 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Detection-to-Abstention Gap in Reasoning Models under Insufficient Information
May 27, 2026We highlight a failure mode of large reasoning models on questions with insufficient information: models may recognize that a problem is under-specified, yet still continue reasoning and produce unsupported final answers instead of abstaining. We formalize this mismatch as the detection-to-abstention gap, where detected insufficiency fails to translate into final abstention. This gap is especially concerning in high-risk domains such as medical AI, where answers based on incomplete evidence can be more harmful than refusal. To close this gap, we propose Judge-Then-Solve (JTS), a trajectory-level reasoning-control framework that trains models to make an explicit answerability commitment before solution generation. Rather than treating abstention as a final-answer style, JTS casts it as a control decision: the model either proceeds to solve or terminates early based on its answerability judgment. We instantiate this policy through supervised warm-up and missing-premise reinforcement learning with consistency and length-shaping rewards. Experiments on dense and MoE reasoning models show that JTS substantially improves reliable abstention across datasets and pushes Abstention@Detection (A@D) to near-saturation, indicating that models not only detect missing information but also act on that detection. By terminating unanswerable trajectories immediately after the answerability judgment, JTS reduces unnecessary reasoning and improves inference efficiency when continued deliberation would amplify unsupported assumptions. We also observe that missing-premise training can alter reasoning behavior on difficult but answerable problems, reducing unproductive self-reflection. These results suggest that abstention under insufficient information is a key form of reasoning control for deploying reasoning models safely and efficiently.
DeepAFL: Deep Analytic Federated Learning
Feb 28, 2026Federated Learning (FL) is a popular distributed learning paradigm to break down data silo. Traditional FL approaches largely rely on gradient-based updates, facing significant issues about heterogeneity, scalability, convergence, and overhead, etc. Recently, some analytic-learning-based work has attempted to handle these issues by eliminating gradient-based updates via analytical (i.e., closed-form) solutions. Despite achieving superior invariance to data heterogeneity, these approaches are fundamentally limited by their single-layer linear model with a frozen pre-trained backbone. As a result, they can only achieve suboptimal performance due to their lack of representation learning capabilities. In this paper, to enable representable analytic models while preserving the ideal invariance to data heterogeneity for FL, we propose our Deep Analytic Federated Learning approach, named DeepAFL. Drawing inspiration from the great success of ResNet in gradient-based learning, we design gradient-free residual blocks in our DeepAFL with analytical solutions. We introduce an efficient layer-wise protocol for training our deep analytic models layer by layer in FL through least squares. Both theoretical analyses and empirical evaluations validate our DeepAFL's superior performance with its dual advantages in heterogeneity invariance and representation learning, outperforming state-of-the-art baselines by up to 5.68%-8.42% across three benchmark datasets.
Revisiting the Data Sampling in Multimodal Post-training from a Difficulty-Distinguish View
Nov 10, 2025Recent advances in Multimodal Large Language Models (MLLMs) have spurred significant progress in Chain-of-Thought (CoT) reasoning. Building on the success of Deepseek-R1, researchers extended multimodal reasoning to post-training paradigms based on reinforcement learning (RL), focusing predominantly on mathematical datasets. However, existing post-training paradigms tend to neglect two critical aspects: (1) The lack of quantifiable difficulty metrics capable of strategically screening samples for post-training optimization. (2) Suboptimal post-training paradigms that fail to jointly optimize perception and reasoning capabilities. To address this gap, we propose two novel difficulty-aware sampling strategies: Progressive Image Semantic Masking (PISM) quantifies sample hardness through systematic image degradation, while Cross-Modality Attention Balance (CMAB) assesses cross-modal interaction complexity via attention distribution analysis. Leveraging these metrics, we design a hierarchical training framework that incorporates both GRPO-only and SFT+GRPO hybrid training paradigms, and evaluate them across six benchmark datasets. Experiments demonstrate consistent superiority of GRPO applied to difficulty-stratified samples compared to conventional SFT+GRPO pipelines, indicating that strategic data sampling can obviate the need for supervised fine-tuning while improving model accuracy. Our code will be released at https://github.com/qijianyu277/DifficultySampling.
ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.
SegACIL: Solving the Stability-Plasticity Dilemma in Class-Incremental Semantic Segmentation
Dec 14, 2024While deep learning has made remarkable progress in recent years, models continue to struggle with catastrophic forgetting when processing continuously incoming data. This issue is particularly critical in continual learning, where the balance between retaining prior knowledge and adapting to new information-known as the stability-plasticity dilemma-remains a significant challenge. In this paper, we propose SegACIL, a novel continual learning method for semantic segmentation based on a linear closed-form solution. Unlike traditional methods that require multiple epochs for training, SegACIL only requires a single epoch, significantly reducing computational costs. Furthermore, we provide a theoretical analysis demonstrating that SegACIL achieves performance on par with joint learning, effectively retaining knowledge from previous data which makes it to keep both stability and plasticity at the same time. Extensive experiments on the Pascal VOC2012 dataset show that SegACIL achieves superior performance in the sequential, disjoint, and overlap settings, offering a robust solution to the challenges of class-incremental semantic segmentation. Code is available at https://github.com/qwrawq/SegACIL.
TS-ACL: A Time Series Analytic Continual Learning Framework for Privacy-Preserving and Class-Incremental Pattern Recognition
Oct 21, 2024



Class-incremental Learning (CIL) in Time Series Classification (TSC) aims to incrementally train models using the streaming time series data that arrives continuously. The main problem in this scenario is catastrophic forgetting, i.e., training models with new samples inevitably leads to the forgetting of previously learned knowledge. Among existing methods, the replay-based methods achieve satisfactory performance but compromise privacy, while exemplar-free methods protect privacy but suffer from low accuracy. However, more critically, owing to their reliance on gradient-based update techniques, these existing methods fundamentally cannot solve the catastrophic forgetting problem. In TSC scenarios with continuously arriving data and temporally shifting distributions, these methods become even less practical. In this paper, we propose a Time Series Analytic Continual Learning framework, called TS-ACL. Inspired by analytical learning, TS-ACL transforms neural network updates into gradient-free linear regression problems, thereby fundamentally mitigating catastrophic forgetting. Specifically, employing a pre-trained and frozen feature extraction encoder, TS-ACL only needs to update its analytic classifier recursively in a lightweight manner that is highly suitable for real-time applications and large-scale data processing. Additionally, we theoretically demonstrate that the model obtained recursively through the TS-ACL is exactly equivalent to a model trained on the complete dataset in a centralized manner, thereby establishing the property of absolute knowledge memory. Extensive experiments validate the superior performance of our TS-ACL.
CAT: Concept-level backdoor ATtacks for Concept Bottleneck Models
Oct 07, 2024
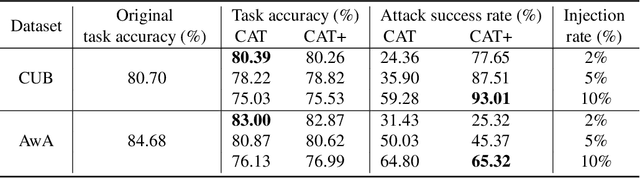


Despite the transformative impact of deep learning across multiple domains, the inherent opacity of these models has driven the development of Explainable Artificial Intelligence (XAI). Among these efforts, Concept Bottleneck Models (CBMs) have emerged as a key approach to improve interpretability by leveraging high-level semantic information. However, CBMs, like other machine learning models, are susceptible to security threats, particularly backdoor attacks, which can covertly manipulate model behaviors. Understanding that the community has not yet studied the concept level backdoor attack of CBM, because of "Better the devil you know than the devil you don't know.", we introduce CAT (Concept-level Backdoor ATtacks), a methodology that leverages the conceptual representations within CBMs to embed triggers during training, enabling controlled manipulation of model predictions at inference time. An enhanced attack pattern, CAT+, incorporates a correlation function to systematically select the most effective and stealthy concept triggers, thereby optimizing the attack's impact. Our comprehensive evaluation framework assesses both the attack success rate and stealthiness, demonstrating that CAT and CAT+ maintain high performance on clean data while achieving significant targeted effects on backdoored datasets. This work underscores the potential security risks associated with CBMs and provides a robust testing methodology for future security assessments.
Predicting Machine Translation Performance on Low-Resource Languages: The Role of Domain Similarity
Feb 04, 2024Fine-tuning and testing a multilingual large language model is expensive and challenging for low-resource languages (LRLs). While previous studies have predicted the performance of natural language processing (NLP) tasks using machine learning methods, they primarily focus on high-resource languages, overlooking LRLs and shifts across domains. Focusing on LRLs, we investigate three factors: the size of the fine-tuning corpus, the domain similarity between fine-tuning and testing corpora, and the language similarity between source and target languages. We employ classical regression models to assess how these factors impact the model's performance. Our results indicate that domain similarity has the most critical impact on predicting the performance of Machine Translation models.