 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaintaining Informative Coherence: Migrating Hallucinations in Large Language Models via Absorbing Markov Chains
Oct 27, 2024Large Language Models (LLMs) are powerful tools for text generation, translation, and summarization, but they often suffer from hallucinations-instances where they fail to maintain the fidelity and coherence of contextual information during decoding, sometimes overlooking critical details due to their sampling strategies and inherent biases from training data and fine-tuning discrepancies. These hallucinations can propagate through the web, affecting the trustworthiness of information disseminated online. To address this issue, we propose a novel decoding strategy that leverages absorbing Markov chains to quantify the significance of contextual information and measure the extent of information loss during generation. By considering all possible paths from the first to the last token, our approach enhances the reliability of model outputs without requiring additional training or external data. Evaluations on datasets including TruthfulQA, FACTOR, and HaluEval highlight the superior performance of our method in mitigating hallucinations, underscoring the necessity of ensuring accurate information flow in web-based applications.
CAT: Concept-level backdoor ATtacks for Concept Bottleneck Models
Oct 07, 2024
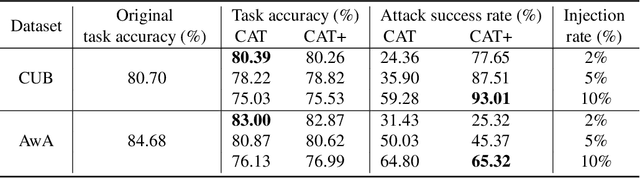


Despite the transformative impact of deep learning across multiple domains, the inherent opacity of these models has driven the development of Explainable Artificial Intelligence (XAI). Among these efforts, Concept Bottleneck Models (CBMs) have emerged as a key approach to improve interpretability by leveraging high-level semantic information. However, CBMs, like other machine learning models, are susceptible to security threats, particularly backdoor attacks, which can covertly manipulate model behaviors. Understanding that the community has not yet studied the concept level backdoor attack of CBM, because of "Better the devil you know than the devil you don't know.", we introduce CAT (Concept-level Backdoor ATtacks), a methodology that leverages the conceptual representations within CBMs to embed triggers during training, enabling controlled manipulation of model predictions at inference time. An enhanced attack pattern, CAT+, incorporates a correlation function to systematically select the most effective and stealthy concept triggers, thereby optimizing the attack's impact. Our comprehensive evaluation framework assesses both the attack success rate and stealthiness, demonstrating that CAT and CAT+ maintain high performance on clean data while achieving significant targeted effects on backdoored datasets. This work underscores the potential security risks associated with CBMs and provides a robust testing methodology for future security assessments.
DRIVE: Dependable Robust Interpretable Visionary Ensemble Framework in Autonomous Driving
Sep 16, 2024



Recent advancements in autonomous driving have seen a paradigm shift towards end-to-end learning paradigms, which map sensory inputs directly to driving actions, thereby enhancing the robustness and adaptability of autonomous vehicles. However, these models often sacrifice interpretability, posing significant challenges to trust, safety, and regulatory compliance. To address these issues, we introduce DRIVE -- Dependable Robust Interpretable Visionary Ensemble Framework in Autonomous Driving, a comprehensive framework designed to improve the dependability and stability of explanations in end-to-end unsupervised autonomous driving models. Our work specifically targets the inherent instability problems observed in the Driving through the Concept Gridlock (DCG) model, which undermine the trustworthiness of its explanations and decision-making processes. We define four key attributes of DRIVE: consistent interpretability, stable interpretability, consistent output, and stable output. These attributes collectively ensure that explanations remain reliable and robust across different scenarios and perturbations. Through extensive empirical evaluations, we demonstrate the effectiveness of our framework in enhancing the stability and dependability of explanations, thereby addressing the limitations of current models. Our contributions include an in-depth analysis of the dependability issues within the DCG model, a rigorous definition of DRIVE with its fundamental properties, a framework to implement DRIVE, and novel metrics for evaluating the dependability of concept-based explainable autonomous driving models. These advancements lay the groundwork for the development of more reliable and trusted autonomous driving systems, paving the way for their broader acceptance and deployment in real-world applications.
Referring Flexible Image Restoration
Apr 16, 2024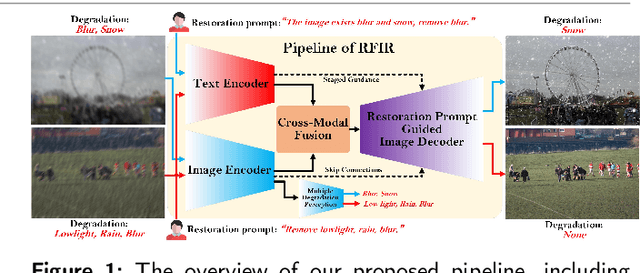


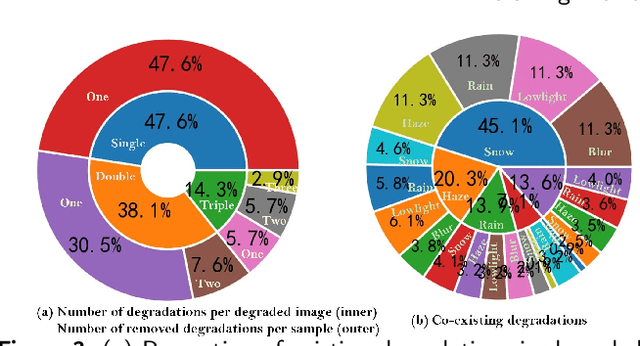
In reality, images often exhibit multiple degradations, such as rain and fog at night (triple degradations). However, in many cases, individuals may not want to remove all degradations, for instance, a blurry lens revealing a beautiful snowy landscape (double degradations). In such scenarios, people may only desire to deblur. These situations and requirements shed light on a new challenge in image restoration, where a model must perceive and remove specific degradation types specified by human commands in images with multiple degradations. We term this task Referring Flexible Image Restoration (RFIR). To address this, we first construct a large-scale synthetic dataset called RFIR, comprising 153,423 samples with the degraded image, text prompt for specific degradation removal and restored image. RFIR consists of five basic degradation types: blur, rain, haze, low light and snow while six main sub-categories are included for varying degrees of degradation removal. To tackle the challenge, we propose a novel transformer-based multi-task model named TransRFIR, which simultaneously perceives degradation types in the degraded image and removes specific degradation upon text prompt. TransRFIR is based on two devised attention modules, Multi-Head Agent Self-Attention (MHASA) and Multi-Head Agent Cross Attention (MHACA), where MHASA and MHACA introduce the agent token and reach the linear complexity, achieving lower computation cost than vanilla self-attention and cross-attention and obtaining competitive performances. Our TransRFIR achieves state-of-the-art performances compared with other counterparts and is proven as an effective architecture for image restoration. We release our project at https://github.com/GuanRunwei/FIR-CP.