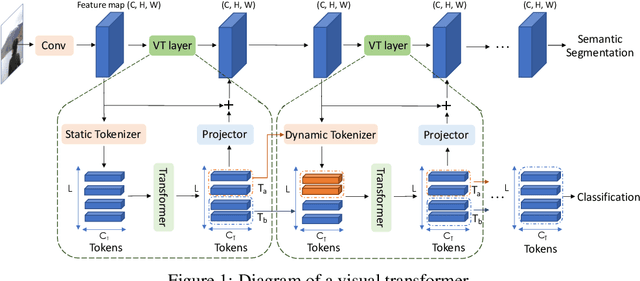
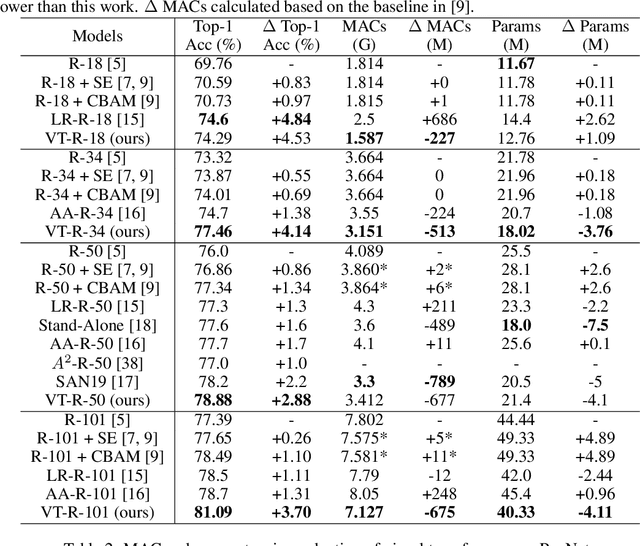
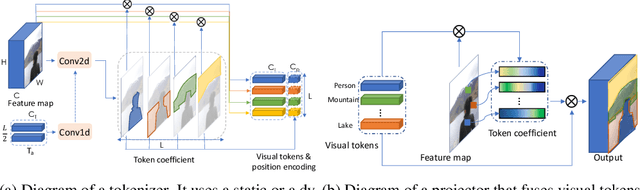

Computer vision has achieved great success using standardized image representations -- pixel arrays, and the corresponding deep learning operators -- convolutions. In this work, we challenge this paradigm: we instead (a) represent images as a set of visual tokens and (b) apply visual transformers to find relationships between visual semantic concepts. Given an input image, we dynamically extract a set of visual tokens from the image to obtain a compact representation for high-level semantics. We then use visual transformers to operate over the visual tokens to densely model relationships between them. We find that this paradigm of token-based image representation and processing drastically outperforms its convolutional counterparts on image classification and semantic segmentation. To demonstrate the power of this approach on ImageNet classification, we use ResNet as a convenient baseline and use visual transformers to replace the last stage of convolutions. This reduces the stage's MACs by up to 6.9x, while attaining up to 4.53 points higher top-1 accuracy. For semantic segmentation, we use a visual-transformer-based FPN (VT-FPN) module to replace a convolution-based FPN, saving 6.5x fewer MACs while achieving up to 0.35 points higher mIoU on LIP and COCO-stuff.
SegNBDT: Visual Decision Rules for Segmentation
Jun 11, 2020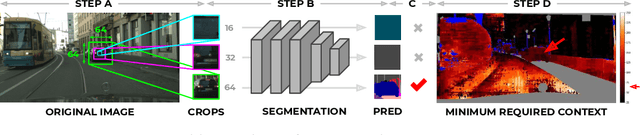


The black-box nature of neural networks limits model decision interpretability, in particular for high-dimensional inputs in computer vision and for dense pixel prediction tasks like segmentation. To address this, prior work combines neural networks with decision trees. However, such models (1) perform poorly when compared to state-of-the-art segmentation models or (2) fail to produce decision rules with spatially-grounded semantic meaning. In this work, we build a hybrid neural-network and decision-tree model for segmentation that (1) attains neural network segmentation accuracy and (2) provides semi-automatically constructed visual decision rules such as "Is there a window?". We obtain semantic visual meaning by extending saliency methods to segmentation and attain accuracy by leveraging insights from neural-backed decision trees, a deep learning analog of decision trees for image classification. Our model SegNBDT attains accuracy within ~2-4% of the state-of-the-art HRNetV2 segmentation model while also retaining explainability; we achieve state-of-the-art performance for explainable models on three benchmark datasets -- Pascal-Context (49.12%), Cityscapes (79.01%), and Look Into Person (51.64%). Furthermore, user studies suggest visual decision rules are more interpretable, particularly for incorrect predictions. Code and pretrained models can be found at https://github.com/daniel-ho/SegNBDT.
FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function
Jun 07, 2020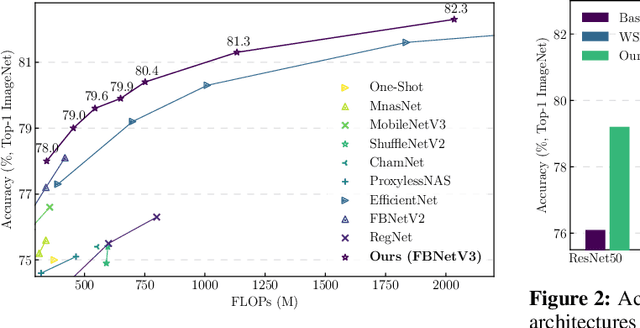
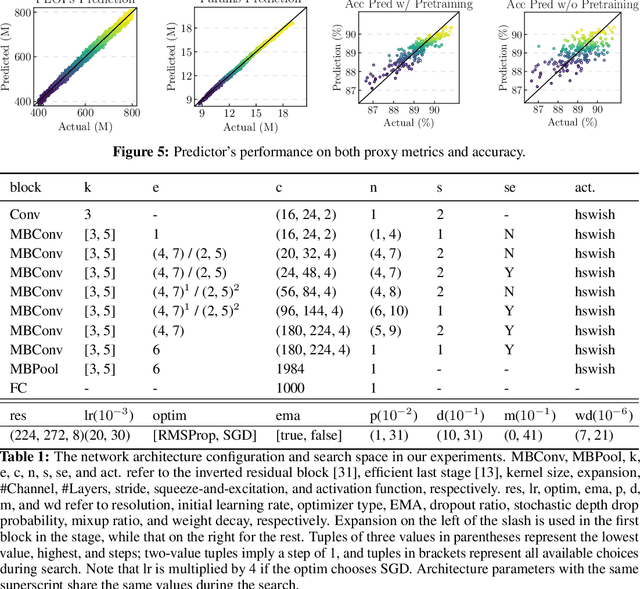
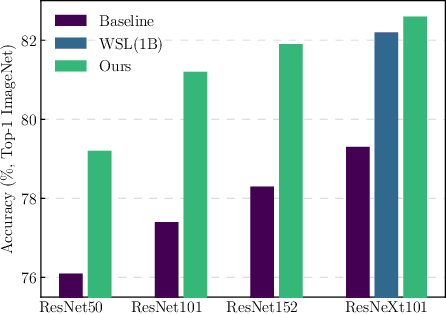

Neural Architecture Search (NAS) yields state-of-the-art neural networks that outperform their best manually-designed counterparts. However, previous NAS methods search for architectures under one training recipe (i.e., training hyperparameters), ignoring the significance of training recipes and overlooking superior architectures under other training recipes. Thus, they fail to find higher-accuracy architecture-recipe combinations. To address this oversight, we present JointNAS to search both (a) architectures and (b) their corresponding training recipes. To accomplish this, we introduce a neural acquisition function that scores architectures and training recipes jointly. Following pre-training on a proxy dataset, this acquisition function guides both coarse-grained and fine-grained searches to produce FBNetV3. FBNetV3 is a family of state-of-the-art compact ImageNet models, outperforming both automatically and manually-designed architectures. For example, FBNetV3 matches both EfficientNet and ResNeSt accuracy with 1.4x and 5.0x fewer FLOPs, respectively. Furthermore, the JointNAS-searched training recipe yields significant performance gains across different networks and tasks.