 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Data Sampling in Multimodal Post-training from a Difficulty-Distinguish View
Nov 10, 2025Recent advances in Multimodal Large Language Models (MLLMs) have spurred significant progress in Chain-of-Thought (CoT) reasoning. Building on the success of Deepseek-R1, researchers extended multimodal reasoning to post-training paradigms based on reinforcement learning (RL), focusing predominantly on mathematical datasets. However, existing post-training paradigms tend to neglect two critical aspects: (1) The lack of quantifiable difficulty metrics capable of strategically screening samples for post-training optimization. (2) Suboptimal post-training paradigms that fail to jointly optimize perception and reasoning capabilities. To address this gap, we propose two novel difficulty-aware sampling strategies: Progressive Image Semantic Masking (PISM) quantifies sample hardness through systematic image degradation, while Cross-Modality Attention Balance (CMAB) assesses cross-modal interaction complexity via attention distribution analysis. Leveraging these metrics, we design a hierarchical training framework that incorporates both GRPO-only and SFT+GRPO hybrid training paradigms, and evaluate them across six benchmark datasets. Experiments demonstrate consistent superiority of GRPO applied to difficulty-stratified samples compared to conventional SFT+GRPO pipelines, indicating that strategic data sampling can obviate the need for supervised fine-tuning while improving model accuracy. Our code will be released at https://github.com/qijianyu277/DifficultySampling.
SWinMamba: Serpentine Window State Space Model for Vascular Segmentation
Jul 02, 2025Vascular segmentation in medical images is crucial for disease diagnosis and surgical navigation. However, the segmented vascular structure is often discontinuous due to its slender nature and inadequate prior modeling. In this paper, we propose a novel Serpentine Window Mamba (SWinMamba) to achieve accurate vascular segmentation. The proposed SWinMamba innovatively models the continuity of slender vascular structures by incorporating serpentine window sequences into bidirectional state space models. The serpentine window sequences enable efficient feature capturing by adaptively guiding global visual context modeling to the vascular structure. Specifically, the Serpentine Window Tokenizer (SWToken) adaptively splits the input image using overlapping serpentine window sequences, enabling flexible receptive fields (RFs) for vascular structure modeling. The Bidirectional Aggregation Module (BAM) integrates coherent local features in the RFs for vascular continuity representation. In addition, dual-domain learning with Spatial-Frequency Fusion Unit (SFFU) is designed to enhance the feature representation of vascular structure. Extensive experiments on three challenging datasets demonstrate that the proposed SWinMamba achieves superior performance with complete and connected vessels.
CAD-VAE: Leveraging Correlation-Aware Latents for Comprehensive Fair Disentanglement
Mar 11, 2025While deep generative models have significantly advanced representation learning, they may inherit or amplify biases and fairness issues by encoding sensitive attributes alongside predictive features. Enforcing strict independence in disentanglement is often unrealistic when target and sensitive factors are naturally correlated. To address this challenge, we propose CAD-VAE (Correlation-Aware Disentangled VAE), which introduces a correlated latent code to capture the shared information between target and sensitive attributes. Given this correlated latent, our method effectively separates overlapping factors without extra domain knowledge by directly minimizing the conditional mutual information between target and sensitive codes. A relevance-driven optimization strategy refines the correlated code by efficiently capturing essential correlated features and eliminating redundancy. Extensive experiments on benchmark datasets demonstrate that CAD-VAE produces fairer representations, realistic counterfactuals, and improved fairness-aware image editing.
SegACIL: Solving the Stability-Plasticity Dilemma in Class-Incremental Semantic Segmentation
Dec 14, 2024While deep learning has made remarkable progress in recent years, models continue to struggle with catastrophic forgetting when processing continuously incoming data. This issue is particularly critical in continual learning, where the balance between retaining prior knowledge and adapting to new information-known as the stability-plasticity dilemma-remains a significant challenge. In this paper, we propose SegACIL, a novel continual learning method for semantic segmentation based on a linear closed-form solution. Unlike traditional methods that require multiple epochs for training, SegACIL only requires a single epoch, significantly reducing computational costs. Furthermore, we provide a theoretical analysis demonstrating that SegACIL achieves performance on par with joint learning, effectively retaining knowledge from previous data which makes it to keep both stability and plasticity at the same time. Extensive experiments on the Pascal VOC2012 dataset show that SegACIL achieves superior performance in the sequential, disjoint, and overlap settings, offering a robust solution to the challenges of class-incremental semantic segmentation. Code is available at https://github.com/qwrawq/SegACIL.
Dual-attention Focused Module for Weakly Supervised Object Localization
Sep 11, 2019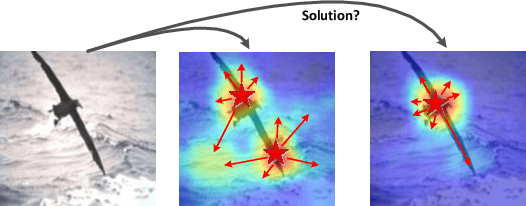

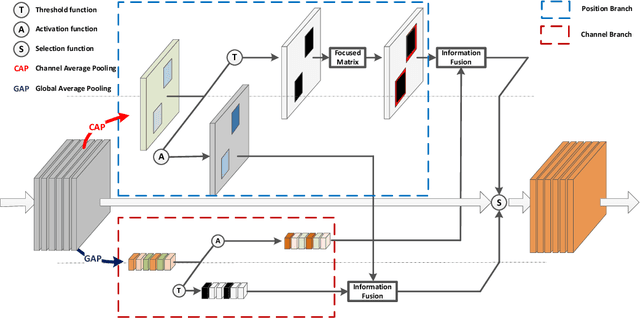
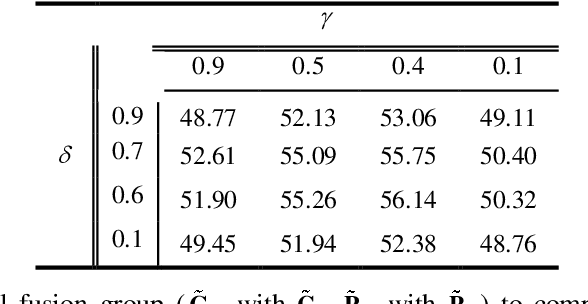
The research on recognizing the most discriminative regions provides referential information for weakly supervised object localization with only image-level annotations. However, the most discriminative regions usually conceal the other parts of the object, thereby impeding entire object recognition and localization. To tackle this problem, the Dual-attention Focused Module (DFM) is proposed to enhance object localization performance. Specifically, we present a dual attention module for information fusion, consisting of a position branch and a channel one. In each branch, the input feature map is deduced into an enhancement map and a mask map, thereby highlighting the most discriminative parts or hiding them. For the position mask map, we introduce a focused matrix to enhance it, which utilizes the principle that the pixels of an object are continuous. Between these two branches, the enhancement map is integrated with the mask map, aiming at partially compensating the lost information and diversifies the features. With the dual-attention module and focused matrix, the entire object region could be precisely recognized with implicit information. We demonstrate outperforming results of DFM in experiments. In particular, DFM achieves state-of-the-art performance in localization accuracy in ILSVRC 2016 and CUB-200-2011.