 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing Visually Similar Actions: Prompt-Guided Semantic Prototype Modulation for Few-Shot Action Recognition
Dec 22, 2025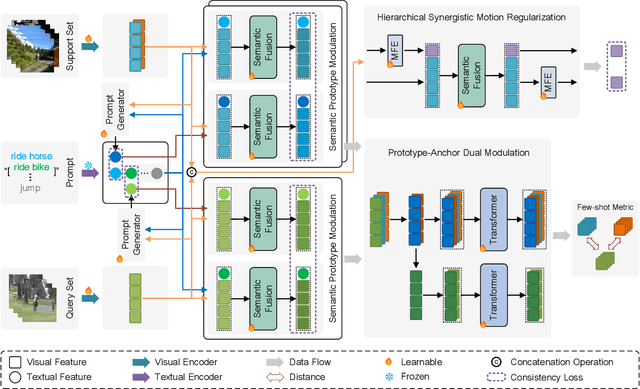
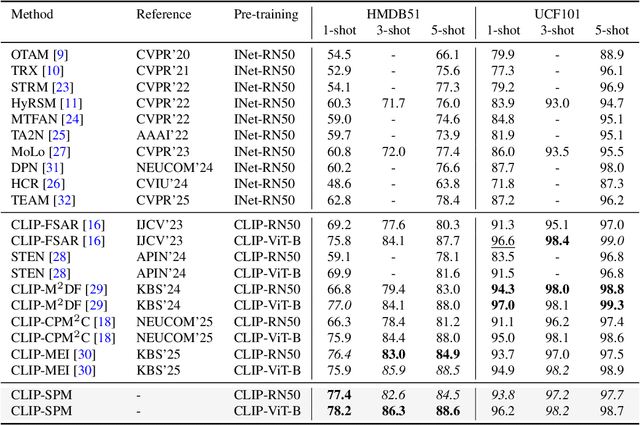
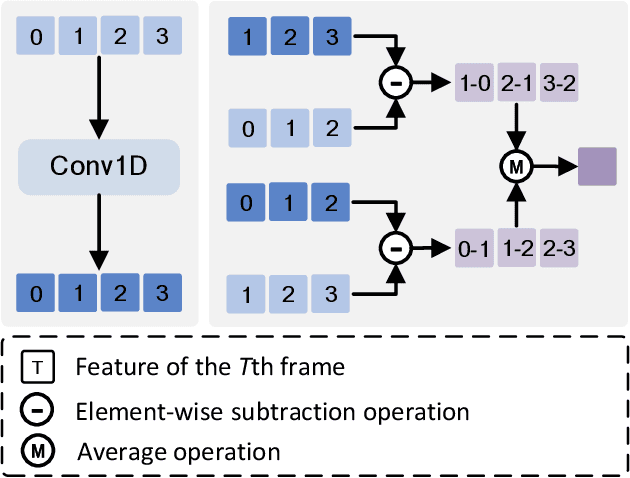
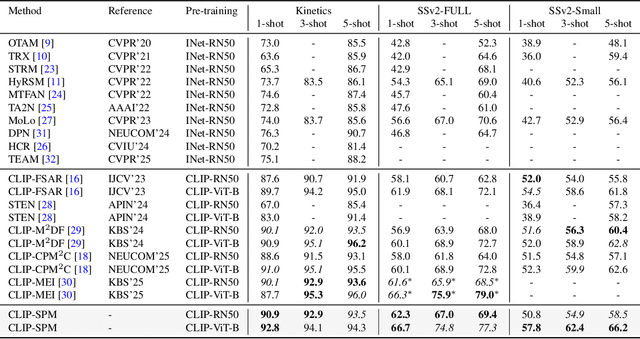
Few-shot action recognition aims to enable models to quickly learn new action categories from limited labeled samples, addressing the challenge of data scarcity in real-world applications. Current research primarily addresses three core challenges: (1) temporal modeling, where models are prone to interference from irrelevant static background information and struggle to capture the essence of dynamic action features; (2) visual similarity, where categories with subtle visual differences are difficult to distinguish; and (3) the modality gap between visual-textual support prototypes and visual-only queries, which complicates alignment within a shared embedding space. To address these challenges, this paper proposes a CLIP-SPM framework, which includes three components: (1) the Hierarchical Synergistic Motion Refinement (HSMR) module, which aligns deep and shallow motion features to improve temporal modeling by reducing static background interference; (2) the Semantic Prototype Modulation (SPM) strategy, which generates query-relevant text prompts to bridge the modality gap and integrates them with visual features, enhancing the discriminability between similar actions; and (3) the Prototype-Anchor Dual Modulation (PADM) method, which refines support prototypes and aligns query features with a global semantic anchor, improving consistency across support and query samples. Comprehensive experiments across standard benchmarks, including Kinetics, SSv2-Full, SSv2-Small, UCF101, and HMDB51, demonstrate that our CLIP-SPM achieves competitive performance under 1-shot, 3-shot, and 5-shot settings. Extensive ablation studies and visual analyses further validate the effectiveness of each component and its contributions to addressing the core challenges. The source code and models are publicly available at GitHub.
Efficiently Enhancing General Agents With Hierarchical-categorical Memory
May 28, 2025With large language models (LLMs) demonstrating remarkable capabilities, there has been a surge in research on leveraging LLMs to build general-purpose multi-modal agents. However, existing approaches either rely on computationally expensive end-to-end training using large-scale multi-modal data or adopt tool-use methods that lack the ability to continuously learn and adapt to new environments. In this paper, we introduce EHC, a general agent capable of learning without parameter updates. EHC consists of a Hierarchical Memory Retrieval (HMR) module and a Task-Category Oriented Experience Learning (TOEL) module. The HMR module facilitates rapid retrieval of relevant memories and continuously stores new information without being constrained by memory capacity. The TOEL module enhances the agent's comprehension of various task characteristics by classifying experiences and extracting patterns across different categories. Extensive experiments conducted on multiple standard datasets demonstrate that EHC outperforms existing methods, achieving state-of-the-art performance and underscoring its effectiveness as a general agent for handling complex multi-modal tasks.
Spatio-Temporal Sparsification for General Robust Graph Convolution Networks
Mar 23, 2021

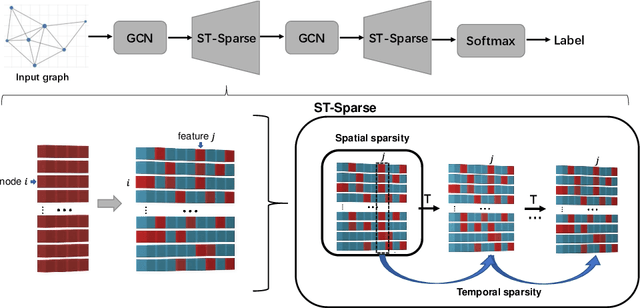
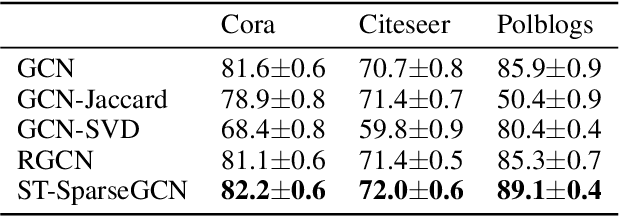
Graph Neural Networks (GNNs) have attracted increasing attention due to its successful applications on various graph-structure data. However, recent studies have shown that adversarial attacks are threatening the functionality of GNNs. Although numerous works have been proposed to defend adversarial attacks from various perspectives, most of them can be robust against the attacks only on specific scenarios. To address this shortage of robust generalization, we propose to defend the adversarial attacks on GNN through applying the Spatio-Temporal sparsification (called ST-Sparse) on the GNN hidden node representation. ST-Sparse is similar to the Dropout regularization in spirit. Through intensive experiment evaluation with GCN as the target GNN model, we identify the benefits of ST-Sparse as follows: (1) ST-Sparse shows the defense performance improvement in most cases, as it can effectively increase the robust accuracy by up to 6\% improvement; (2) ST-Sparse illustrates its robust generalization capability by integrating with the existing defense methods, similar to the integration of Dropout into various deep learning models as a standard regularization technique; (3) ST-Sparse also shows its ordinary generalization capability on clean datasets, in that ST-SparseGCN (the integration of ST-Sparse and the original GCN) even outperform the original GCN, while the other three representative defense methods are inferior to the original GCN.
Urban Traffic Flow Forecast Based on FastGCRNN
Sep 17, 2020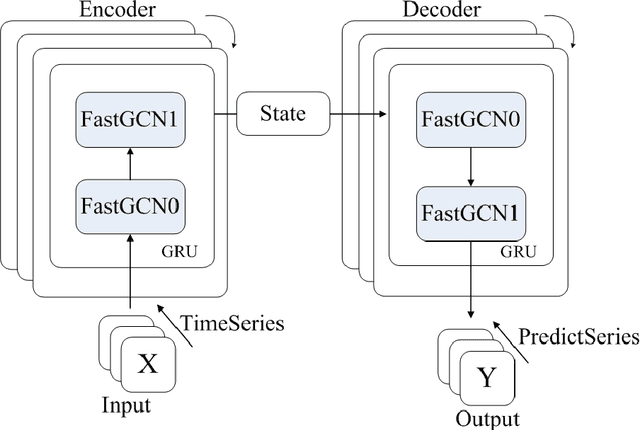


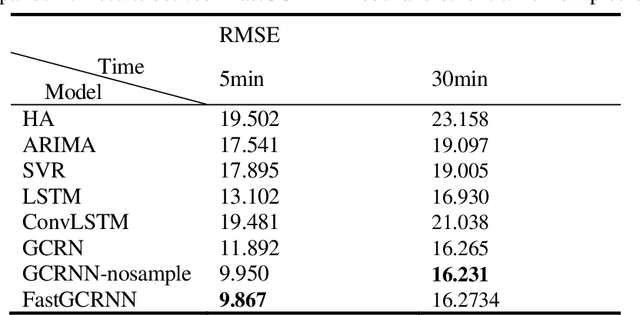
Traffic forecasting is an important prerequisite for the application of intelligent transportation systems in urban traffic networks. The existing works adopted RNN and CNN/GCN, among which GCRN is the state of art work, to characterize the temporal and spatial correlation of traffic flows. However, it is hard to apply GCRN to the large scale road networks due to high computational complexity. To address this problem, we propose to abstract the road network into a geometric graph and build a Fast Graph Convolution Recurrent Neural Network (FastGCRNN) to model the spatial-temporal dependencies of traffic flow. Specifically, We use FastGCN unit to efficiently capture the topological relationship between the roads and the surrounding roads in the graph with reducing the computational complexity through importance sampling, combine GRU unit to capture the temporal dependency of traffic flow, and embed the spatiotemporal features into Seq2Seq based on the Encoder-Decoder framework. Experiments on large-scale traffic data sets illustrate that the proposed method can greatly reduce computational complexity and memory consumption while maintaining relatively high accuracy.
Interpreting and Understanding Graph Convolutional Neural Network using Gradient-based Attribution Method
Apr 16, 2019


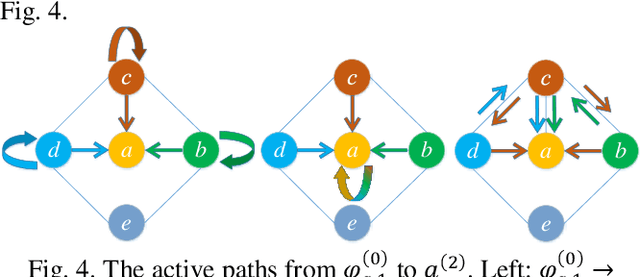
To solve the problem that convolutional neural networks (CNNs) are difficult to process non-grid type relational data like graphs, Kipf et al. proposed a graph convolutional neural network (GCN). The core idea of the GCN is to perform two-fold informational fusion for each node in a given graph during each iteration: the fusion of graph structure information and the fusion of node feature dimensions. Because of the characteristic of the combinatorial generalizations, GCN has been widely used in the fields of scene semantic relationship analysis, natural language processing and few-shot learning etc. However, due to its two-fold informational fusion involves mathematical irreversible calculations, it is hard to explain the decision reason for the prediction of the each node classification. Unfortunately, most of the existing attribution analysis methods concentrate on the models like CNNs, which are utilized to process grid-like data. It is difficult to apply those analysis methods to the GCN directly. It is because compared with the independence among CNNs input data, there is correlation between the GCN input data. This resulting in the existing attribution analysis methods can only obtain the partial model contribution from the central node features to the final decision of the GCN, but ignores the other model contribution from central node features and its neighbor nodes features to that decision. To this end, we propose a gradient attribution analysis method for the GCN called Node Attribution Method (NAM), which can get the model contribution from not only the central node but also its neighbor nodes to the GCN output. We also propose the Node Importance Visualization (NIV) method to visualize the central node and its neighbor nodes based on the value of the contribution...
Graph Hierarchical Convolutional Recurrent Neural Network (GHCRNN) for Vehicle Condition Prediction
Mar 12, 2019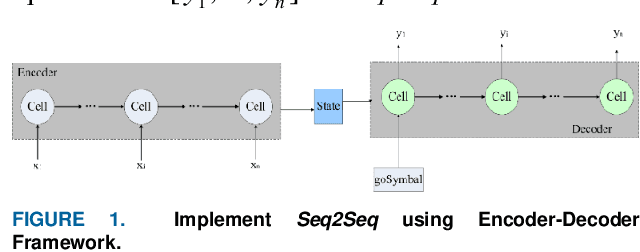
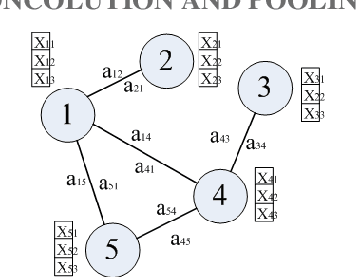
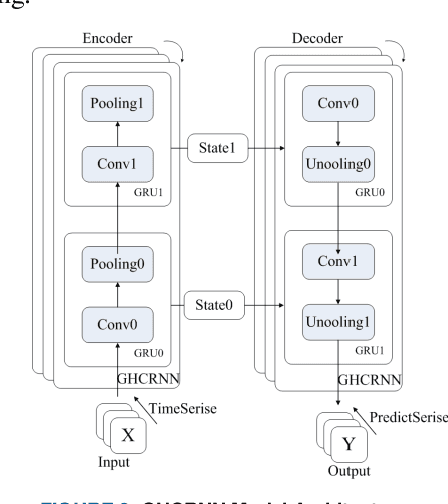
The prediction of urban vehicle flow and speed can greatly facilitate people's travel, and also can provide reasonable advice for the decision-making of relevant government departments. However, due to the spatial, temporal and hierarchy of vehicle flow and many influencing factors such as weather, it is difficult to prediction. Most of the existing research methods are to extract spatial structure information on the road network and extract time series information from the historical data. However, when extracting spatial features, these methods have higher time and space complexity, and incorporate a lot of noise. It is difficult to apply on large graphs, and only considers the influence of surrounding connected road nodes on the central node, ignoring a very important hierarchical relationship, namely, similar information of similar node features and road network structures. In response to these problems, this paper proposes the Graph Hierarchical Convolutional Recurrent Neural Network (GHCRNN) model. The model uses GCN (Graph Convolutional Networks) to extract spatial feature, GRU (Gated Recurrent Units) to extract temporal feature, and uses the learnable Pooling to extract hierarchical information, eliminate redundant information and reduce complexity. Applying this model to the vehicle flow and speed data of Shenzhen and Los Angeles has been well verified, and the time and memory consumption are effectively reduced under the compared precision.
Program Classification Using Gated Graph Attention Neural Network for Online Programming Service
Mar 09, 2019
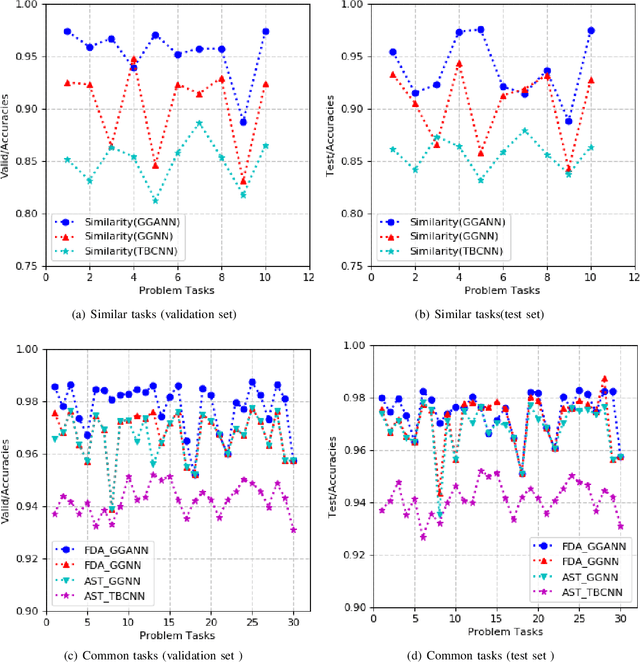
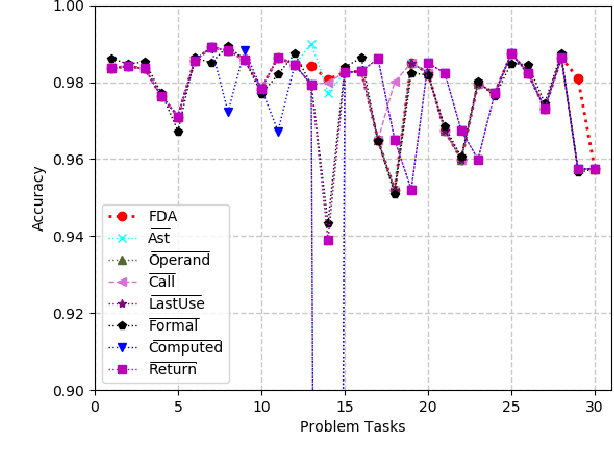

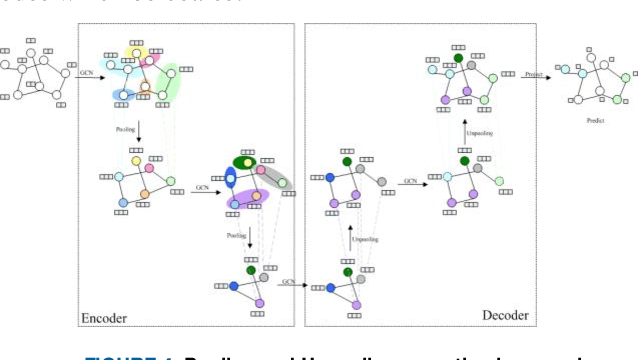
The online programing services, such as Github,TopCoder, and EduCoder, have promoted a lot of social interactions among the service users. However, the existing social interactions is rather limited and inefficient due to the rapid increasing of source-code repositories, which is difficult to explore manually. The emergence of source-code mining provides a promising way to analyze those source codes, so that those source codes can be relatively easy to understand and share among those service users. Among all the source-code mining attempts,program classification lays a foundation for various tasks related to source-code understanding, because it is impossible for a machine to understand a computer program if it cannot classify the program correctly. Although numerous machine learning models, such as the Natural Language Processing (NLP) based models and the Abstract Syntax Tree (AST) based models, have been proposed to classify computer programs based on their corresponding source codes, the existing works cannot fully characterize the source codes from the perspective of both the syntax and semantic information. To address this problem, we proposed a Graph Neural Network (GNN) based model, which integrates data flow and function call information to the AST,and applies an improved GNN model to the integrated graph, so as to achieve the state-of-art program classification accuracy. The experiment results have shown that the proposed work can classify programs with accuracy over 97%.
Based on Graph-VAE Model to Predict Student's Score
Mar 08, 2019The OECD pointed out that the best way to keep students up to school is to intervene as early as possible [1]. Using education big data and deep learning to predict student's score provides new resources and perspectives for early intervention. Previous forecasting schemes often requires manual filter of features , a large amount of prior knowledge and expert knowledge. Deep learning can automatically extract features without manual intervention to achieve better predictive performance. In this paper, the graph neural network matrix filling model (Graph-VAE) based on deep learning can automatically extract features without a large amount of prior knowledge. The experiment proves that our model is better than the traditional solution in the student's score dataset, and it better describes the correlation and difference between the students and the curriculum, and dimensionality reducing the vector of coding result is visualized, the clustering effect is consistent with the real data distribution clustering. In addition, we use gradient-based attribution methods to analyze the key factors that influence performance prediction.