 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Get Large Language Models Ready to Speak: A Late-fusion Approach for Speech Generation
Oct 27, 2024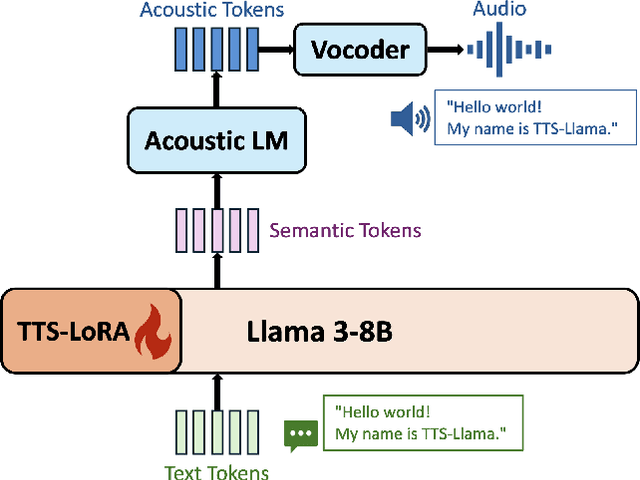
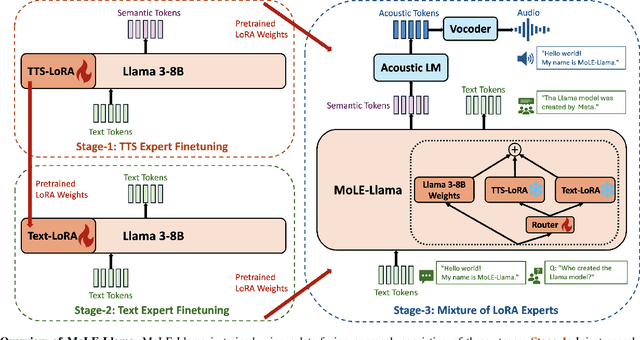
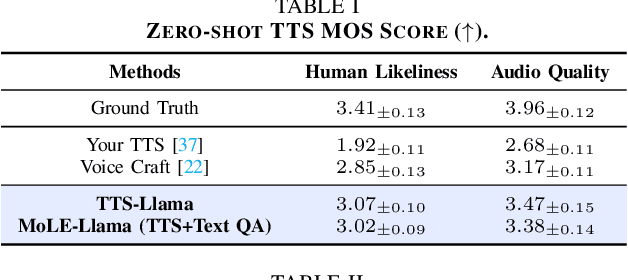
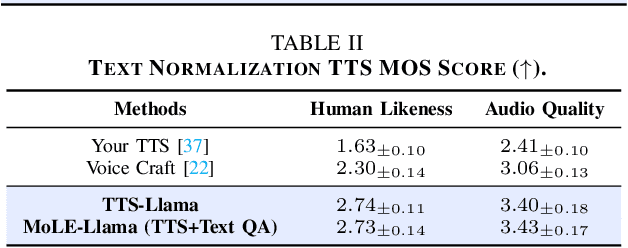
Large language models (LLMs) have revolutionized natural language processing (NLP) with impressive performance across various text-based tasks. However, the extension of text-dominant LLMs to with speech generation tasks remains under-explored. In this work, we introduce a text-to-speech (TTS) system powered by a fine-tuned Llama model, named TTS-Llama, that achieves state-of-the-art speech synthesis performance. Building on TTS-Llama, we further propose MoLE-Llama, a text-and-speech multimodal LLM developed through purely late-fusion parameter-efficient fine-tuning (PEFT) and a mixture-of-expert architecture. Extensive empirical results demonstrate MoLE-Llama's competitive performance on both text-only question-answering (QA) and TTS tasks, mitigating catastrophic forgetting issue in either modality. Finally, we further explore MoLE-Llama in text-in-speech-out QA tasks, demonstrating its great potential as a multimodal dialog system capable of speech generation.
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Ultra-lightweight Neural Differential DSP Vocoder For High Quality Speech Synthesis
Jan 19, 2024



Neural vocoders model the raw audio waveform and synthesize high-quality audio, but even the highly efficient ones, like MB-MelGAN and LPCNet, fail to run real-time on a low-end device like a smartglass. A pure digital signal processing (DSP) based vocoder can be implemented via lightweight fast Fourier transforms (FFT), and therefore, is a magnitude faster than any neural vocoder. A DSP vocoder often gets a lower audio quality due to consuming over-smoothed acoustic model predictions of approximate representations for the vocal tract. In this paper, we propose an ultra-lightweight differential DSP (DDSP) vocoder that uses a jointly optimized acoustic model with a DSP vocoder, and learns without an extracted spectral feature for the vocal tract. The model achieves audio quality comparable to neural vocoders with a high average MOS of 4.36 while being efficient as a DSP vocoder. Our C++ implementation, without any hardware-specific optimization, is at 15 MFLOPS, surpasses MB-MelGAN by 340 times in terms of FLOPS, and achieves a vocoder-only RTF of 0.003 and overall RTF of 0.044 while running single-threaded on a 2GHz Intel Xeon CPU.
Multi-rate attention architecture for fast streamable Text-to-speech spectrum modeling
Apr 01, 2021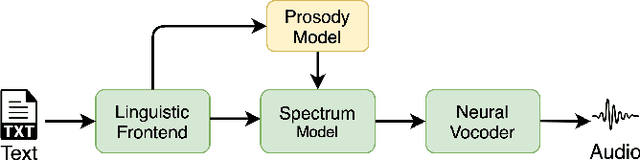
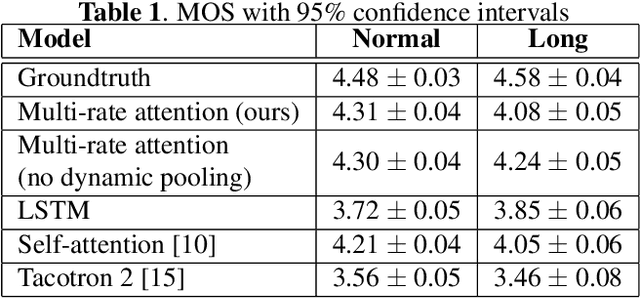
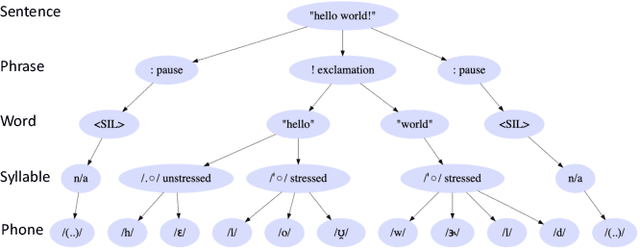
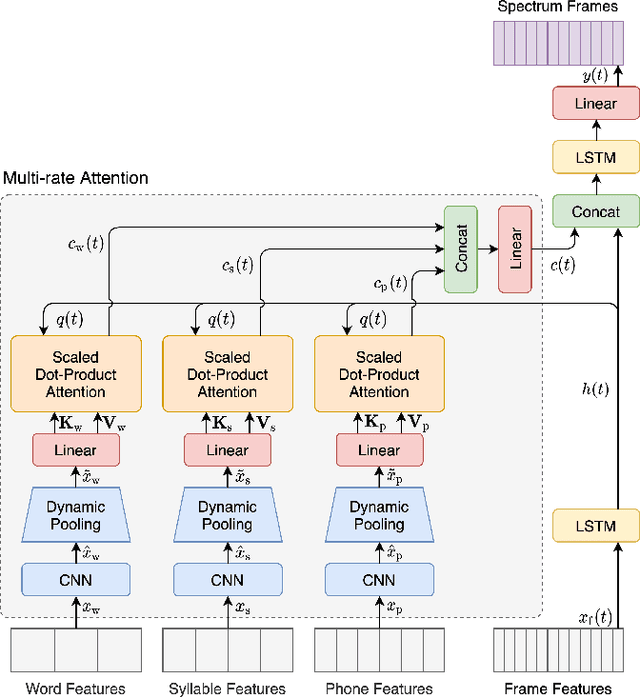
Typical high quality text-to-speech (TTS) systems today use a two-stage architecture, with a spectrum model stage that generates spectral frames and a vocoder stage that generates the actual audio. High-quality spectrum models usually incorporate the encoder-decoder architecture with self-attention or bi-directional long short-term (BLSTM) units. While these models can produce high quality speech, they often incur O($L$) increase in both latency and real-time factor (RTF) with respect to input length $L$. In other words, longer inputs leads to longer delay and slower synthesis speed, limiting its use in real-time applications. In this paper, we propose a multi-rate attention architecture that breaks the latency and RTF bottlenecks by computing a compact representation during encoding and recurrently generating the attention vector in a streaming manner during decoding. The proposed architecture achieves high audio quality (MOS of 4.31 compared to groundtruth 4.48), low latency, and low RTF at the same time. Meanwhile, both latency and RTF of the proposed system stay constant regardless of input lengths, making it ideal for real-time applications.