 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Pruning Guided by Spatial and Channel Attention for DNNs in Intelligent Edge Computing
Nov 08, 2020


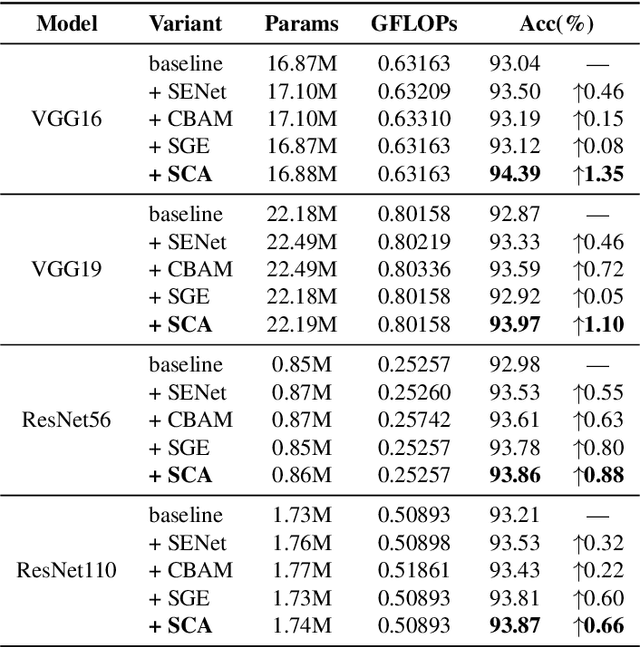
Deep Neural Networks (DNNs) have achieved remarkable success in many computer vision tasks recently, but the huge number of parameters and the high computation overhead hinder their deployments on resource-constrained edge devices. It is worth noting that channel pruning is an effective approach for compressing DNN models. A critical challenge is to determine which channels are to be removed, so that the model accuracy will not be negatively affected. In this paper, we first propose Spatial and Channel Attention (SCA), a new attention module combining both spatial and channel attention that respectively focuses on "where" and "what" are the most informative parts. Guided by the scale values generated by SCA for measuring channel importance, we further propose a new channel pruning approach called Channel Pruning guided by Spatial and Channel Attention (CPSCA). Experimental results indicate that SCA achieves the best inference accuracy, while incurring negligibly extra resource consumption, compared to other state-of-the-art attention modules. Our evaluation on two benchmark datasets shows that, with the guidance of SCA, our CPSCA approach achieves higher inference accuracy than other state-of-the-art pruning methods under the same pruning ratios.
An Intelligent CNN-VAE Text Representation Technology Based on Text Semantics for Comprehensive Big Data
Aug 28, 2020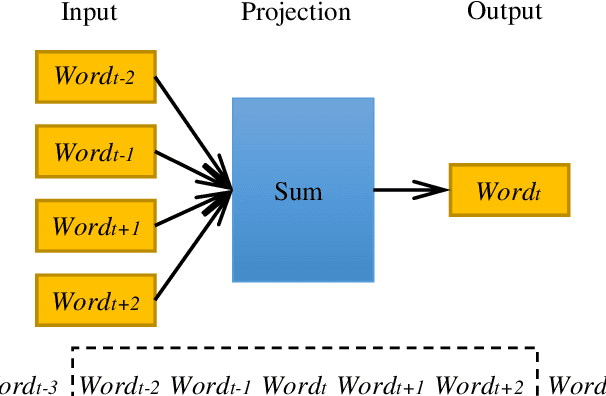
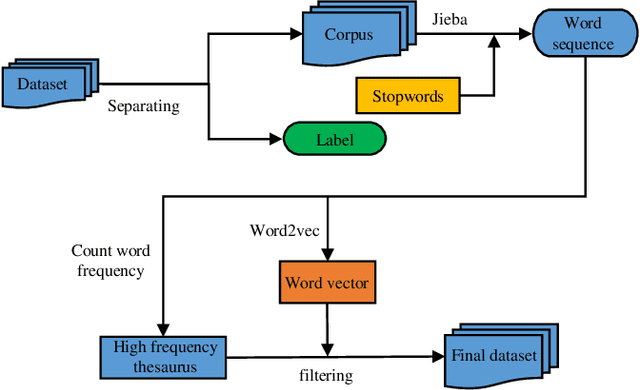
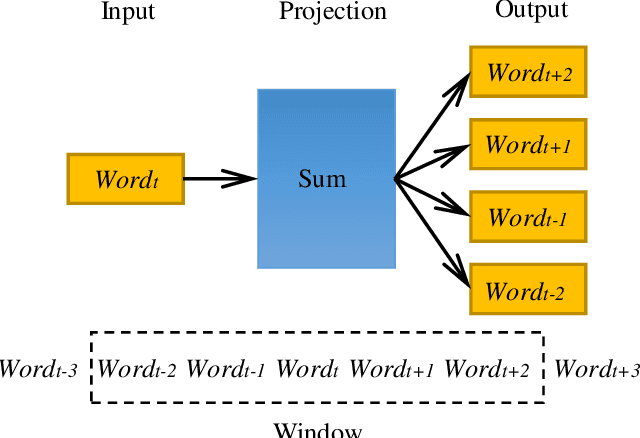
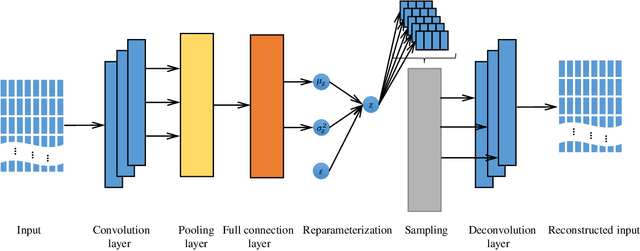
In the era of big data, a large number of text data generated by the Internet has given birth to a variety of text representation methods. In natural language processing (NLP), text representation transforms text into vectors that can be processed by computer without losing the original semantic information. However, these methods are difficult to effectively extract the semantic features among words and distinguish polysemy in language. Therefore, a text feature representation model based on convolutional neural network (CNN) and variational autoencoder (VAE) is proposed to extract the text features and apply the obtained text feature representation on the text classification tasks. CNN is used to extract the features of text vector to get the semantics among words and VAE is introduced to make the text feature space more consistent with Gaussian distribution. In addition, the output of the improved word2vec model is employed as the input of the proposed model to distinguish different meanings of the same word in different contexts. The experimental results show that the proposed model outperforms in k-nearest neighbor (KNN), random forest (RF) and support vector machine (SVM) classification algorithms.
COVID-19 Public Opinion and Emotion Monitoring System Based on Time Series Thermal New Word Mining
May 23, 2020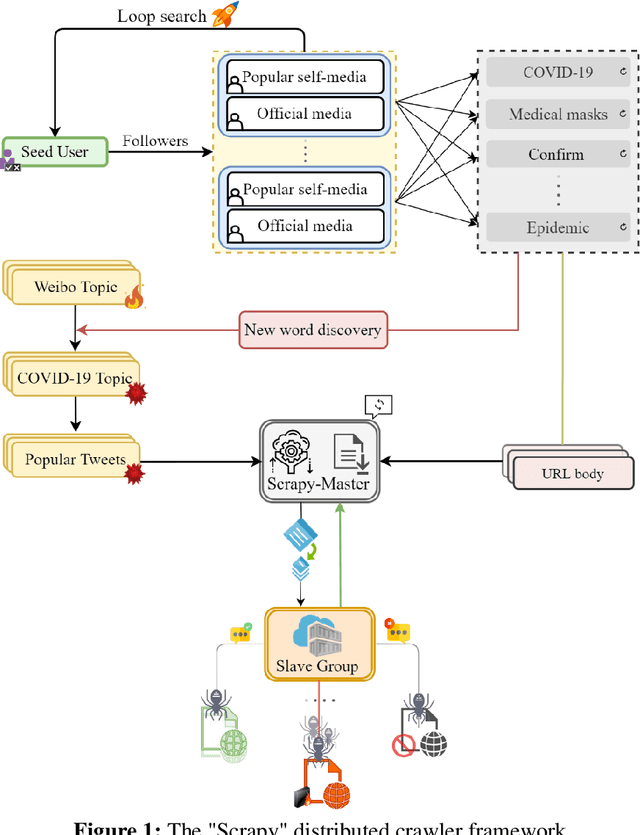
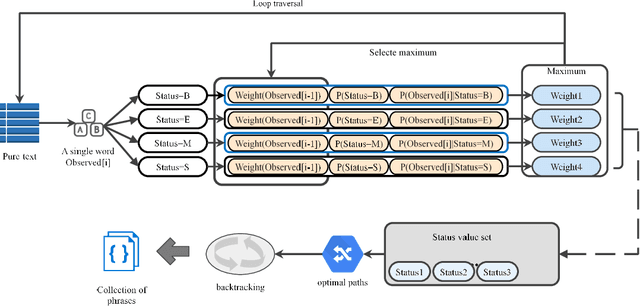
With the spread and development of new epidemics, it is of great reference value to identify the changing trends of epidemics in public emotions. We designed and implemented the COVID-19 public opinion monitoring system based on time series thermal new word mining. A new word structure discovery scheme based on the timing explosion of network topics and a Chinese sentiment analysis method for the COVID-19 public opinion environment is proposed. Establish a "Scrapy-Redis-Bloomfilter" distributed crawler framework to collect data. The system can judge the positive and negative emotions of the reviewer based on the comments, and can also reflect the depth of the seven emotions such as Hopeful, Happy, and Depressed. Finally, we improved the sentiment discriminant model of this system and compared the sentiment discriminant error of COVID-19 related comments with the Jiagu deep learning model. The results show that our model has better generalization ability and smaller discriminant error. We designed a large data visualization screen, which can clearly show the trend of public emotions, the proportion of various emotion categories, keywords, hot topics, etc., and fully and intuitively reflect the development of public opinion.
DE/RM-MEDA: A New Hybrid Multi-Objective Generator
Nov 15, 2019


Under the condition of Karush-Kuhn-Tucker, the Pareto Set (PS) in the decision area of an m-objective optimization problem is a piecewise continuous (m-1)-D manifold. For illustrate the degree of convergence of the population, we employed the ratio of the sum of the first (m-1) largest eigenvalue of the population's covariance matrix of the sum of all eigenvalue. Based on this property, this paper proposes a new algorithm, called DE/RM-MEDA, which mix differential evolutionary (DE) and the estimation of distribution algorithm (EDA) to generate and adaptively adjusts the number of new solutions by the ratio. The proposed algorithm is experimented on nine tec09 problems. The comparison results between DE/RM-MEDA and the others algorithms, called NSGA-II-DE and RM-MEDA, show that the proposed algorithm perform better in terms of convergence and diversity metric.
U-net super-neural segmentation and similarity calculation to realize vegetation change assessment in satellite imagery
Sep 10, 2019

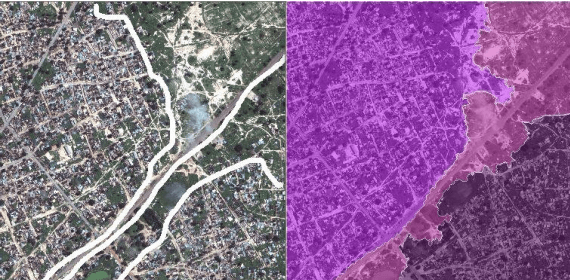
Vegetation is the natural linkage connecting soil, atmosphere and water. It can represent the change of land cover to a certain extent and serve as an indicator for global change research. Methods for measuring coverage can be divided into two types: surface measurement and remote sensing. Because vegetation cover has significant spatial and temporal differentiation characteristics, remote sensing has become an important technical means to estimate vegetation coverage. This paper firstly uses U-net to perform remote sensing image semantic segmentation training, then uses the result of semantic segmentation, and then uses the integral progressive method to calculate the forestland change rate, and finally realizes automated valuation of woodland change rate.
Graph Hierarchical Convolutional Recurrent Neural Network (GHCRNN) for Vehicle Condition Prediction
Mar 12, 2019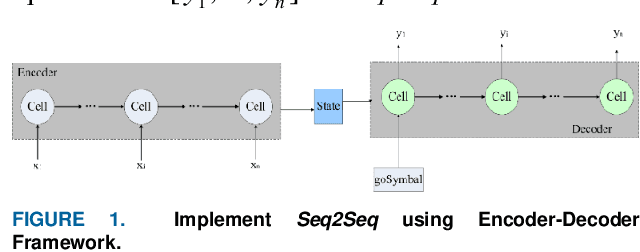
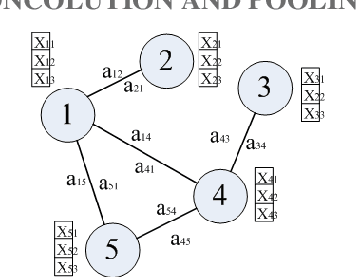
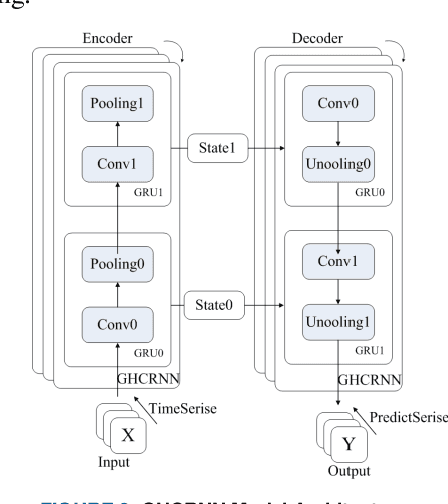
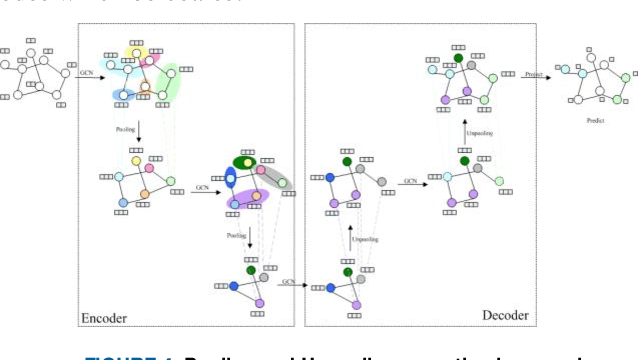
The prediction of urban vehicle flow and speed can greatly facilitate people's travel, and also can provide reasonable advice for the decision-making of relevant government departments. However, due to the spatial, temporal and hierarchy of vehicle flow and many influencing factors such as weather, it is difficult to prediction. Most of the existing research methods are to extract spatial structure information on the road network and extract time series information from the historical data. However, when extracting spatial features, these methods have higher time and space complexity, and incorporate a lot of noise. It is difficult to apply on large graphs, and only considers the influence of surrounding connected road nodes on the central node, ignoring a very important hierarchical relationship, namely, similar information of similar node features and road network structures. In response to these problems, this paper proposes the Graph Hierarchical Convolutional Recurrent Neural Network (GHCRNN) model. The model uses GCN (Graph Convolutional Networks) to extract spatial feature, GRU (Gated Recurrent Units) to extract temporal feature, and uses the learnable Pooling to extract hierarchical information, eliminate redundant information and reduce complexity. Applying this model to the vehicle flow and speed data of Shenzhen and Los Angeles has been well verified, and the time and memory consumption are effectively reduced under the compared precision.
Program Classification Using Gated Graph Attention Neural Network for Online Programming Service
Mar 09, 2019
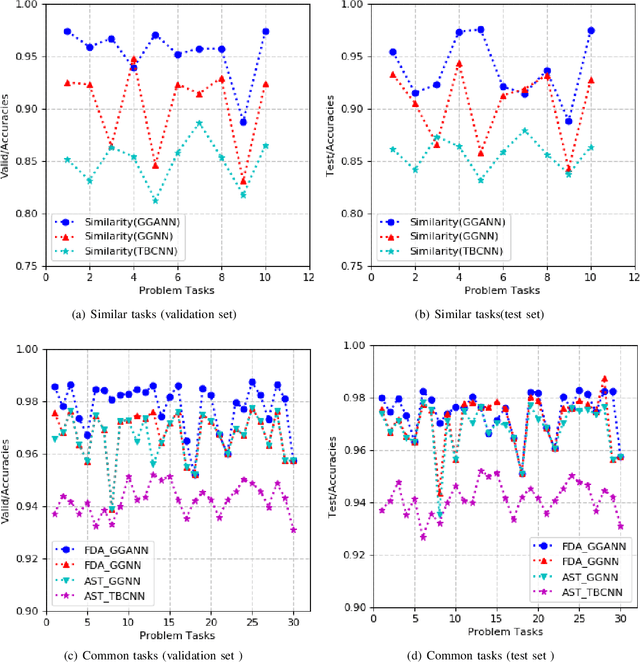
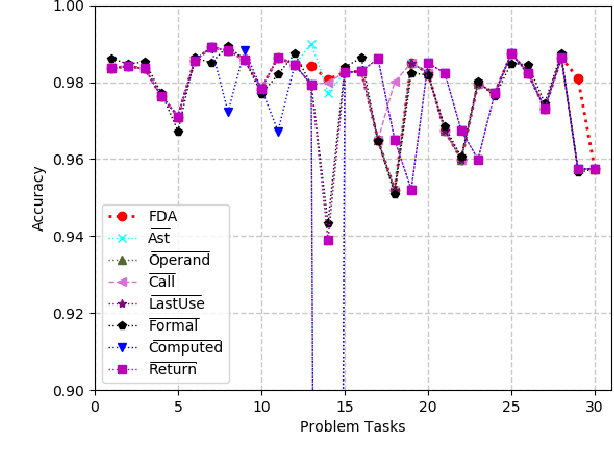

The online programing services, such as Github,TopCoder, and EduCoder, have promoted a lot of social interactions among the service users. However, the existing social interactions is rather limited and inefficient due to the rapid increasing of source-code repositories, which is difficult to explore manually. The emergence of source-code mining provides a promising way to analyze those source codes, so that those source codes can be relatively easy to understand and share among those service users. Among all the source-code mining attempts,program classification lays a foundation for various tasks related to source-code understanding, because it is impossible for a machine to understand a computer program if it cannot classify the program correctly. Although numerous machine learning models, such as the Natural Language Processing (NLP) based models and the Abstract Syntax Tree (AST) based models, have been proposed to classify computer programs based on their corresponding source codes, the existing works cannot fully characterize the source codes from the perspective of both the syntax and semantic information. To address this problem, we proposed a Graph Neural Network (GNN) based model, which integrates data flow and function call information to the AST,and applies an improved GNN model to the integrated graph, so as to achieve the state-of-art program classification accuracy. The experiment results have shown that the proposed work can classify programs with accuracy over 97%.
A novel particle swarm optimizer with multi-stage transformation and genetic operation for VLSI routing
Nov 26, 2018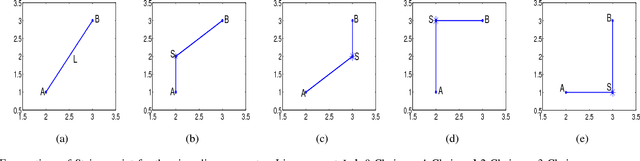
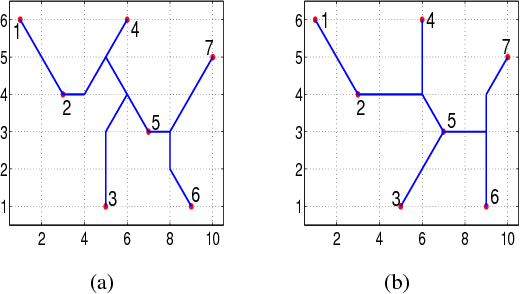


As the basic model for very large scale integration (VLSI) routing, the Steiner minimal tree (SMT) can be used in various practical problems, such as wire length optimization, congestion, and time delay estimation. In this paper, a novel particle swarm optimization (PSO) algorithm based on multi-stage transformation and genetic operation is presented to construct two types of SMT, including non-Manhattan SMT and Manhattan SMT. Firstly, in order to be able to handle two types of SMT problems at the same time, an effective edge-vertex encoding strategy is proposed. Secondly, a multi-stage transformation strategy is proposed to both expand the algorithm search space and ensure the effective convergence. We have tested three types from two to four stages and various combinations under each type to highlight the best combination. Thirdly, the genetic operators combined with union-find partition are designed to construct the discrete particle update formula for discrete VLSI routing. Moreover, in order to introduce uncertainty and diversity into the search of PSO algorithm, we propose an improved mutation operation with edge transformation. Experimental results show that our algorithm from a global perspective of multilayer structure can achieve the best solution quality among the existing algorithms. Finally, to our best knowledge, it is the first work to address both manhattan and non-manhattan routing at the same time.
An Intelligent Extraversion Analysis Scheme from Crowd Trajectories for Surveillance
Sep 27, 2018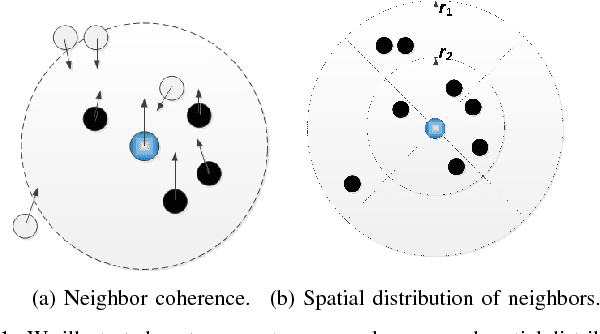
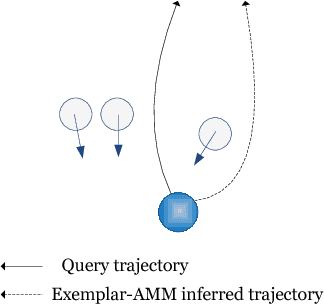

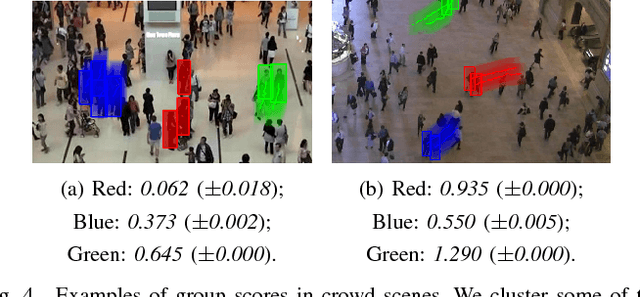
In recent years, crowd analysis is important for applications such as smart cities, intelligent transportation system, customer behavior prediction, and visual surveillance. Understanding the characteristics of the individual motion in a crowd can be beneficial for social event detection and abnormal detection, but it has rarely been studied. In this paper, we focus on the extraversion measure of individual motions in crowds based on trajectory data. Extraversion is one of typical personalities that is often observed in human crowd behaviors and it can reflect not only the characteristics of the individual motion, but also the that of the holistic crowd motions. To our best knowledge, this is the first attempt to analyze individual extraversion of crowd motions based on trajectories. To accomplish this, we first present a effective composite motion descriptor, which integrates the basic individual motion information and social metrics, to describe the extraversion of each individual in a crowd. The social metrics consider both the neighboring distribution and their interaction pattern. Since our major goal is to learn a universal scoring function that can measure the degrees of extraversion across varied crowd scenes, we incorporate and adapt the active learning technique to the relative attribute approach. Specifically, we assume the social groups in any crowds contain individuals with the similar degree of extraversion. Based on such assumption, we significantly reduce the computation cost by clustering and ranking the trajectories actively. Finally, we demonstrate the performance of our proposed method by measuring the degree of extraversion for real individual trajectories in crowds and analyzing crowd scenes from a real-world dataset.