 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSPlay: Cooperative Self-Play at Test-Time with Self-Generated Code and Unit Test
May 25, 2026Recently, Reinforcement Learning with Verifiable Rewards (RLVR) and Test-Time Scaling (TTS) have advanced LLM code generation through executable verification. Yet Ground-Truth Unit Tests (GT UTs) remain a bottleneck: SOTA RLVR methods require them for costly training, while existing TTS methods lose competitiveness without them. This motivates GT-free TTS, where existing methods directly use self-generated UTs to refine and select code candidates. Yet such UTs are often noisy or spuriously coupled with wrong code, and UT quality in turn cannot be validated without reliable code. The key challenge is therefore to jointly improve both. To this end, we present CoSPlay, a GT-free, training-free framework that jointly improves codes and UTs through cooperative self-play. It first explores diverse solution ideas and identifies their potential failure modes to produce discriminative UT ideas. It then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune or fix weak codes and refresh or replace unreliable UTs, letting the two pools co-evolve. Finally, when multiple codes remain tied at the highest pass count, it picks the final code from the largest output-consensus cluster, since correct codes agree on the same inputs while wrong codes diverge. Experiments on four challenging benchmarks show that CoSPlay on Qwen2.5-7B-Instruct improves average BoN from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3%, matching or surpassing the RLVR model CURE-7B. When applied to CURE-7B, it further improves BoN by 5.7%. CoSPlay also generalizes across diverse backbones and outperforms GT-free TTS baselines under comparable token budgets, with continued gains as the budget scales up. These results suggest a scalable inference strategy for competitive code generation without any GT data.
IMTS is Worth Time $\times$ Channel Patches: Visual Masked Autoencoders for Irregular Multivariate Time Series Prediction
May 28, 2025Irregular Multivariate Time Series (IMTS) forecasting is challenging due to the unaligned nature of multi-channel signals and the prevalence of extensive missing data. Existing methods struggle to capture reliable temporal patterns from such data due to significant missing values. While pre-trained foundation models show potential for addressing these challenges, they are typically designed for Regularly Sampled Time Series (RTS). Motivated by the visual Mask AutoEncoder's (MAE) powerful capability for modeling sparse multi-channel information and its success in RTS forecasting, we propose VIMTS, a framework adapting Visual MAE for IMTS forecasting. To mitigate the effect of missing values, VIMTS first processes IMTS along the timeline into feature patches at equal intervals. These patches are then complemented using learned cross-channel dependencies. Then it leverages visual MAE's capability in handling sparse multichannel data for patch reconstruction, followed by a coarse-to-fine technique to generate precise predictions from focused contexts. In addition, we integrate self-supervised learning for improved IMTS modeling by adapting the visual MAE to IMTS data. Extensive experiments demonstrate VIMTS's superior performance and few-shot capability, advancing the application of visual foundation models in more general time series tasks. Our code is available at https://github.com/WHU-HZY/VIMTS.
Towards Reliable Time Series Forecasting under Future Uncertainty: Ambiguity and Novelty Rejection Mechanisms
Mar 25, 2025In real-world time series forecasting, uncertainty and lack of reliable evaluation pose significant challenges. Notably, forecasting errors often arise from underfitting in-distribution data and failing to handle out-of-distribution inputs. To enhance model reliability, we introduce a dual rejection mechanism combining ambiguity and novelty rejection. Ambiguity rejection, using prediction error variance, allows the model to abstain under low confidence, assessed through historical error variance analysis without future ground truth. Novelty rejection, employing Variational Autoencoders and Mahalanobis distance, detects deviations from training data. This dual approach improves forecasting reliability in dynamic environments by reducing errors and adapting to data changes, advancing reliability in complex scenarios.
Learning New Concepts, Remembering the Old: A Novel Continual Learning
Nov 25, 2024



Concept Bottleneck Models (CBMs) enhance model interpretability by introducing human-understandable concepts within the architecture. However, existing CBMs assume static datasets, limiting their ability to adapt to real-world, continuously evolving data streams. To address this, we define a novel concept-incremental and class-incremental continual learning task for CBMs, enabling models to accumulate new concepts and classes over time while retaining previously learned knowledge. To achieve this, we propose CONceptual Continual Incremental Learning (CONCIL), a framework that prevents catastrophic forgetting by reformulating concept and decision layer updates as linear regression problems, thus eliminating the need for gradient-based updates. CONCIL requires only recursive matrix operations, making it computationally efficient and suitable for real-time and large-scale data applications. Experimental results demonstrate that CONCIL achieves "absolute knowledge memory" and outperforms traditional CBM methods in concept- and class-incremental settings, establishing a new benchmark for continual learning in CBMs.
CAT: Concept-level backdoor ATtacks for Concept Bottleneck Models
Oct 07, 2024
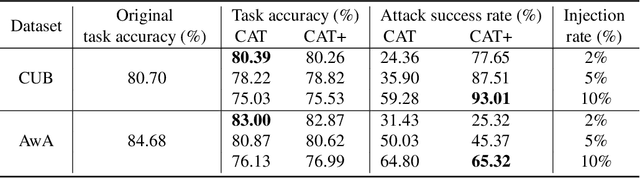


Despite the transformative impact of deep learning across multiple domains, the inherent opacity of these models has driven the development of Explainable Artificial Intelligence (XAI). Among these efforts, Concept Bottleneck Models (CBMs) have emerged as a key approach to improve interpretability by leveraging high-level semantic information. However, CBMs, like other machine learning models, are susceptible to security threats, particularly backdoor attacks, which can covertly manipulate model behaviors. Understanding that the community has not yet studied the concept level backdoor attack of CBM, because of "Better the devil you know than the devil you don't know.", we introduce CAT (Concept-level Backdoor ATtacks), a methodology that leverages the conceptual representations within CBMs to embed triggers during training, enabling controlled manipulation of model predictions at inference time. An enhanced attack pattern, CAT+, incorporates a correlation function to systematically select the most effective and stealthy concept triggers, thereby optimizing the attack's impact. Our comprehensive evaluation framework assesses both the attack success rate and stealthiness, demonstrating that CAT and CAT+ maintain high performance on clean data while achieving significant targeted effects on backdoored datasets. This work underscores the potential security risks associated with CBMs and provides a robust testing methodology for future security assessments.
A Distributionally Robust Boosting Algorithm
May 20, 2019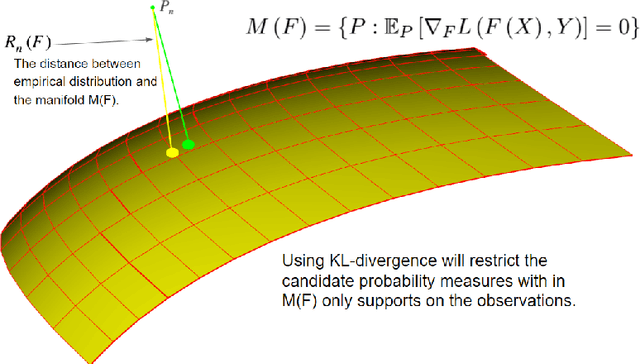
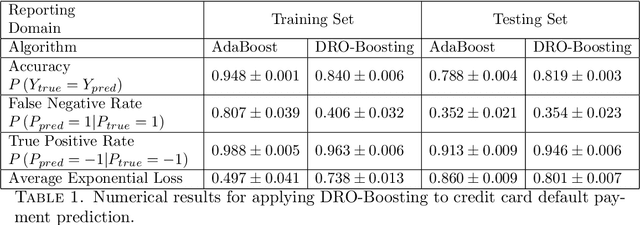
Distributionally Robust Optimization (DRO) has been shown to provide a flexible framework for decision making under uncertainty and statistical estimation. For example, recent works in DRO have shown that popular statistical estimators can be interpreted as the solutions of suitable formulated data-driven DRO problems. In turn, this connection is used to optimally select tuning parameters in terms of a principled approach informed by robustness considerations. This paper contributes to this growing literature, connecting DRO and statistics, by showing how boosting algorithms can be studied via DRO. We propose a boosting type algorithm, named DRO-Boosting, as a procedure to solve our DRO formulation. Our DRO-Boosting algorithm recovers Adaptive Boosting (AdaBoost) in particular, thus showing that AdaBoost is effectively solving a DRO problem. We apply our algorithm to a financial dataset on credit card default payment prediction. We find that our approach compares favorably to alternative boosting methods which are widely used in practice.
Doubly Robust Data-Driven Distributionally Robust Optimization
May 19, 2017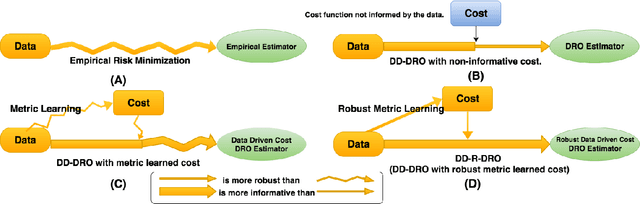
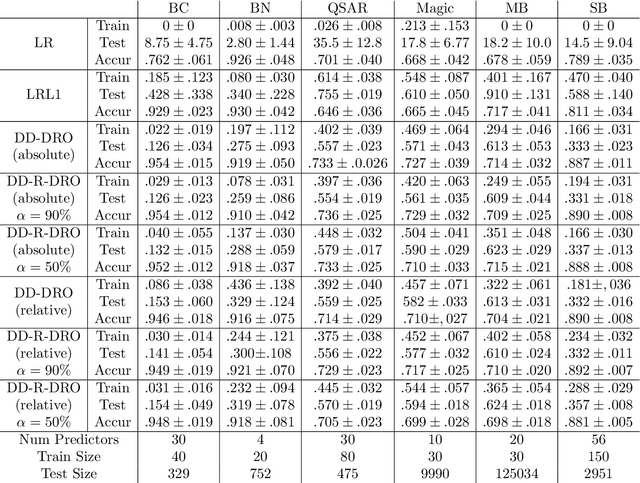
Data-driven Distributionally Robust Optimization (DD-DRO) via optimal transport has been shown to encompass a wide range of popular machine learning algorithms. The distributional uncertainty size is often shown to correspond to the regularization parameter. The type of regularization (e.g. the norm used to regularize) corresponds to the shape of the distributional uncertainty. We propose a data-driven robust optimization methodology to inform the transportation cost underlying the definition of the distributional uncertainty. We show empirically that this additional layer of robustification, which produces a method we called doubly robust data-driven distributionally robust optimization (DD-R-DRO), allows to enhance the generalization properties of regularized estimators while reducing testing error relative to state-of-the-art classifiers in a wide range of data sets.