 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-BERT: A Unified Perturbation-Robust Framework with Noise Alignment Pre-training for Noisy Slot Filling Task
Mar 06, 2024



In a realistic dialogue system, the input information from users is often subject to various types of input perturbations, which affects the slot-filling task. Although rule-based data augmentation methods have achieved satisfactory results, they fail to exhibit the desired generalization when faced with unknown noise disturbances. In this study, we address the challenges posed by input perturbations in slot filling by proposing Noise-BERT, a unified Perturbation-Robust Framework with Noise Alignment Pre-training. Our framework incorporates two Noise Alignment Pre-training tasks: Slot Masked Prediction and Sentence Noisiness Discrimination, aiming to guide the pre-trained language model in capturing accurate slot information and noise distribution. During fine-tuning, we employ a contrastive learning loss to enhance the semantic representation of entities and labels. Additionally, we introduce an adversarial attack training strategy to improve the model's robustness. Experimental results demonstrate the superiority of our proposed approach over state-of-the-art models, and further analysis confirms its effectiveness and generalization ability.
Knowledge Editing on Black-box Large Language Models
Feb 17, 2024



Knowledge editing (KE) aims to efficiently and precisely modify the behavior of large language models (LLMs) to update specific knowledge without negatively influencing other knowledge. Current research primarily focuses on white-box LLMs editing, overlooking an important scenario: black-box LLMs editing, where LLMs are accessed through interfaces and only textual output is available. In this paper, we first officially introduce KE on black-box LLMs and then propose a comprehensive evaluation framework to overcome the limitations of existing evaluations that are not applicable to black-box LLMs editing and lack comprehensiveness. To tackle privacy leaks of editing data and style over-editing in current methods, we introduce a novel postEdit framework, resolving privacy concerns through downstream post-processing and maintaining textual style consistency via fine-grained editing to original responses. Experiments and analysis on two benchmarks demonstrate that postEdit outperforms all baselines and achieves strong generalization, especially with huge improvements on style retention (average $+20.82\%\uparrow$).
DemoNSF: A Multi-task Demonstration-based Generative Framework for Noisy Slot Filling Task
Oct 16, 2023Recently, prompt-based generative frameworks have shown impressive capabilities in sequence labeling tasks. However, in practical dialogue scenarios, relying solely on simplistic templates and traditional corpora presents a challenge for these methods in generalizing to unknown input perturbations. To address this gap, we propose a multi-task demonstration based generative framework for noisy slot filling, named DemoNSF. Specifically, we introduce three noisy auxiliary tasks, namely noisy recovery (NR), random mask (RM), and hybrid discrimination (HD), to implicitly capture semantic structural information of input perturbations at different granularities. In the downstream main task, we design a noisy demonstration construction strategy for the generative framework, which explicitly incorporates task-specific information and perturbed distribution during training and inference. Experiments on two benchmarks demonstrate that DemoNSF outperforms all baseline methods and achieves strong generalization. Further analysis provides empirical guidance for the practical application of generative frameworks. Our code is released at https://github.com/dongguanting/Demo-NSF.
Revisit Input Perturbation Problems for LLMs: A Unified Robustness Evaluation Framework for Noisy Slot Filling Task
Oct 10, 2023With the increasing capabilities of large language models (LLMs), these high-performance models have achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks. However, the models' performance on commonly-used benchmark datasets often fails to accurately reflect their reliability and robustness when applied to real-world noisy data. To address these challenges, we propose a unified robustness evaluation framework based on the slot-filling task to systematically evaluate the dialogue understanding capability of LLMs in diverse input perturbation scenarios. Specifically, we construct a input perturbation evaluation dataset, Noise-LLM, which contains five types of single perturbation and four types of mixed perturbation data. Furthermore, we utilize a multi-level data augmentation method (character, word, and sentence levels) to construct a candidate data pool, and carefully design two ways of automatic task demonstration construction strategies (instance-level and entity-level) with various prompt templates. Our aim is to assess how well various robustness methods of LLMs perform in real-world noisy scenarios. The experiments have demonstrated that the current open-source LLMs generally achieve limited perturbation robustness performance. Based on these experimental observations, we make some forward-looking suggestions to fuel the research in this direction.
A Multi-Task Semantic Decomposition Framework with Task-specific Pre-training for Few-Shot NER
Aug 28, 2023
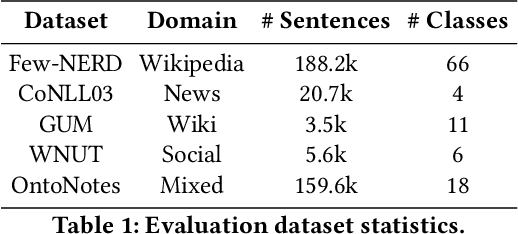
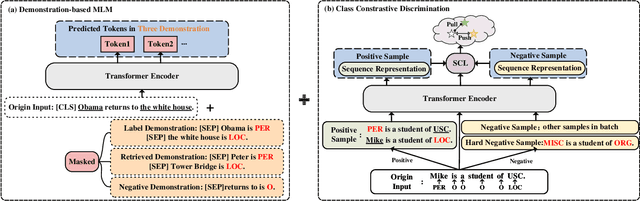

The objective of few-shot named entity recognition is to identify named entities with limited labeled instances. Previous works have primarily focused on optimizing the traditional token-wise classification framework, while neglecting the exploration of information based on NER data characteristics. To address this issue, we propose a Multi-Task Semantic Decomposition Framework via Joint Task-specific Pre-training (MSDP) for few-shot NER. Drawing inspiration from demonstration-based and contrastive learning, we introduce two novel pre-training tasks: Demonstration-based Masked Language Modeling (MLM) and Class Contrastive Discrimination. These tasks effectively incorporate entity boundary information and enhance entity representation in Pre-trained Language Models (PLMs). In the downstream main task, we introduce a multi-task joint optimization framework with the semantic decomposing method, which facilitates the model to integrate two different semantic information for entity classification. Experimental results of two few-shot NER benchmarks demonstrate that MSDP consistently outperforms strong baselines by a large margin. Extensive analyses validate the effectiveness and generalization of MSDP.