 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025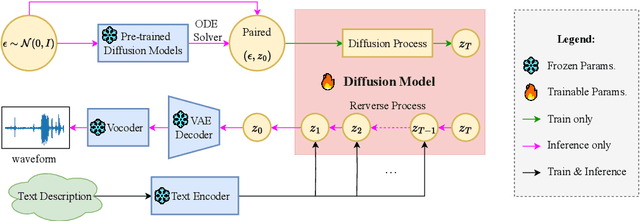
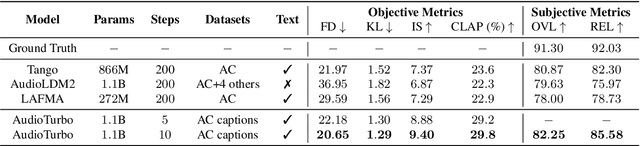
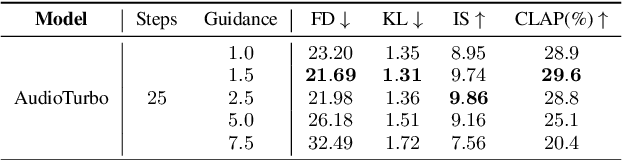
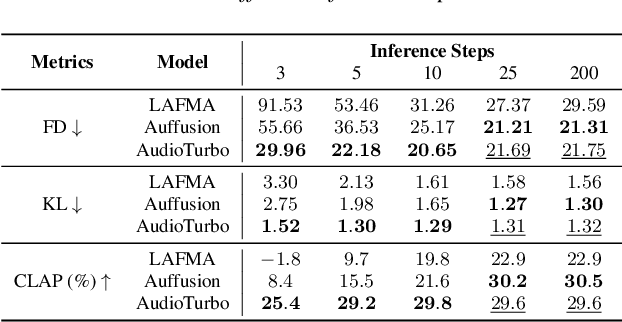
Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.
Audio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Universal Sound Separation with Self-Supervised Audio Masked Autoencoder
Jul 16, 2024Universal sound separation (USS) is a task of separating mixtures of arbitrary sound sources. Typically, universal separation models are trained from scratch in a supervised manner, using labeled data. Self-supervised learning (SSL) is an emerging deep learning approach that leverages unlabeled data to obtain task-agnostic representations, which can benefit many downstream tasks. In this paper, we propose integrating a self-supervised pre-trained model, namely the audio masked autoencoder (A-MAE), into a universal sound separation system to enhance its separation performance. We employ two strategies to utilize SSL embeddings: freezing or updating the parameters of A-MAE during fine-tuning. The SSL embeddings are concatenated with the short-time Fourier transform (STFT) to serve as input features for the separation model. We evaluate our methods on the AudioSet dataset, and the experimental results indicate that the proposed methods successfully enhance the separation performance of a state-of-the-art ResUNet-based USS model.
Text-Queried Target Sound Event Localization
Jun 23, 2024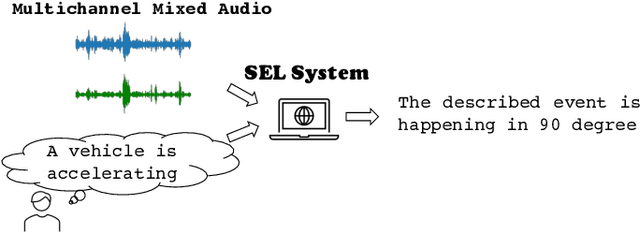
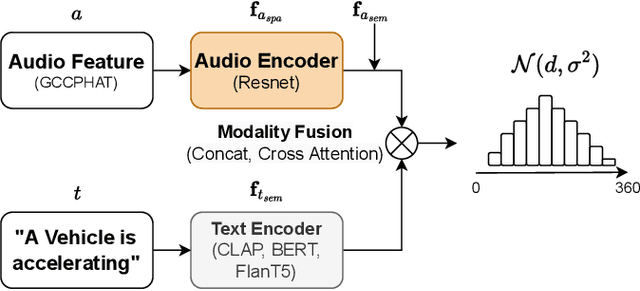
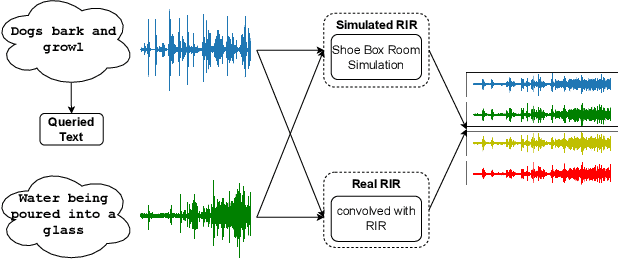
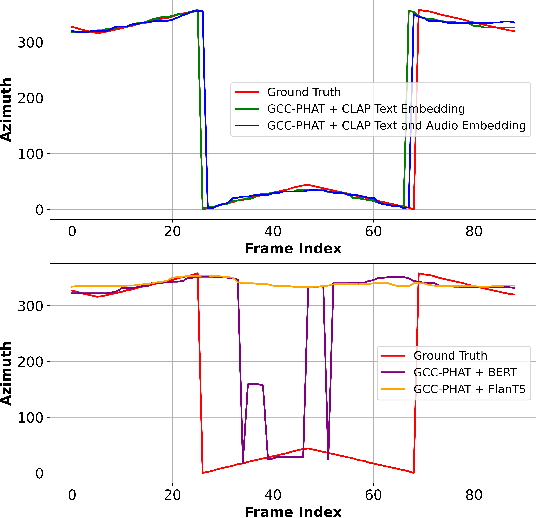
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
Fish Tracking, Counting, and Behaviour Analysis in Digital Aquaculture: A Comprehensive Review
Jun 20, 2024Digital aquaculture leverages advanced technologies and data-driven methods, providing substantial benefits over traditional aquaculture practices. Fish tracking, counting, and behaviour analysis are crucial components of digital aquaculture, which are essential for optimizing production efficiency, enhancing fish welfare, and improving resource management. Previous reviews have focused on single modalities, limiting their ability to address the diverse challenges encountered in these tasks comprehensively. This review provides a comprehensive analysis of the current state of aquaculture digital technologies, including vision-based, acoustic-based, and biosensor-based methods. We examine the advantages, limitations, and applications of these methods, highlighting recent advancements and identifying critical research gaps. The scarcity of comprehensive fish datasets and the lack of unified evaluation standards, which make it difficult to compare the performance of different technologies, are identified as major obstacles hindering progress in this field. To overcome current limitations and improve the accuracy, robustness, and efficiency of fish monitoring systems, we explore the potential of emerging technologies such as multimodal data fusion and deep learning. Additionally, we contribute to the field by providing a summary of existing datasets available for fish tracking, counting, and behaviour analysis. Future research directions are outlined, emphasizing the need for comprehensive datasets and evaluation standards to facilitate meaningful comparisons between technologies and promote their practical implementation in real-world aquaculture settings.
Fusion of Audio and Visual Embeddings for Sound Event Localization and Detection
Dec 14, 2023Sound event localization and detection (SELD) combines two subtasks: sound event detection (SED) and direction of arrival (DOA) estimation. SELD is usually tackled as an audio-only problem, but visual information has been recently included. Few audio-visual (AV)-SELD works have been published and most employ vision via face/object bounding boxes, or human pose keypoints. In contrast, we explore the integration of audio and visual feature embeddings extracted with pre-trained deep networks. For the visual modality, we tested ResNet50 and Inflated 3D ConvNet (I3D). Our comparison of AV fusion methods includes the AV-Conformer and Cross-Modal Attentive Fusion (CMAF) model. Our best models outperform the DCASE 2023 Task3 audio-only and AV baselines by a wide margin on the development set of the STARSS23 dataset, making them competitive amongst state-of-the-art results of the AV challenge, without model ensembling, heavy data augmentation, or prediction post-processing. Such techniques and further pre-training could be applied as next steps to improve performance.
Audio-Visual Speaker Tracking: Progress, Challenges, and Future Directions
Oct 23, 2023



Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual speaker tracking. To our knowledge, this is the first extensive survey over the past five years. We introduce the family of Bayesian filters and summarize the methods for obtaining audio-visual measurements. In addition, the existing trackers and their performance on AV16.3 dataset are summarized. In the past few years, deep learning techniques have thrived, which also boosts the development of audio visual speaker tracking. The influence of deep learning techniques in terms of measurement extraction and state estimation is also discussed. At last, we discuss the connections between audio-visual speaker tracking and other areas such as speech separation and distributed speaker tracking.
Towards Robust and Generalizable Training: An Empirical Study of Noisy Slot Filling for Input Perturbations
Oct 05, 2023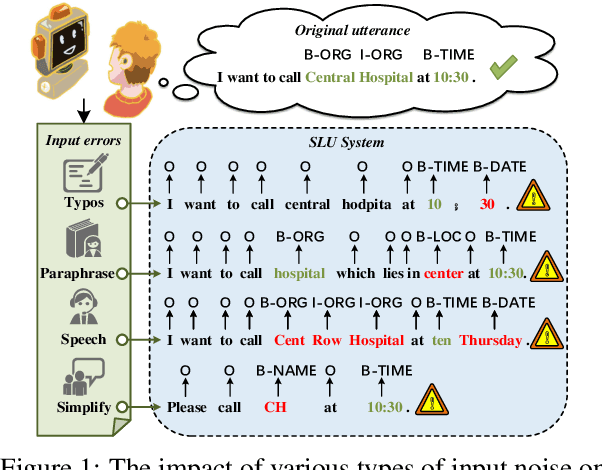

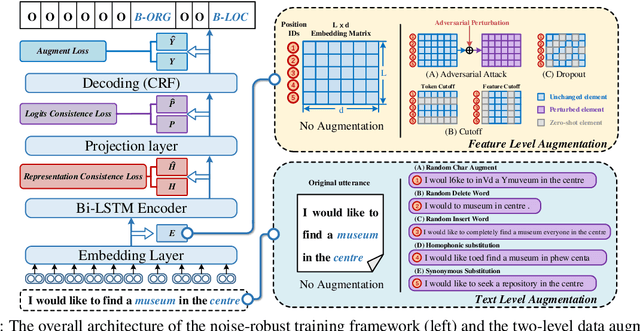
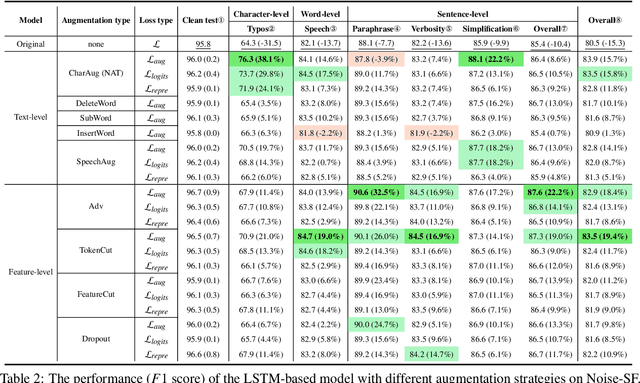
In real dialogue scenarios, as there are unknown input noises in the utterances, existing supervised slot filling models often perform poorly in practical applications. Even though there are some studies on noise-robust models, these works are only evaluated on rule-based synthetic datasets, which is limiting, making it difficult to promote the research of noise-robust methods. In this paper, we introduce a noise robustness evaluation dataset named Noise-SF for slot filling task. The proposed dataset contains five types of human-annotated noise, and all those noises are exactly existed in real extensive robust-training methods of slot filling into the proposed framework. By conducting exhaustive empirical evaluation experiments on Noise-SF, we find that baseline models have poor performance in robustness evaluation, and the proposed framework can effectively improve the robustness of models. Based on the empirical experimental results, we make some forward-looking suggestions to fuel the research in this direction. Our dataset Noise-SF will be released at https://github.com/dongguanting/Noise-SF.