 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePack and Force Your Memory: Long-form and Consistent Video Generation
Oct 02, 2025Long-form video generation presents a dual challenge: models must capture long-range dependencies while preventing the error accumulation inherent in autoregressive decoding. To address these challenges, we make two contributions. First, for dynamic context modeling, we propose MemoryPack, a learnable context-retrieval mechanism that leverages both textual and image information as global guidance to jointly model short- and long-term dependencies, achieving minute-level temporal consistency. This design scales gracefully with video length, preserves computational efficiency, and maintains linear complexity. Second, to mitigate error accumulation, we introduce Direct Forcing, an efficient single-step approximating strategy that improves training-inference alignment and thereby curtails error propagation during inference. Together, MemoryPack and Direct Forcing substantially enhance the context consistency and reliability of long-form video generation, advancing the practical usability of autoregressive video models.
HunyuanVideo-HOMA: Generic Human-Object Interaction in Multimodal Driven Human Animation
Jun 10, 2025To address key limitations in human-object interaction (HOI) video generation -- specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility -- we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface. The project page is at https://anonymous.4open.science/w/homa-page-0FBE/.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
STCMOT: Spatio-Temporal Cohesion Learning for UAV-Based Multiple Object Tracking
Sep 17, 2024



Multiple object tracking (MOT) in Unmanned Aerial Vehicle (UAV) videos is important for diverse applications in computer vision. Current MOT trackers rely on accurate object detection results and precise matching of target reidentification (ReID). These methods focus on optimizing target spatial attributes while overlooking temporal cues in modelling object relationships, especially for challenging tracking conditions such as object deformation and blurring, etc. To address the above-mentioned issues, we propose a novel Spatio-Temporal Cohesion Multiple Object Tracking framework (STCMOT), which utilizes historical embedding features to model the representation of ReID and detection features in a sequential order. Concretely, a temporal embedding boosting module is introduced to enhance the discriminability of individual embedding based on adjacent frame cooperation. While the trajectory embedding is then propagated by a temporal detection refinement module to mine salient target locations in the temporal field. Extensive experiments on the VisDrone2019 and UAVDT datasets demonstrate our STCMOT sets a new state-of-the-art performance in MOTA and IDF1 metrics. The source codes are released at https://github.com/ydhcg-BoBo/STCMOT.
Performance Analysis of Photon-Limited Free-Space Optical Communications with Practical Photon-Counting Receivers
Aug 24, 2024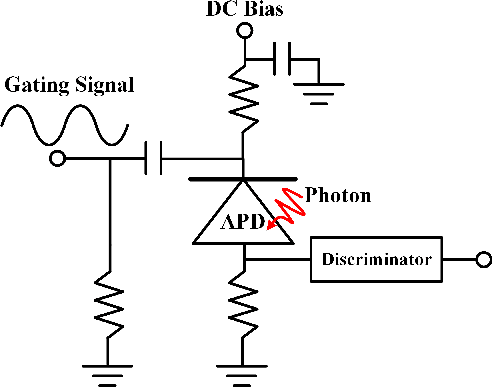
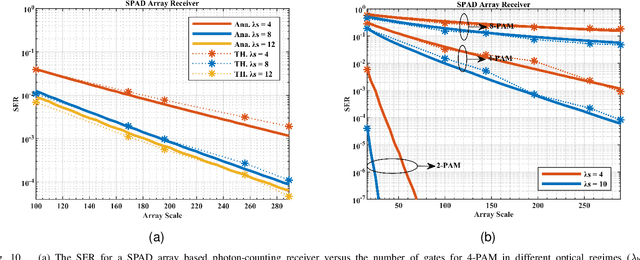
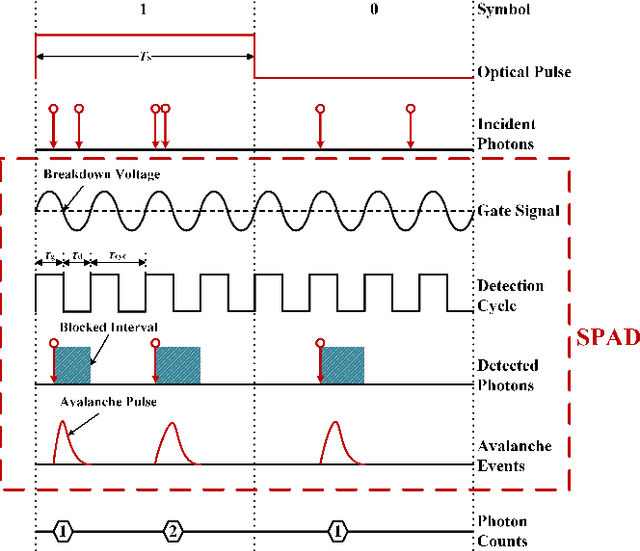
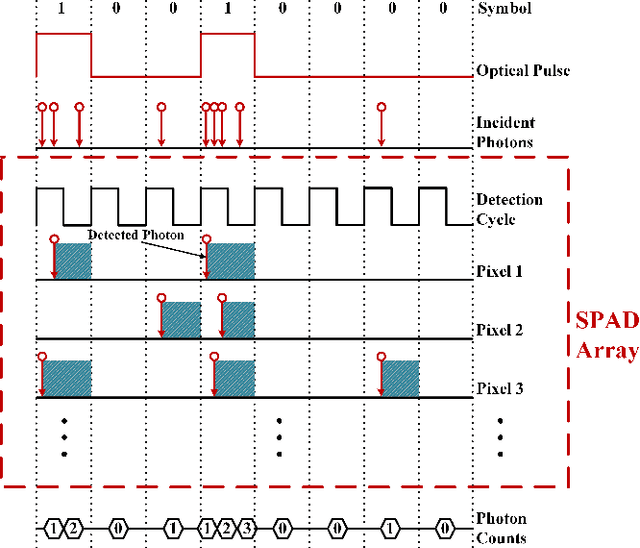
The non-perfect factors of practical photon-counting receiver are recognized as a significant challenge for long-distance photon-limited free-space optical (FSO) communication systems. This paper presents a comprehensive analytical framework for modeling the statistical properties of time-gated single-photon avalanche diode (TG-SPAD) based photon-counting receivers in presence of dead time, non-photon-number-resolving and afterpulsing effect. Drawing upon the non-Markovian characteristic of afterpulsing effect, we formulate a closed-form approximation for the probability mass function (PMF) of photon counts, when high-order pulse amplitude modulation (PAM) is used. Unlike the photon counts from a perfect photon-counting receiver, which adhere to a Poisson arrival process, the photon counts from a practical TG-SPAD based receiver are instead approximated by a binomial distribution. Additionally, by employing the maximum likelihood (ML) criterion, we derive a refined closed-form formula for determining the threshold in high-order PAM, thereby facilitating the development of an analytical model for the symbol error rate (SER). Utilizing this analytical SER model, the system performance is investigated. The numerical results underscore the crucial need to suppress background radiation below the tolerated threshold and to maintain a sufficient number of gates in order to achieve a target SER.
A Novel Signal Detection Method for Photon-Counting Communications with Nonlinear Distortion Effects
Aug 20, 2024



This paper proposes a method for estimating and detecting optical signals in practical photon-counting receivers. There are two important aspects of non-perfect photon-counting receivers, namely, (i) dead time which results in blocking loss, and (ii) non-photon-number-resolving, which leads to counting loss during the gate-ON interval. These factors introduce nonlinear distortion to the detected photon counts. The detected photon counts depend not only on the optical intensity but also on the signal waveform, and obey a Poisson binomial process. Using the discrete Fourier transform characteristic function (DFT-CF) method, we derive the probability mass function (PMF) of the detected photon counts. Furthermore, unlike conventional methods that assume an ideal rectangle wave, we propose a novel signal estimation and decision method applicable to arbitrary waveform. We demonstrate that the proposed method achieves superior error performance compared to conventional methods. The proposed algorithm has the potential to become an essential signal processing tool for photon-counting receivers.
RSTAR: Rotational Streak Artifact Reduction in 4D CBCT using Separable and Circular Convolutions
Mar 25, 2024



Four-dimensional cone-beam computed tomography (4D CBCT) provides respiration-resolved images and can be used for image-guided radiation therapy. However, the ability to reveal respiratory motion comes at the cost of image artifacts. As raw projection data are sorted into multiple respiratory phases, there is a limited number of cone-beam projections available for image reconstruction. Consequently, the 4D CBCT images are covered by severe streak artifacts. Although several deep learning-based methods have been proposed to address this issue, most algorithms employ ordinary network models, neglecting the intrinsic structural prior within 4D CBCT images. In this paper, we first explore the origin and appearance of streak artifacts in 4D CBCT images.Specifically, we find that streak artifacts exhibit a periodic rotational motion along with the patient's respiration. This unique motion pattern inspires us to distinguish the artifacts from the desired anatomical structures in the spatiotemporal domain. Thereafter, we propose a spatiotemporal neural network named RSTAR-Net with separable and circular convolutions for Rotational Streak Artifact Reduction. The specially designed model effectively encodes dynamic image features, facilitating the recovery of 4D CBCT images. Moreover, RSTAR-Net is also lightweight and computationally efficient. Extensive experiments substantiate the effectiveness of our proposed method, and RSTAR-Net shows superior performance to comparison methods.
Exploiting Spatial-Temporal Semantic Consistency for Video Scene Parsing
Sep 06, 2021

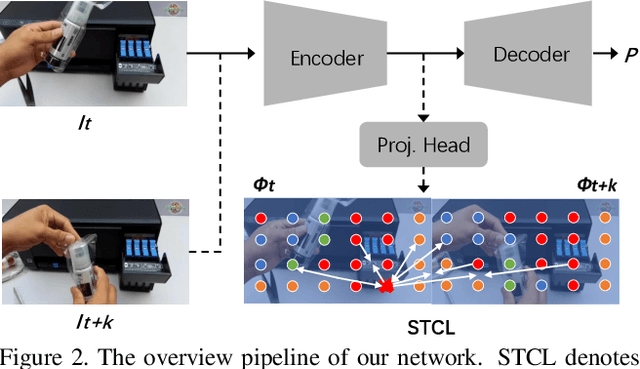

Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction. In this paper, we propose a Spatial-Temporal Semantic Consistency method to capture class-exclusive context information. Specifically, we design a spatial-temporal consistency loss to constrain the semantic consistency in spatial and temporal dimensions. In addition, we adopt an pseudo-labeling strategy to enrich the training dataset. We obtain the scores of 59.84% and 58.85% mIoU on development (test part 1) and testing set of VSPW, respectively. And our method wins the 1st place on VSPW challenge at ICCV2021.
U-net super-neural segmentation and similarity calculation to realize vegetation change assessment in satellite imagery
Sep 10, 2019

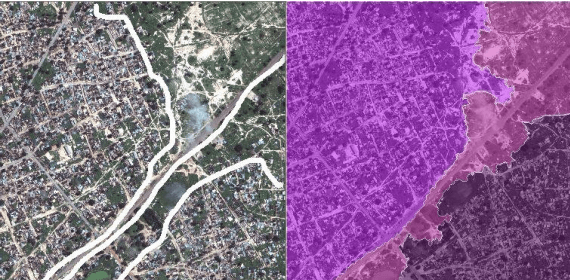
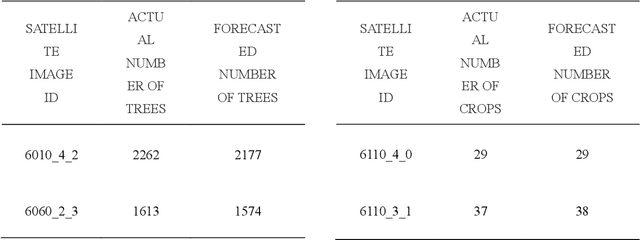
Vegetation is the natural linkage connecting soil, atmosphere and water. It can represent the change of land cover to a certain extent and serve as an indicator for global change research. Methods for measuring coverage can be divided into two types: surface measurement and remote sensing. Because vegetation cover has significant spatial and temporal differentiation characteristics, remote sensing has become an important technical means to estimate vegetation coverage. This paper firstly uses U-net to perform remote sensing image semantic segmentation training, then uses the result of semantic segmentation, and then uses the integral progressive method to calculate the forestland change rate, and finally realizes automated valuation of woodland change rate.