 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Non-Monotonic Attention-based Read/Write Policy Learning for Simultaneous Translation
Mar 28, 2025Simultaneous or streaming machine translation generates translation while reading the input stream. These systems face a quality/latency trade-off, aiming to achieve high translation quality similar to non-streaming models with minimal latency. We propose an approach that efficiently manages this trade-off. By enhancing a pretrained non-streaming model, which was trained with a seq2seq mechanism and represents the upper bound in quality, we convert it into a streaming model by utilizing the alignment between source and target tokens. This alignment is used to learn a read/write decision boundary for reliable translation generation with minimal input. During training, the model learns the decision boundary through a read/write policy module, employing supervised learning on the alignment points (pseudo labels). The read/write policy module, a small binary classification unit, can control the quality/latency trade-off during inference. Experimental results show that our model outperforms several strong baselines and narrows the gap with the non-streaming baseline model.
Transcribing and Translating, Fast and Slow: Joint Speech Translation and Recognition
Dec 19, 2024We propose the joint speech translation and recognition (JSTAR) model that leverages the fast-slow cascaded encoder architecture for simultaneous end-to-end automatic speech recognition (ASR) and speech translation (ST). The model is transducer-based and uses a multi-objective training strategy that optimizes both ASR and ST objectives simultaneously. This allows JSTAR to produce high-quality streaming ASR and ST results. We apply JSTAR in a bilingual conversational speech setting with smart-glasses, where the model is also trained to distinguish speech from different directions corresponding to the wearer and a conversational partner. Different model pre-training strategies are studied to further improve results, including training of a transducer-based streaming machine translation (MT) model for the first time and applying it for parameter initialization of JSTAR. We demonstrate superior performances of JSTAR compared to a strong cascaded ST model in both BLEU scores and latency.
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Evaluating probabilistic and data-driven inference models for fiber-coupled NV-diamond temperature sensors
Sep 14, 2024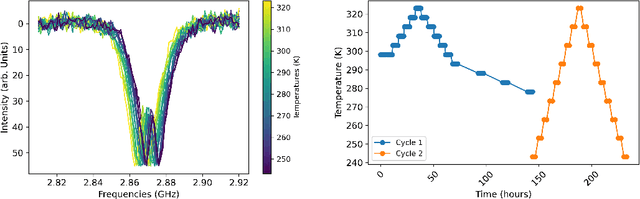
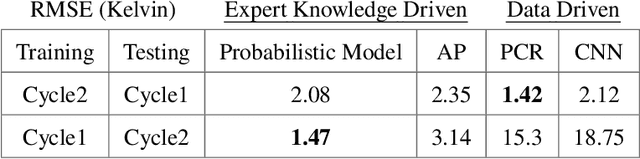
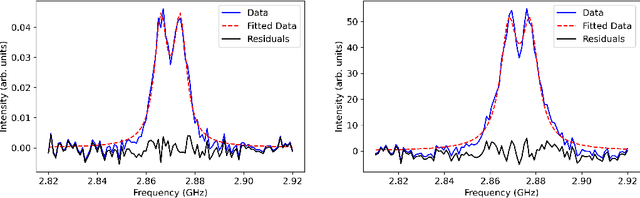
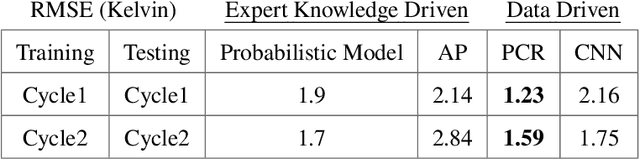
We evaluate the impact of inference model on uncertainties when using continuous wave Optically Detected Magnetic Resonance (ODMR) measurements to infer temperature. Our approach leverages a probabilistic feedforward inference model designed to maximize the likelihood of observed ODMR spectra through automatic differentiation. This model effectively utilizes the temperature dependence of spin Hamiltonian parameters to infer temperature from spectral features in the ODMR data. We achieve prediction uncertainty of $\pm$ 1 K across a temperature range of 243 K to 323 K. To benchmark our probabilistic model, we compare it with a non-parametric peak-finding technique and data-driven methodologies such as Principal Component Regression (PCR) and a 1D Convolutional Neural Network (CNN). We find that when validated against out-of-sample dataset that encompasses the same temperature range as the training dataset, data driven methods can show uncertainties that are as much as 0.67 K lower without incorporating expert-level understanding of the spectroscopic-temperature relationship. However, our results show that the probabilistic model outperforms both PCR and CNN when tasked with extrapolating beyond the temperature range used in training set, indicating robustness and generalizability. In contrast, data-driven methods like PCR and CNN demonstrate up to ten times worse uncertainties when tasked with extrapolating outside their training data range.
Recovering from Privacy-Preserving Masking with Large Language Models
Sep 23, 2023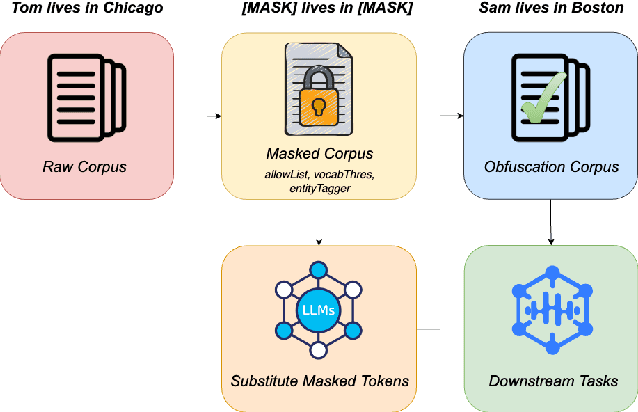
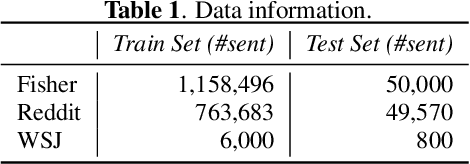
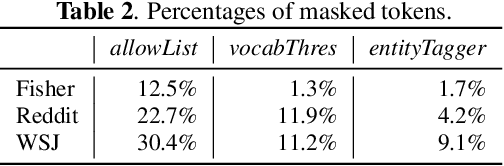
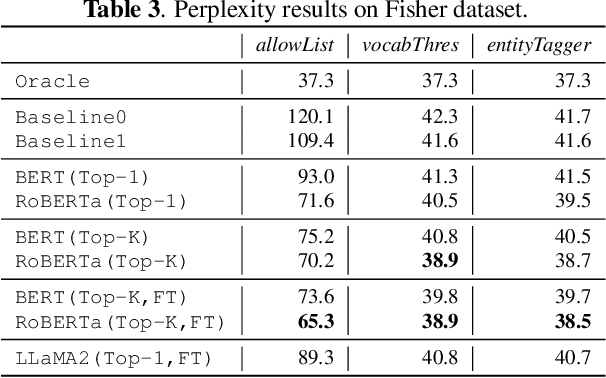
Model adaptation is crucial to handle the discrepancy between proxy training data and actual users data received. To effectively perform adaptation, textual data of users is typically stored on servers or their local devices, where downstream natural language processing (NLP) models can be directly trained using such in-domain data. However, this might raise privacy and security concerns due to the extra risks of exposing user information to adversaries. Replacing identifying information in textual data with a generic marker has been recently explored. In this work, we leverage large language models (LLMs) to suggest substitutes of masked tokens and have their effectiveness evaluated on downstream language modeling tasks. Specifically, we propose multiple pre-trained and fine-tuned LLM-based approaches and perform empirical studies on various datasets for the comparison of these methods. Experimental results show that models trained on the obfuscation corpora are able to achieve comparable performance with the ones trained on the original data without privacy-preserving token masking.
Contextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023



This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Nostradamus: Weathering Worth
Dec 08, 2022Nostradamus, inspired by the French astrologer and reputed seer, is a detailed study exploring relations between environmental factors and changes in the stock market. In this paper, we analyze associative correlation and causation between environmental elements and stock prices based on the US financial market, global climate trends, and daily weather records to demonstrate significant relationships between climate and stock price fluctuation. Our analysis covers short and long-term rises and dips in company stock performances. Lastly, we take four natural disasters as a case study to observe their effect on the emotional state of people and their influence on the stock market.
CUE Vectors: Modular Training of Language Models Conditioned on Diverse Contextual Signals
Mar 16, 2022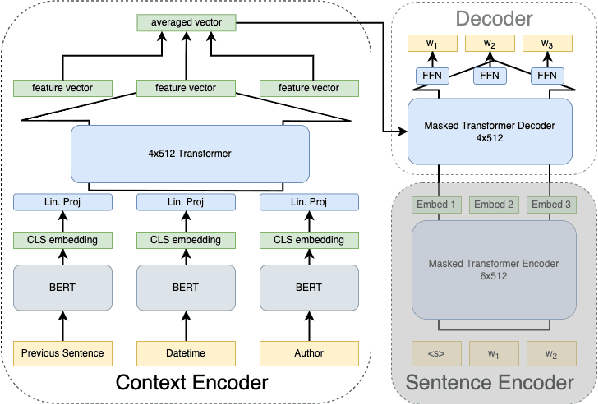
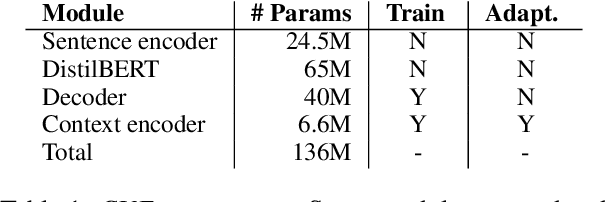

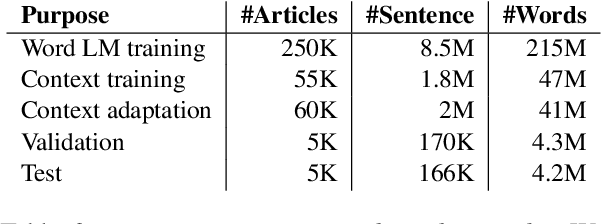
We propose a framework to modularize the training of neural language models that use diverse forms of sentence-external context (including metadata) by eliminating the need to jointly train sentence-external and within-sentence encoders. Our approach, contextual universal embeddings (CUE), trains LMs on one set of context, such as date and author, and adapts to novel metadata types, such as article title, or previous sentence. The model consists of a pretrained neural sentence LM, a BERT-based context encoder, and a masked transformer decoder that estimates LM probabilities using sentence-internal and sentence-external information. When context or metadata are unavailable, our model learns to combine contextual and sentence-internal information using noisy oracle unigram embeddings as a proxy. Real contextual information can be introduced later and used to adapt a small number of parameters that map contextual data into the decoder's embedding space. We validate the CUE framework on a NYTimes text corpus with multiple metadata types, for which the LM perplexity can be lowered from 36.6 to 27.4 by conditioning on context. Bootstrapping a contextual LM with only a subset of the context/metadata during training retains 85\% of the achievable gain. Training the model initially with proxy context retains 67% of the perplexity gain after adapting to real context. Furthermore, we can swap one type of pretrained sentence LM for another without retraining the context encoders, by only adapting the decoder model. Overall, we obtain a modular framework that allows incremental, scalable training of context-enhanced LMs.
Mitigating Closed-model Adversarial Examples with Bayesian Neural Modeling for Enhanced End-to-End Speech Recognition
Feb 17, 2022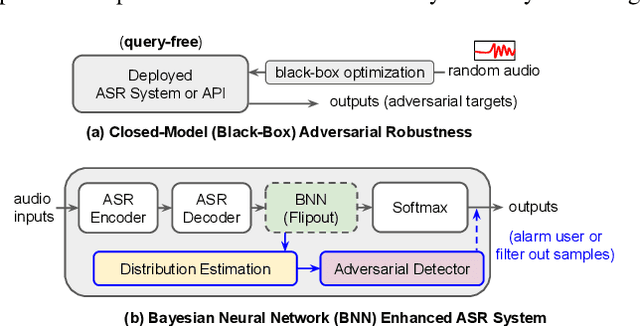

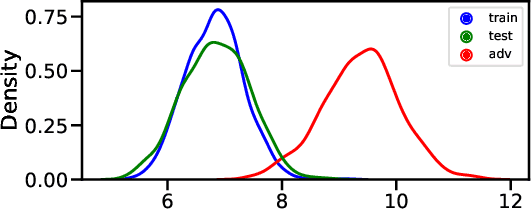
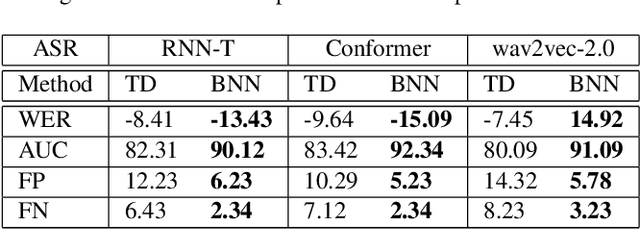
In this work, we aim to enhance the system robustness of end-to-end automatic speech recognition (ASR) against adversarially-noisy speech examples. We focus on a rigorous and empirical "closed-model adversarial robustness" setting (e.g., on-device or cloud applications). The adversarial noise is only generated by closed-model optimization (e.g., evolutionary and zeroth-order estimation) without accessing gradient information of a targeted ASR model directly. We propose an advanced Bayesian neural network (BNN) based adversarial detector, which could model latent distributions against adaptive adversarial perturbation with divergence measurement. We further simulate deployment scenarios of RNN Transducer, Conformer, and wav2vec-2.0 based ASR systems with the proposed adversarial detection system. Leveraging the proposed BNN based detection system, we improve detection rate by +2.77 to +5.42% (relative +3.03 to +6.26%) and reduce the word error rate by 5.02 to 7.47% on LibriSpeech datasets compared to the current model enhancement methods against the adversarial speech examples.