 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Symmetric Equilibrium Generative Adversarial Network with Attention Refine Block for Retinal Vessel Segmentation
Sep 26, 2019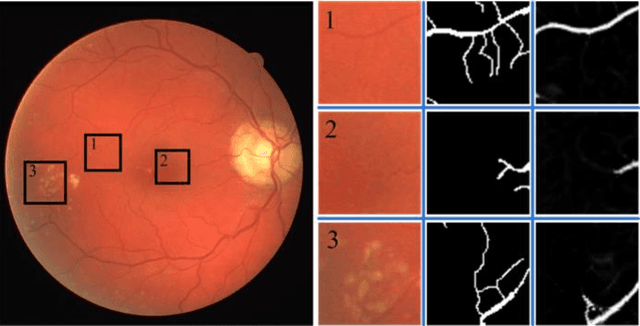
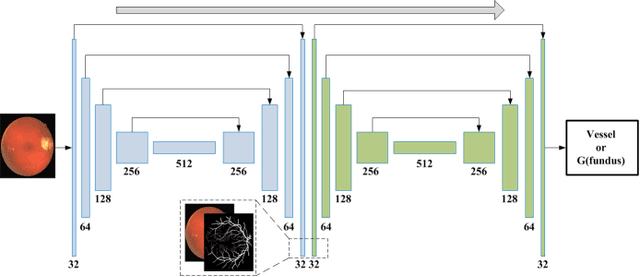
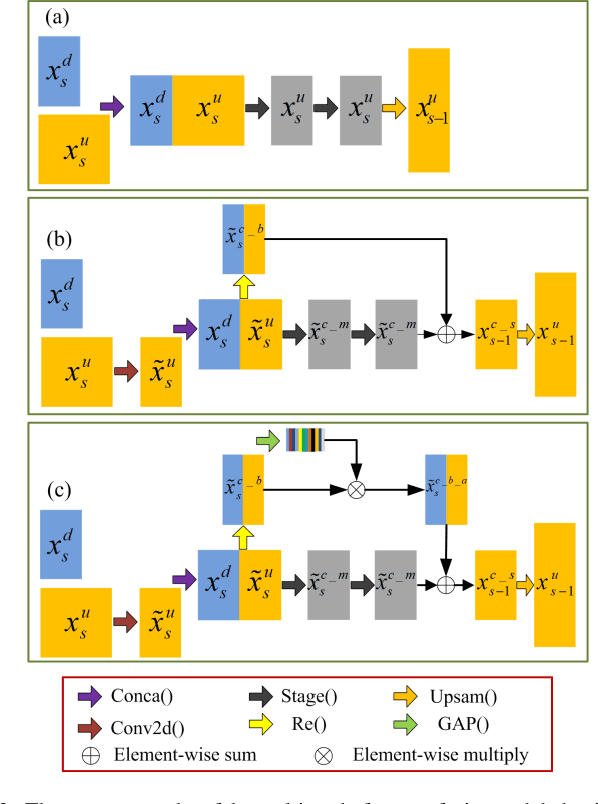
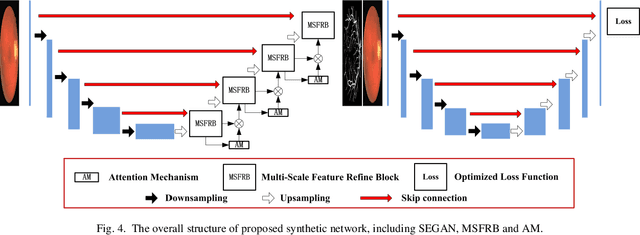
Objective: Recognizing retinal fundus vessel abnormity is vital to early diagnosis of ophthalmological diseases and cardiovascular events. However, segmentation results are highly influenced by elusive thin vessels. In this work, we present a synthetic network, including a symmetric equilibrium generative adversarial network (SEGAN), mul-ti-scale features refine blocks (MSFRB), and attention mechanism (AM) to enhance the performance on vessel segmentation especially for thin vessels. Method: The proposed network is granted powerful multi-scale repre-sentation capability. First, SEGAN is proposed to construct a symmetric adversarial architecture, which forces gener-ator to produce more realistic images with local details. Second, MSFRB are devised to prevent high-resolution features from being obscured, thereby preserving multi-scale features. Finally, the AM is employed to encourage the network to concentrate on discriminative features. Results: On public dataset DRIVE, STARE, and CHASEDB1, we evaluate our network quantitatively and compare it with state-of-the-art works. The ablation experiment shows that SEGAN, MSFRB, and AM both contribute to the desirable performance of our network. Conclusion: The proposed network outperforms other strategies and effectively functions in elusive vessels segmentation, achieving highest scores in Sensitivity, G-Mean, Precision, and F1-Score while maintaining the top level in other metrics. Significance: The appreciable per-formance and high computational efficiency offer great potential in clinical retinal vessel segmentation application. Meanwhile, the network could be utilized to extract detail information on other biomedical issues.
Dual-attention Focused Module for Weakly Supervised Object Localization
Sep 11, 2019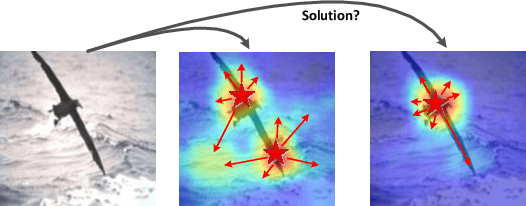

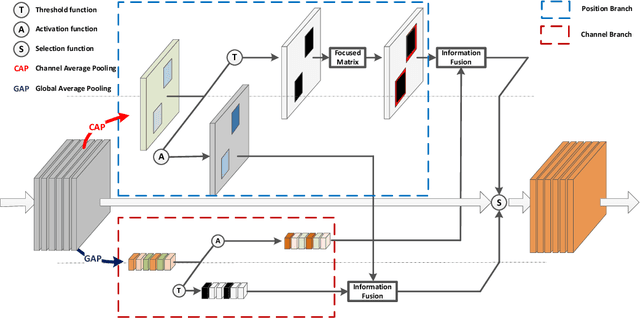
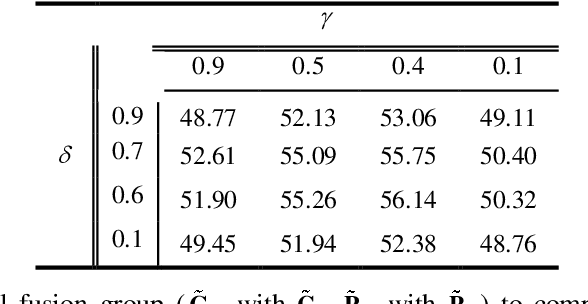
The research on recognizing the most discriminative regions provides referential information for weakly supervised object localization with only image-level annotations. However, the most discriminative regions usually conceal the other parts of the object, thereby impeding entire object recognition and localization. To tackle this problem, the Dual-attention Focused Module (DFM) is proposed to enhance object localization performance. Specifically, we present a dual attention module for information fusion, consisting of a position branch and a channel one. In each branch, the input feature map is deduced into an enhancement map and a mask map, thereby highlighting the most discriminative parts or hiding them. For the position mask map, we introduce a focused matrix to enhance it, which utilizes the principle that the pixels of an object are continuous. Between these two branches, the enhancement map is integrated with the mask map, aiming at partially compensating the lost information and diversifies the features. With the dual-attention module and focused matrix, the entire object region could be precisely recognized with implicit information. We demonstrate outperforming results of DFM in experiments. In particular, DFM achieves state-of-the-art performance in localization accuracy in ILSVRC 2016 and CUB-200-2011.
DDNet: Cartesian-polar Dual-domain Network for the Joint Optic Disc and Cup Segmentation
Apr 18, 2019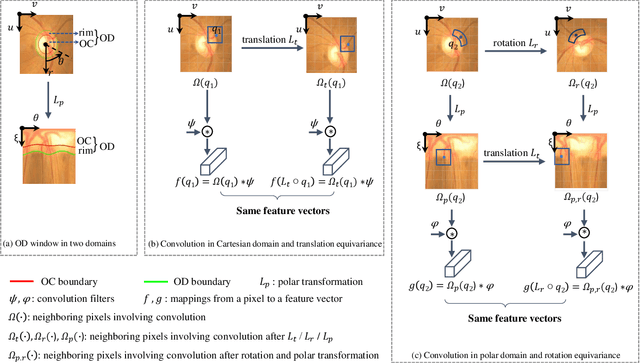

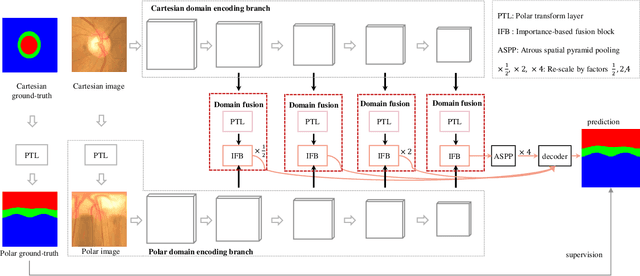
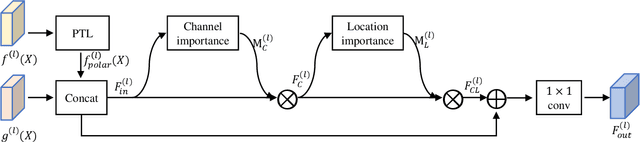
Existing joint optic disc and cup segmentation approaches are developed either in Cartesian or polar coordinate system. However, due to the subtle optic cup, the contextual information exploited from the single domain even by the prevailing CNNs is still insufficient. In this paper, we propose a novel segmentation approach, named Cartesian-polar dual-domain network (DDNet), which for the first time considers the complementary of the Cartesian domain and the polar domain. We propose a two-branch of domain feature encoder and learn translation equivariant representations on rectilinear grid from Cartesian domain and rotation equivariant representations on polar grid from polar domain parallelly. To fuse the features on two different grids, we propose a dual-domain fusion module. This module builds the correspondence between two grids by the differentiable polar transform layer and learns the feature importance across two domains in element-wise to enhance the expressive capability. Finally, the decoder aggregates the fused features from low-level to high-level and makes dense predictions. We validate the state-of-the-art segmentation performances of our DDNet on the public dataset ORIGA. According to the segmentation masks, we estimate the commonly used clinical measure for glaucoma, i.e., the vertical cup-to-disc ratio. The low cup-to-disc ratio estimation error demonstrates the potential application in glaucoma screening.
Program Classification Using Gated Graph Attention Neural Network for Online Programming Service
Mar 09, 2019
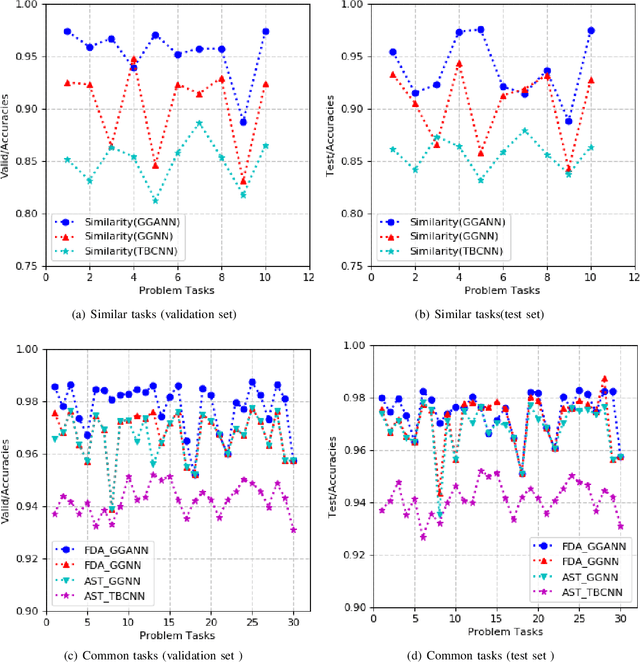
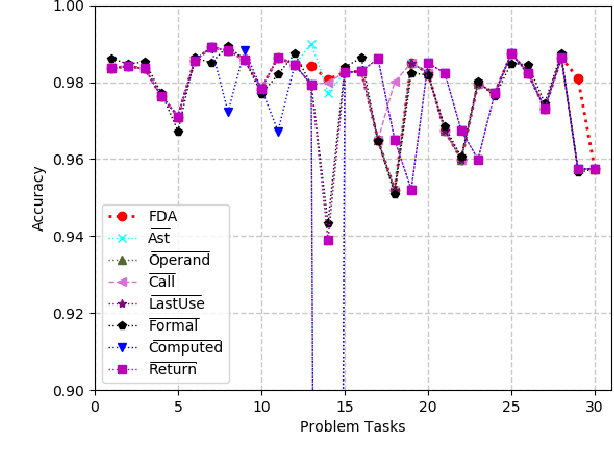

The online programing services, such as Github,TopCoder, and EduCoder, have promoted a lot of social interactions among the service users. However, the existing social interactions is rather limited and inefficient due to the rapid increasing of source-code repositories, which is difficult to explore manually. The emergence of source-code mining provides a promising way to analyze those source codes, so that those source codes can be relatively easy to understand and share among those service users. Among all the source-code mining attempts,program classification lays a foundation for various tasks related to source-code understanding, because it is impossible for a machine to understand a computer program if it cannot classify the program correctly. Although numerous machine learning models, such as the Natural Language Processing (NLP) based models and the Abstract Syntax Tree (AST) based models, have been proposed to classify computer programs based on their corresponding source codes, the existing works cannot fully characterize the source codes from the perspective of both the syntax and semantic information. To address this problem, we proposed a Graph Neural Network (GNN) based model, which integrates data flow and function call information to the AST,and applies an improved GNN model to the integrated graph, so as to achieve the state-of-art program classification accuracy. The experiment results have shown that the proposed work can classify programs with accuracy over 97%.