 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024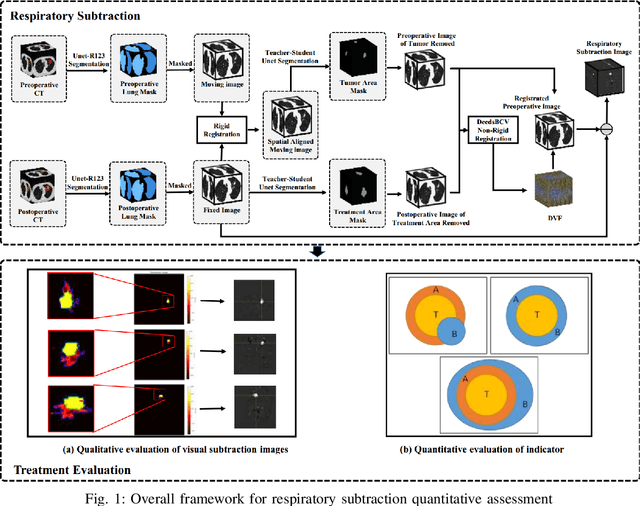
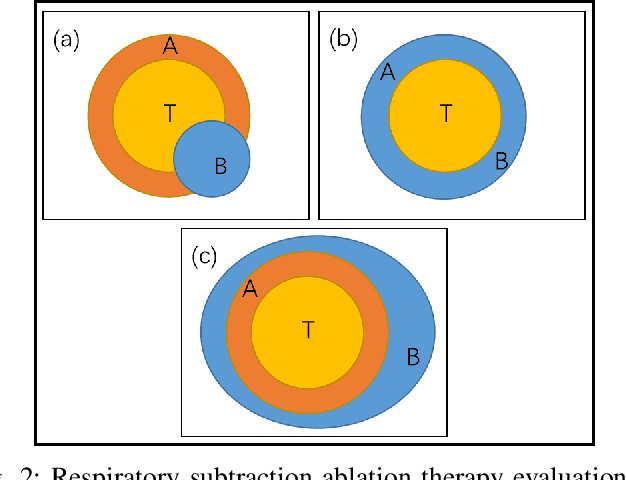
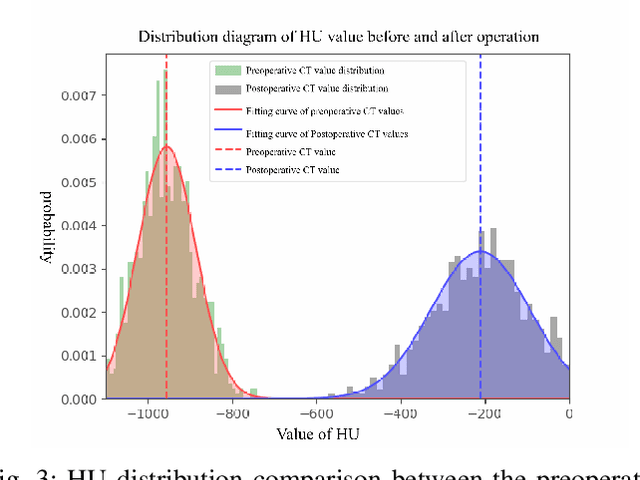
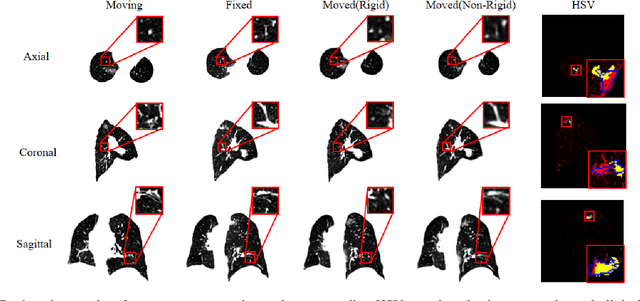
Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
RSTAR: Rotational Streak Artifact Reduction in 4D CBCT using Separable and Circular Convolutions
Mar 25, 2024



Four-dimensional cone-beam computed tomography (4D CBCT) provides respiration-resolved images and can be used for image-guided radiation therapy. However, the ability to reveal respiratory motion comes at the cost of image artifacts. As raw projection data are sorted into multiple respiratory phases, there is a limited number of cone-beam projections available for image reconstruction. Consequently, the 4D CBCT images are covered by severe streak artifacts. Although several deep learning-based methods have been proposed to address this issue, most algorithms employ ordinary network models, neglecting the intrinsic structural prior within 4D CBCT images. In this paper, we first explore the origin and appearance of streak artifacts in 4D CBCT images.Specifically, we find that streak artifacts exhibit a periodic rotational motion along with the patient's respiration. This unique motion pattern inspires us to distinguish the artifacts from the desired anatomical structures in the spatiotemporal domain. Thereafter, we propose a spatiotemporal neural network named RSTAR-Net with separable and circular convolutions for Rotational Streak Artifact Reduction. The specially designed model effectively encodes dynamic image features, facilitating the recovery of 4D CBCT images. Moreover, RSTAR-Net is also lightweight and computationally efficient. Extensive experiments substantiate the effectiveness of our proposed method, and RSTAR-Net shows superior performance to comparison methods.
Swin-UMamba: Mamba-based UNet with ImageNet-based pretraining
Feb 05, 2024



Accurate medical image segmentation demands the integration of multi-scale information, spanning from local features to global dependencies. However, it is challenging for existing methods to model long-range global information, where convolutional neural networks (CNNs) are constrained by their local receptive fields, and vision transformers (ViTs) suffer from high quadratic complexity of their attention mechanism. Recently, Mamba-based models have gained great attention for their impressive ability in long sequence modeling. Several studies have demonstrated that these models can outperform popular vision models in various tasks, offering higher accuracy, lower memory consumption, and less computational burden. However, existing Mamba-based models are mostly trained from scratch and do not explore the power of pretraining, which has been proven to be quite effective for data-efficient medical image analysis. This paper introduces a novel Mamba-based model, Swin-UMamba, designed specifically for medical image segmentation tasks, leveraging the advantages of ImageNet-based pretraining. Our experimental results reveal the vital role of ImageNet-based training in enhancing the performance of Mamba-based models. Swin-UMamba demonstrates superior performance with a large margin compared to CNNs, ViTs, and latest Mamba-based models. Notably, on AbdomenMRI, Encoscopy, and Microscopy datasets, Swin-UMamba outperforms its closest counterpart U-Mamba by an average score of 3.58%. The code and models of Swin-UMamba are publicly available at: https://github.com/JiarunLiu/Swin-UMamba
PDS-MAR: a fine-grained Projection-Domain Segmentation-based Metal Artifact Reduction method for intraoperative CBCT images with guidewires
Jun 21, 2023Since the invention of modern CT systems, metal artifacts have been a persistent problem. Due to increased scattering, amplified noise, and insufficient data collection, it is more difficult to suppress metal artifacts in cone-beam CT, limiting its use in human- and robot-assisted spine surgeries where metallic guidewires and screws are commonly used. In this paper, we demonstrate that conventional image-domain segmentation-based MAR methods are unable to eliminate metal artifacts for intraoperative CBCT images with guidewires. To solve this problem, we present a fine-grained projection-domain segmentation-based MAR method termed PDS-MAR, in which metal traces are augmented and segmented in the projection domain before being inpainted using triangular interpolation. In addition, a metal reconstruction phase is proposed to restore metal areas in the image domain. The digital phantom study and real CBCT data study demonstrate that the proposed algorithm achieves significantly better artifact suppression than other comparing methods and has the potential to advance the use of intraoperative CBCT imaging in clinical spine surgeries.
DIGEST: Deeply supervIsed knowledGE tranSfer neTwork learning for brain tumor segmentation with incomplete multi-modal MRI scans
Nov 15, 2022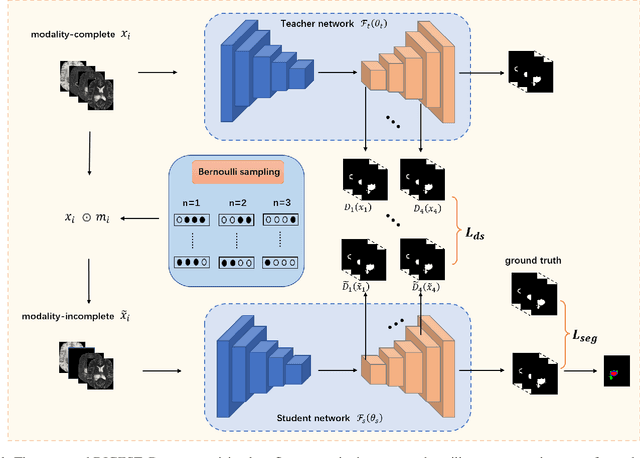
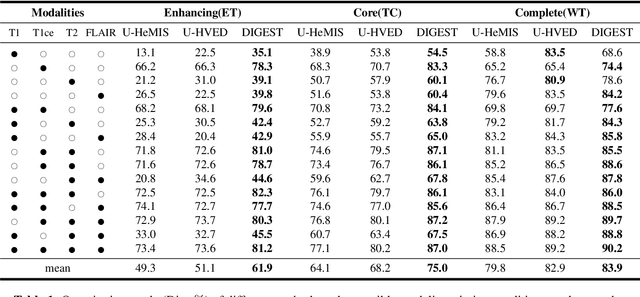
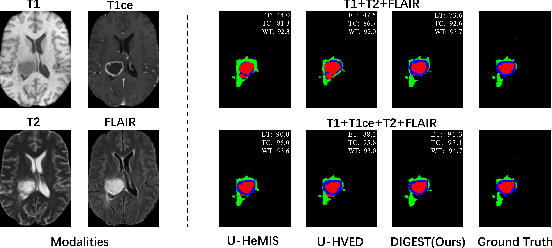
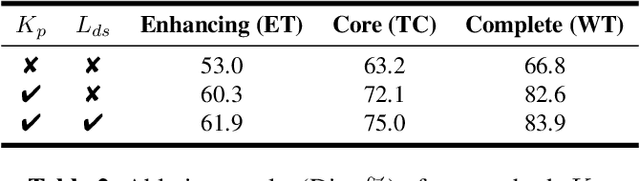
Brain tumor segmentation based on multi-modal magnetic resonance imaging (MRI) plays a pivotal role in assisting brain cancer diagnosis, treatment, and postoperative evaluations. Despite the achieved inspiring performance by existing automatic segmentation methods, multi-modal MRI data are still unavailable in real-world clinical applications due to quite a few uncontrollable factors (e.g. different imaging protocols, data corruption, and patient condition limitations), which lead to a large performance drop during practical applications. In this work, we propose a Deeply supervIsed knowledGE tranSfer neTwork (DIGEST), which achieves accurate brain tumor segmentation under different modality-missing scenarios. Specifically, a knowledge transfer learning frame is constructed, enabling a student model to learn modality-shared semantic information from a teacher model pretrained with the complete multi-modal MRI data. To simulate all the possible modality-missing conditions under the given multi-modal data, we generate incomplete multi-modal MRI samples based on Bernoulli sampling. Finally, a deeply supervised knowledge transfer loss is designed to ensure the consistency of the teacher-student structure at different decoding stages, which helps the extraction of inherent and effective modality representations. Experiments on the BraTS 2020 dataset demonstrate that our method achieves promising results for the incomplete multi-modal MR image segmentation task.
Expert Knowledge-guided Geometric Representation Learning for Magnetic Resonance Imaging-based Glioma Grading
Jan 08, 2022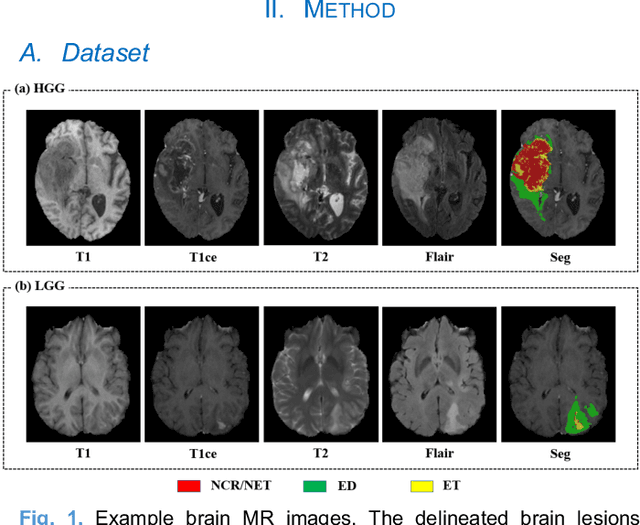
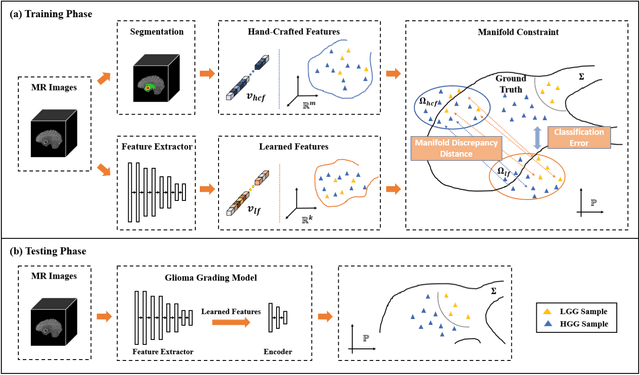
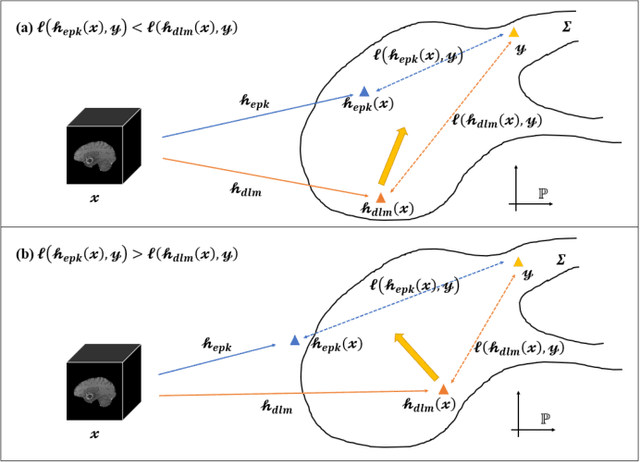
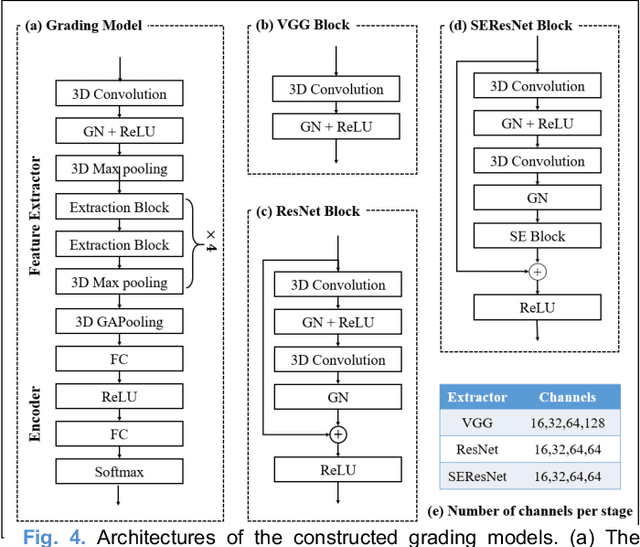
Radiomics and deep learning have shown high popularity in automatic glioma grading. Radiomics can extract hand-crafted features that quantitatively describe the expert knowledge of glioma grades, and deep learning is powerful in extracting a large number of high-throughput features that facilitate the final classification. However, the performance of existing methods can still be improved as their complementary strengths have not been sufficiently investigated and integrated. Furthermore, lesion maps are usually needed for the final prediction at the testing phase, which is very troublesome. In this paper, we propose an expert knowledge-guided geometric representation learning (ENROL) framework . Geometric manifolds of hand-crafted features and learned features are constructed to mine the implicit relationship between deep learning and radiomics, and therefore to dig mutual consent and essential representation for the glioma grades. With a specially designed manifold discrepancy measurement, the grading model can exploit the input image data and expert knowledge more effectively in the training phase and get rid of the requirement of lesion segmentation maps at the testing phase. The proposed framework is flexible regarding deep learning architectures to be utilized. Three different architectures have been evaluated and five models have been compared, which show that our framework can always generate promising results.
Stationary Multi-source AI-powered Real-time Tomography for Dynamic Cardiac Imaging
Aug 27, 2021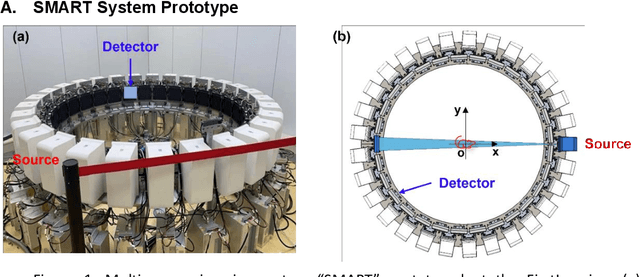
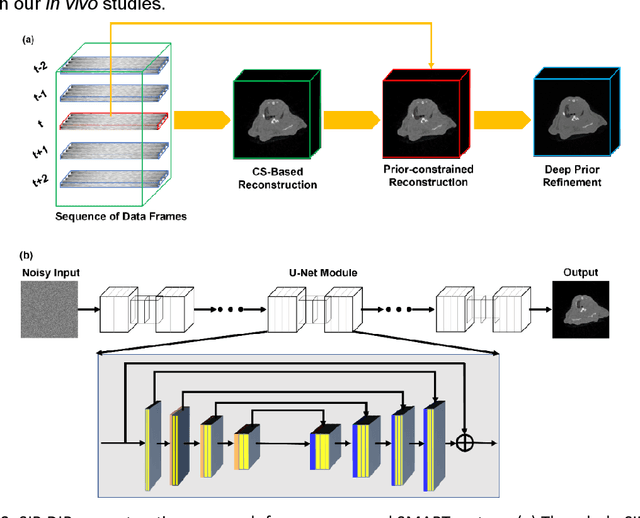
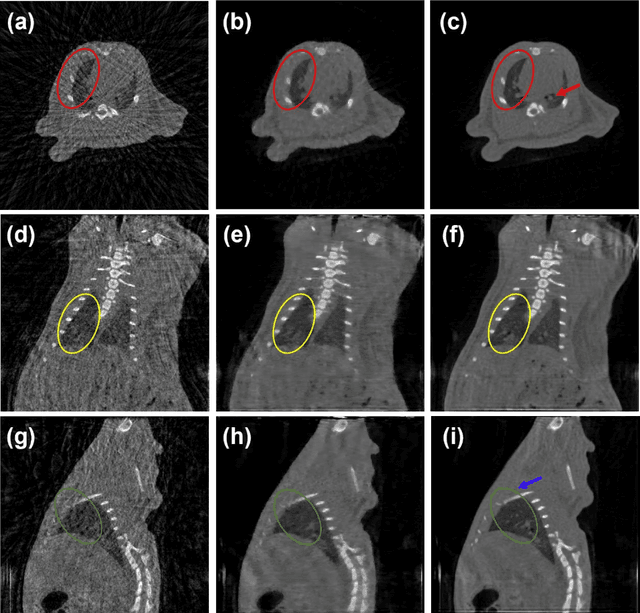
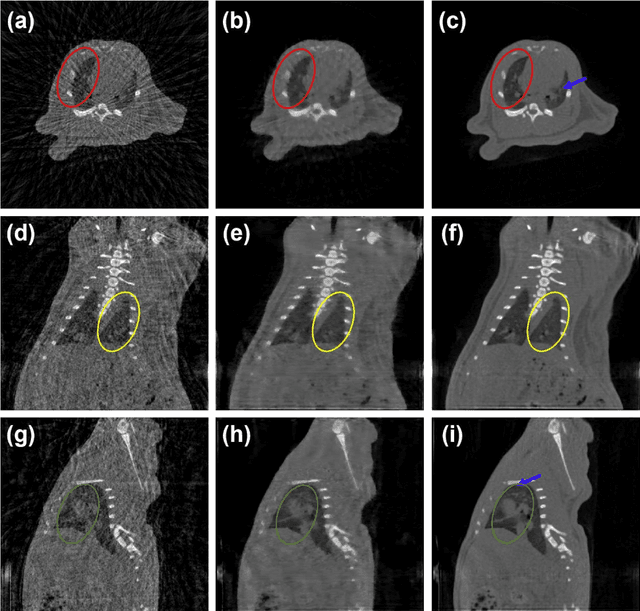
A first stationary multi-source computed tomography (CT) system is prototyped for preclinical imaging to achieve real-time temporal resolution for dynamic cardiac imaging. This unique is featured by 29 source-detector pairs fixed on a circular track for each detector to collect x-ray signals only from the opposite x-ray source. The new system architecture potentially leads to a major improvement in temporal resolution. To demonstrate the feasibility of this Stationary Multi-source AI-based Real-time Tomography (SMART) system, we develop a novel reconstruction scheme integrating both sparsified image prior (SIP) and deep image prior (DIP), which is referred to as the SIP-DIP network. Then, the SIP-DIP network for cardiac imaging is evaluated on preclinical cardiac datasets of alive rats. The reconstructed image volumes demonstrate the feasibility of the SMART system and the SIP-DIP network and the merits over other reconstruction methods.
Convolutional Sparse Coding for Compressed Sensing CT Reconstruction
Mar 20, 2019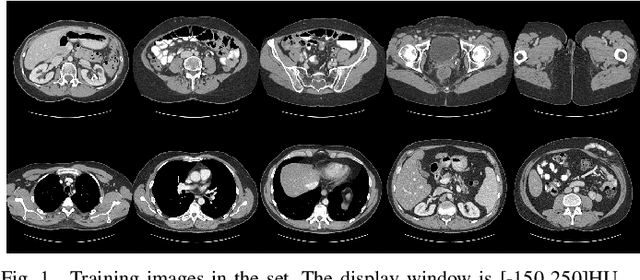
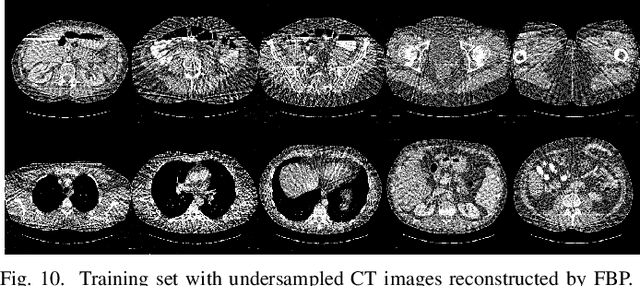


Over the past few years, dictionary learning (DL)-based methods have been successfully used in various image reconstruction problems. However, traditional DL-based computed tomography (CT) reconstruction methods are patch-based and ignore the consistency of pixels in overlapped patches. In addition, the features learned by these methods always contain shifted versions of the same features. In recent years, convolutional sparse coding (CSC) has been developed to address these problems. In this paper, inspired by several successful applications of CSC in the field of signal processing, we explore the potential of CSC in sparse-view CT reconstruction. By directly working on the whole image, without the necessity of dividing the image into overlapped patches in DL-based methods, the proposed methods can maintain more details and avoid artifacts caused by patch aggregation. With predetermined filters, an alternating scheme is developed to optimize the objective function. Extensive experiments with simulated and real CT data were performed to validate the effectiveness of the proposed methods. Qualitative and quantitative results demonstrate that the proposed methods achieve better performance than several existing state-of-the-art methods.