 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGISA: A Benchmark for General Information-Seeking Assistant
Feb 09, 2026The advancement of large language models (LLMs) has significantly accelerated the development of search agents capable of autonomously gathering information through multi-turn web interactions. Various benchmarks have been proposed to evaluate such agents. However, existing benchmarks often construct queries backward from answers, producing unnatural tasks misaligned with real-world needs. Moreover, these benchmarks tend to focus on either locating specific information or aggregating information from multiple sources, while relying on static answer sets prone to data contamination. To bridge these gaps, we introduce GISA, a benchmark for General Information-Seeking Assistants comprising 373 human-crafted queries that reflect authentic information-seeking scenarios. GISA features four structured answer formats (item, set, list, and table), enabling deterministic evaluation. It integrates both deep reasoning and broad information aggregation within unified tasks, and includes a live subset with periodically updated answers to resist memorization. Notably, GISA provides complete human search trajectories for every query, offering gold-standard references for process-level supervision and imitation learning. Experiments on mainstream LLMs and commercial search products reveal that even the best-performing model achieves only 19.30\% exact match score, with performance notably degrading on tasks requiring complex planning and comprehensive information gathering. These findings highlight substantial room for future improvement.
ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
Jan 26, 2026Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis
Jan 09, 2026Large language models (LLMs) are expected to be trained to act as agents in various real-world environments, but this process relies on rich and varied tool-interaction sandboxes. However, access to real systems is often restricted; LLM-simulated environments are prone to hallucinations and inconsistencies; and manually built sandboxes are hard to scale. In this paper, we propose EnvScaler, an automated framework for scalable tool-interaction environments via programmatic synthesis. EnvScaler comprises two components. First, SkelBuilder constructs diverse environment skeletons through topic mining, logic modeling, and quality evaluation. Then, ScenGenerator generates multiple task scenarios and rule-based trajectory validation functions for each environment. With EnvScaler, we synthesize 191 environments and about 7K scenarios, and apply them to Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) for Qwen3 series models. Results on three benchmarks show that EnvScaler significantly improves LLMs' ability to solve tasks in complex environments involving multi-turn, multi-tool interactions. We release our code and data at https://github.com/RUC-NLPIR/EnvScaler.
Face-Human-Bench: A Comprehensive Benchmark of Face and Human Understanding for Multi-modal Assistants
Jan 05, 2025



Faces and humans are crucial elements in social interaction and are widely included in everyday photos and videos. Therefore, a deep understanding of faces and humans will enable multi-modal assistants to achieve improved response quality and broadened application scope. Currently, the multi-modal assistant community lacks a comprehensive and scientific evaluation of face and human understanding abilities. In this paper, we first propose a hierarchical ability taxonomy that includes three levels of abilities. Then, based on this taxonomy, we collect images and annotations from publicly available datasets in the face and human community and build a semi-automatic data pipeline to produce problems for the new benchmark. Finally, the obtained Face-Human-Bench comprises a development set with 900 problems and a test set with 1800 problems, supporting both English and Chinese. We conduct evaluations over 25 mainstream multi-modal large language models (MLLMs) with our Face-Human-Bench, focusing on the correlation between abilities, the impact of the relative position of targets on performance, and the impact of Chain of Thought (CoT) prompting on performance. Moreover, inspired by multi-modal agents, we also explore which abilities of MLLMs need to be supplemented by specialist models.
ProgCo: Program Helps Self-Correction of Large Language Models
Jan 02, 2025Self-Correction aims to enable large language models (LLMs) to self-verify and self-refine their initial responses without external feedback. However, LLMs often fail to effectively self-verify and generate correct feedback, further misleading refinement and leading to the failure of self-correction, especially in complex reasoning tasks. In this paper, we propose Program-driven Self-Correction (ProgCo). First, program-driven verification (ProgVe) achieves complex verification logic and extensive validation through self-generated, self-executing verification pseudo-programs. Then, program-driven refinement (ProgRe) receives feedback from ProgVe, conducts dual reflection and refinement on both responses and verification programs to mitigate misleading of incorrect feedback in complex reasoning tasks. Experiments on three instruction-following and mathematical benchmarks indicate that ProgCo achieves effective self-correction, and can be further enhance performance when combined with real program tools.
Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
Dec 17, 2024



The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at https://mdi-benchmark.github.io/
MTU-Bench: A Multi-granularity Tool-Use Benchmark for Large Language Models
Oct 15, 2024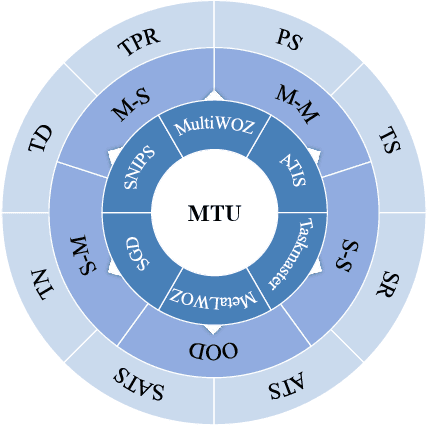
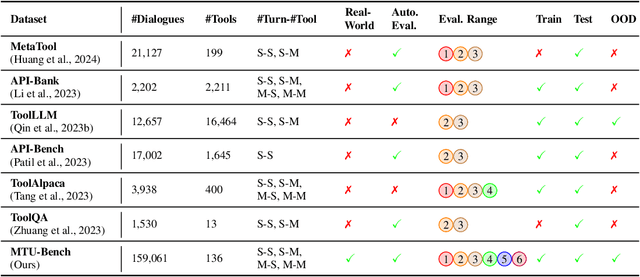
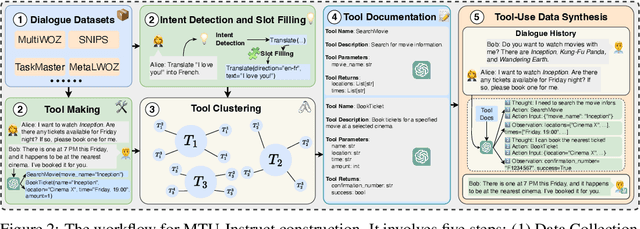
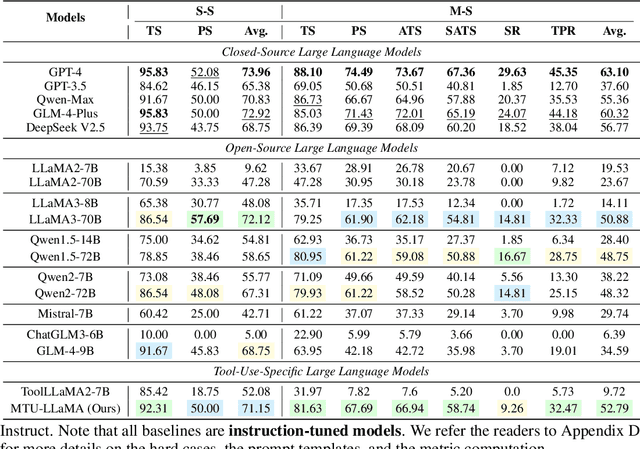
Large Language Models (LLMs) have displayed massive improvements in reasoning and decision-making skills and can hold natural conversations with users. Recently, many tool-use benchmark datasets have been proposed. However, existing datasets have the following limitations: (1). Insufficient evaluation scenarios (e.g., only cover limited tool-use scenes). (2). Extensive evaluation costs (e.g., GPT API costs). To address these limitations, in this work, we propose a multi-granularity tool-use benchmark for large language models called MTU-Bench. For the "multi-granularity" property, our MTU-Bench covers five tool usage scenes (i.e., single-turn and single-tool, single-turn and multiple-tool, multiple-turn and single-tool, multiple-turn and multiple-tool, and out-of-distribution tasks). Besides, all evaluation metrics of our MTU-Bench are based on the prediction results and the ground truth without using any GPT or human evaluation metrics. Moreover, our MTU-Bench is collected by transforming existing high-quality datasets to simulate real-world tool usage scenarios, and we also propose an instruction dataset called MTU-Instruct data to enhance the tool-use abilities of existing LLMs. Comprehensive experimental results demonstrate the effectiveness of our MTU-Bench. Code and data will be released at https: //github.com/MTU-Bench-Team/MTU-Bench.git.
Toward General Instruction-Following Alignment for Retrieval-Augmented Generation
Oct 12, 2024



Following natural instructions is crucial for the effective application of Retrieval-Augmented Generation (RAG) systems. Despite recent advancements in Large Language Models (LLMs), research on assessing and improving instruction-following (IF) alignment within the RAG domain remains limited. To address this issue, we propose VIF-RAG, the first automated, scalable, and verifiable synthetic pipeline for instruction-following alignment in RAG systems. We start by manually crafting a minimal set of atomic instructions (<100) and developing combination rules to synthesize and verify complex instructions for a seed set. We then use supervised models for instruction rewriting while simultaneously generating code to automate the verification of instruction quality via a Python executor. Finally, we integrate these instructions with extensive RAG and general data samples, scaling up to a high-quality VIF-RAG-QA dataset (>100k) through automated processes. To further bridge the gap in instruction-following auto-evaluation for RAG systems, we introduce FollowRAG Benchmark, which includes approximately 3K test samples, covering 22 categories of general instruction constraints and four knowledge-intensive QA datasets. Due to its robust pipeline design, FollowRAG can seamlessly integrate with different RAG benchmarks. Using FollowRAG and eight widely-used IF and foundational abilities benchmarks for LLMs, we demonstrate that VIF-RAG markedly enhances LLM performance across a broad range of general instruction constraints while effectively leveraging its capabilities in RAG scenarios. Further analysis offers practical insights for achieving IF alignment in RAG systems. Our code and datasets are released at https://FollowRAG.github.io.
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Jul 01, 2024



Visual mathematical reasoning, as a fundamental visual reasoning ability, has received widespread attention from the Large Multimodal Models (LMMs) community. Existing benchmarks, such as MathVista and MathVerse, focus more on the result-oriented performance but neglect the underlying principles in knowledge acquisition and generalization. Inspired by human-like mathematical reasoning, we introduce WE-MATH, the first benchmark specifically designed to explore the problem-solving principles beyond end-to-end performance. We meticulously collect and categorize 6.5K visual math problems, spanning 67 hierarchical knowledge concepts and five layers of knowledge granularity. We decompose composite problems into sub-problems according to the required knowledge concepts and introduce a novel four-dimensional metric, namely Insufficient Knowledge (IK), Inadequate Generalization (IG), Complete Mastery (CM), and Rote Memorization (RM), to hierarchically assess inherent issues in LMMs' reasoning process. With WE-MATH, we conduct a thorough evaluation of existing LMMs in visual mathematical reasoning and reveal a negative correlation between solving steps and problem-specific performance. We confirm the IK issue of LMMs can be effectively improved via knowledge augmentation strategies. More notably, the primary challenge of GPT-4o has significantly transitioned from IK to IG, establishing it as the first LMM advancing towards the knowledge generalization stage. In contrast, other LMMs exhibit a marked inclination towards Rote Memorization - they correctly solve composite problems involving multiple knowledge concepts yet fail to answer sub-problems. We anticipate that WE-MATH will open new pathways for advancements in visual mathematical reasoning for LMMs. The WE-MATH data and evaluation code are available at https://github.com/We-Math/We-Math.
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Jun 12, 2024



Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.