 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
Respiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024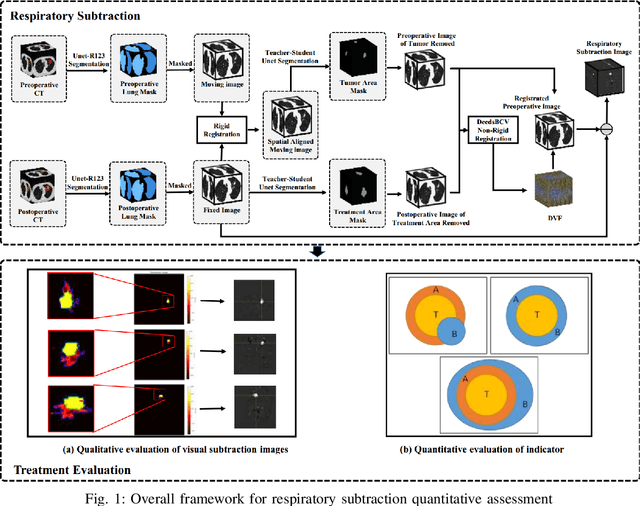
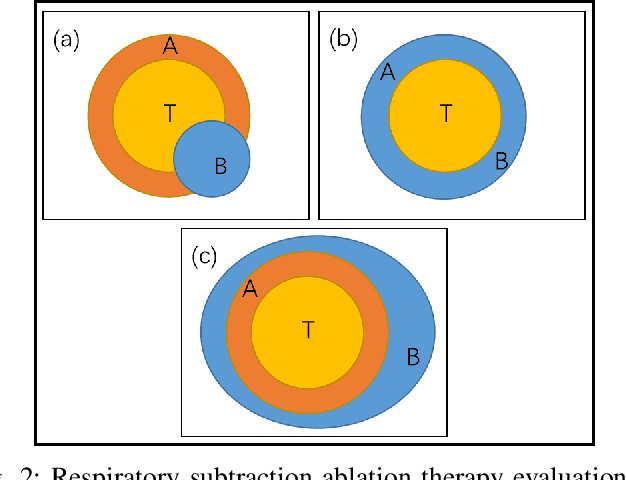
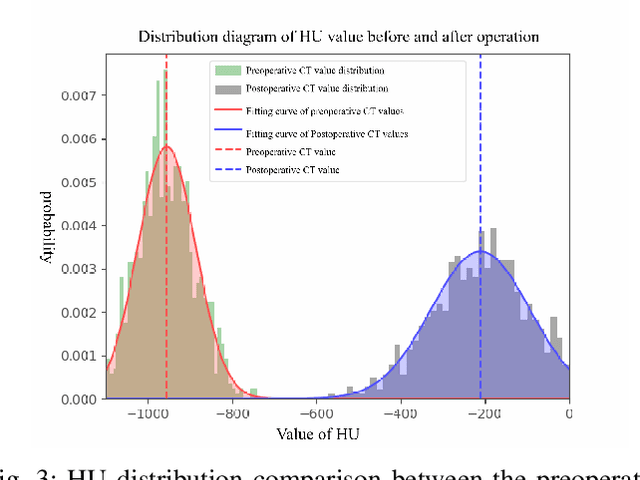
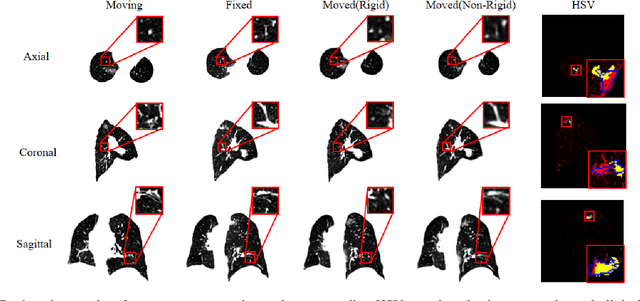
Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
Understand What LLM Needs: Dual Preference Alignment for Retrieval-Augmented Generation
Jun 26, 2024Retrieval-augmented generation (RAG) has demonstrated effectiveness in mitigating the hallucination problem of large language models (LLMs). However, the difficulty of aligning the retriever with the diverse LLMs' knowledge preferences inevitably poses an inevitable challenge in developing a reliable RAG system. To address this issue, we propose DPA-RAG, a universal framework designed to align diverse knowledge preferences within RAG systems. Specifically, we initially introduce a preference knowledge construction pipline and incorporate five novel query augmentation strategies to alleviate preference data scarcity. Based on preference data, DPA-RAG accomplishes both external and internal preference alignment: 1) It jointly integrate pair-wise, point-wise, and contrastive preference alignment abilities into the reranker, achieving external preference alignment among RAG components. 2) It further introduces a pre-aligned stage before vanilla Supervised Fine-tuning (SFT), enabling LLMs to implicitly capture knowledge aligned with their reasoning preferences, achieving LLMs' internal alignment. Experimental results across four knowledge-intensive QA datasets demonstrate that DPA-RAG outperforms all baselines and seamlessly integrates both black-box and open-sourced LLM readers. Further qualitative analysis and discussions also provide empirical guidance for achieving reliable RAG systems. Our code is publicly available at https://github.com/dongguanting/DPA-RAG.
Improved Dense Nested Attention Network Based on Transformer for Infrared Small Target Detection
Nov 15, 2023



Infrared small target detection based on deep learning offers unique advantages in separating small targets from complex and dynamic backgrounds. However, the features of infrared small targets gradually weaken as the depth of convolutional neural network (CNN) increases. To address this issue, we propose a novel method for detecting infrared small targets called improved dense nested attention network (IDNANet), which is based on the transformer architecture. We preserve the dense nested structure of dense nested attention network (DNANet) and introduce the Swin-transformer during feature extraction stage to enhance the continuity of features. Furthermore, we integrate the ACmix attention structure into the dense nested structure to enhance the features of intermediate layers. Additionally, we design a weighted dice binary cross-entropy (WD-BCE) loss function to mitigate the negative impact of foreground-background imbalance in the samples. Moreover, we develop a dataset specifically for infrared small targets, called BIT-SIRST. The dataset comprises a significant amount of real-world targets and manually annotated labels, as well as synthetic data and corresponding labels. We have evaluated the effectiveness of our method through experiments conducted on public datasets. In comparison to other state-of-the-art methods, our approach outperforms in terms of probability of detection (P_d), false-alarm rate (F_a), and mean intersection of union ($mIoU$). The $mIoU$ reaches 90.89 on the NUDT-SIRST dataset and 79.72 on the NUAA-SIRST dataset.
Revisit Input Perturbation Problems for LLMs: A Unified Robustness Evaluation Framework for Noisy Slot Filling Task
Oct 10, 2023With the increasing capabilities of large language models (LLMs), these high-performance models have achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks. However, the models' performance on commonly-used benchmark datasets often fails to accurately reflect their reliability and robustness when applied to real-world noisy data. To address these challenges, we propose a unified robustness evaluation framework based on the slot-filling task to systematically evaluate the dialogue understanding capability of LLMs in diverse input perturbation scenarios. Specifically, we construct a input perturbation evaluation dataset, Noise-LLM, which contains five types of single perturbation and four types of mixed perturbation data. Furthermore, we utilize a multi-level data augmentation method (character, word, and sentence levels) to construct a candidate data pool, and carefully design two ways of automatic task demonstration construction strategies (instance-level and entity-level) with various prompt templates. Our aim is to assess how well various robustness methods of LLMs perform in real-world noisy scenarios. The experiments have demonstrated that the current open-source LLMs generally achieve limited perturbation robustness performance. Based on these experimental observations, we make some forward-looking suggestions to fuel the research in this direction.
Towards Robust and Generalizable Training: An Empirical Study of Noisy Slot Filling for Input Perturbations
Oct 05, 2023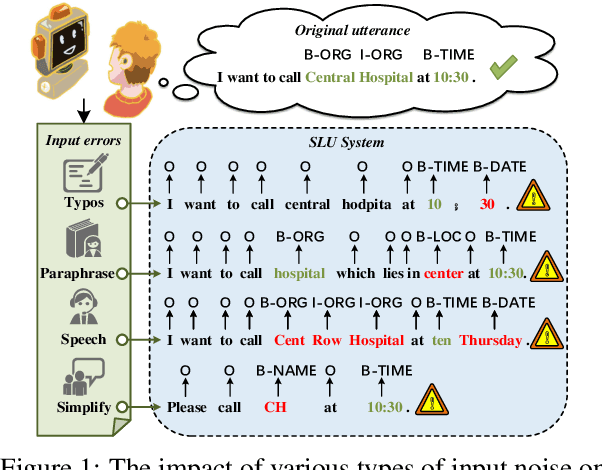

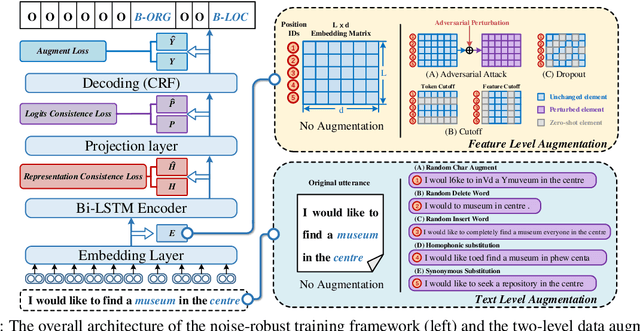
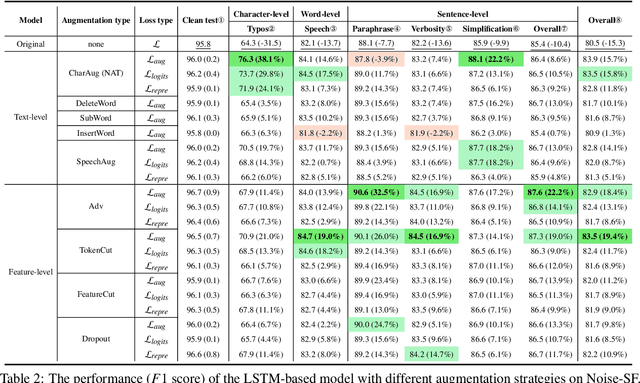
In real dialogue scenarios, as there are unknown input noises in the utterances, existing supervised slot filling models often perform poorly in practical applications. Even though there are some studies on noise-robust models, these works are only evaluated on rule-based synthetic datasets, which is limiting, making it difficult to promote the research of noise-robust methods. In this paper, we introduce a noise robustness evaluation dataset named Noise-SF for slot filling task. The proposed dataset contains five types of human-annotated noise, and all those noises are exactly existed in real extensive robust-training methods of slot filling into the proposed framework. By conducting exhaustive empirical evaluation experiments on Noise-SF, we find that baseline models have poor performance in robustness evaluation, and the proposed framework can effectively improve the robustness of models. Based on the empirical experimental results, we make some forward-looking suggestions to fuel the research in this direction. Our dataset Noise-SF will be released at https://github.com/dongguanting/Noise-SF.
A Multi-Task Semantic Decomposition Framework with Task-specific Pre-training for Few-Shot NER
Aug 28, 2023
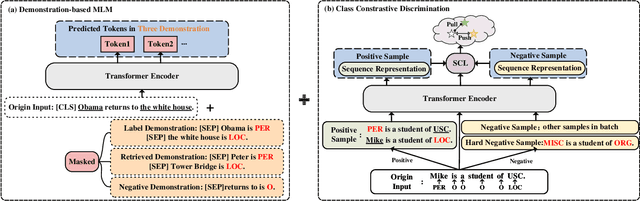

The objective of few-shot named entity recognition is to identify named entities with limited labeled instances. Previous works have primarily focused on optimizing the traditional token-wise classification framework, while neglecting the exploration of information based on NER data characteristics. To address this issue, we propose a Multi-Task Semantic Decomposition Framework via Joint Task-specific Pre-training (MSDP) for few-shot NER. Drawing inspiration from demonstration-based and contrastive learning, we introduce two novel pre-training tasks: Demonstration-based Masked Language Modeling (MLM) and Class Contrastive Discrimination. These tasks effectively incorporate entity boundary information and enhance entity representation in Pre-trained Language Models (PLMs). In the downstream main task, we introduce a multi-task joint optimization framework with the semantic decomposing method, which facilitates the model to integrate two different semantic information for entity classification. Experimental results of two few-shot NER benchmarks demonstrate that MSDP consistently outperforms strong baselines by a large margin. Extensive analyses validate the effectiveness and generalization of MSDP.
Revisit Out-Of-Vocabulary Problem for Slot Filling: A Unified Contrastive Frameword with Multi-level Data Augmentations
Feb 27, 2023In real dialogue scenarios, the existing slot filling model, which tends to memorize entity patterns, has a significantly reduced generalization facing Out-of-Vocabulary (OOV) problems. To address this issue, we propose an OOV robust slot filling model based on multi-level data augmentations to solve the OOV problem from both word and slot perspectives. We present a unified contrastive learning framework, which pull representations of the origin sample and augmentation samples together, to make the model resistant to OOV problems. We evaluate the performance of the model from some specific slots and carefully design test data with OOV word perturbation to further demonstrate the effectiveness of OOV words. Experiments on two datasets show that our approach outperforms the previous sota methods in terms of both OOV slots and words.
A Prototypical Semantic Decoupling Method via Joint Contrastive Learning for Few-Shot Name Entity Recognition
Feb 27, 2023



Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Most existing prototype-based sequence labeling models tend to memorize entity mentions which would be easily confused by close prototypes. In this paper, we proposed a Prototypical Semantic Decoupling method via joint Contrastive learning (PSDC) for few-shot NER. Specifically, we decouple class-specific prototypes and contextual semantic prototypes by two masking strategies to lead the model to focus on two different semantic information for inference. Besides, we further introduce joint contrastive learning objectives to better integrate two kinds of decoupling information and prevent semantic collapse. Experimental results on two few-shot NER benchmarks demonstrate that PSDC consistently outperforms the previous SOTA methods in terms of overall performance. Extensive analysis further validates the effectiveness and generalization of PSDC.
Semi-Supervised Knowledge-Grounded Pre-training for Task-Oriented Dialog Systems
Oct 17, 2022
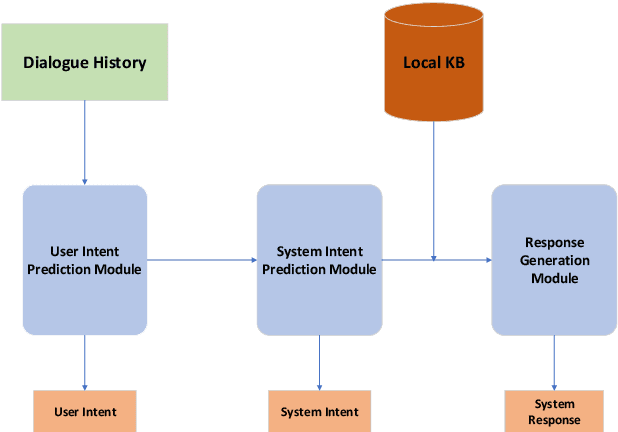
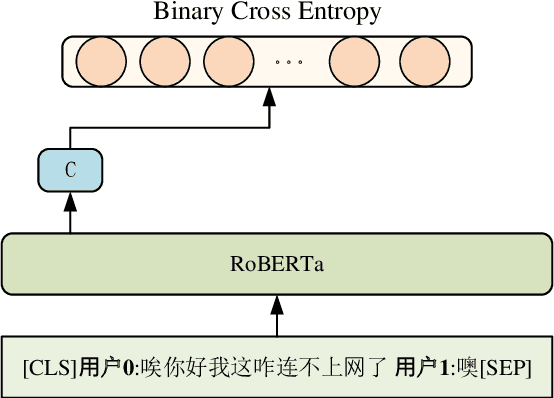
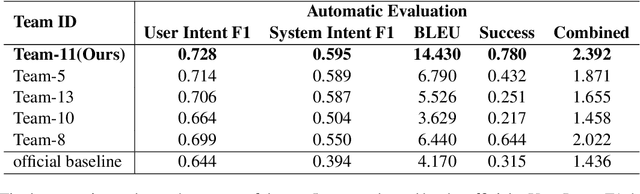
Recent advances in neural approaches greatly improve task-oriented dialogue (TOD) systems which assist users to accomplish their goals. However, such systems rely on costly manually labeled dialogs which are not available in practical scenarios. In this paper, we present our models for Track 2 of the SereTOD 2022 challenge, which is the first challenge of building semi-supervised and reinforced TOD systems on a large-scale real-world Chinese TOD dataset MobileCS. We build a knowledge-grounded dialog model to formulate dialog history and local KB as input and predict the system response. And we perform semi-supervised pre-training both on the labeled and unlabeled data. Our system achieves the first place both in the automatic evaluation and human interaction, especially with higher BLEU (+7.64) and Success (+13.6\%) than the second place.