 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning's Dropout Training is Distributionally Robust Optimal
Sep 13, 2020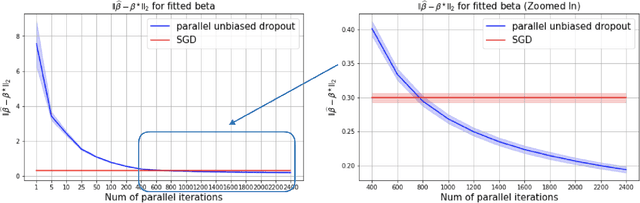

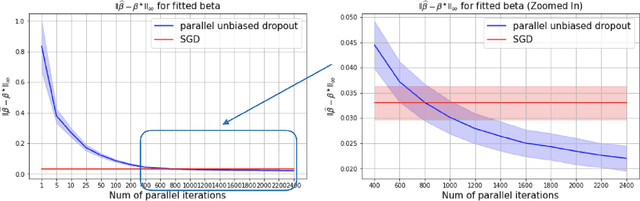

This paper shows that dropout training in Generalized Linear Models is the minimax solution of a two-player, zero-sum game where an adversarial nature corrupts a statistician's covariates using a multiplicative nonparametric errors-in-variables model. In this game---known as a Distributionally Robust Optimization problem---nature's least favorable distribution is dropout noise, where nature independently deletes entries of the covariate vector with some fixed probability $\delta$. Our decision-theoretic analysis shows that dropout training---the statistician's minimax strategy in the game---indeed provides out-of-sample expected loss guarantees for distributions that arise from multiplicative perturbations of in-sample data. This paper also provides a novel, parallelizable, Unbiased Multi-Level Monte Carlo algorithm to speed-up the implementation of dropout training. Our algorithm has a much smaller computational cost compared to the naive implementation of dropout, provided the number of data points is much smaller than the dimension of the covariate vector.
A Distributionally Robust Boosting Algorithm
May 20, 2019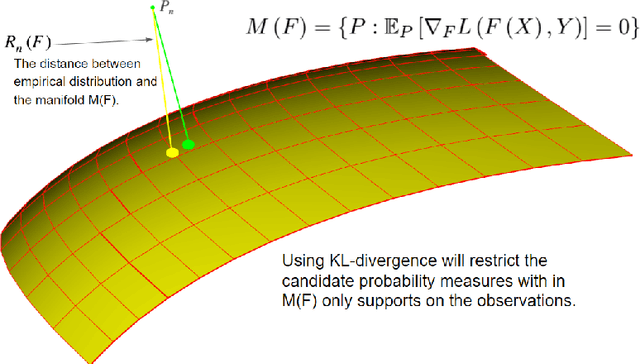
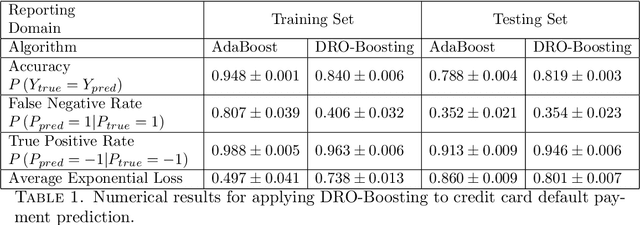
Distributionally Robust Optimization (DRO) has been shown to provide a flexible framework for decision making under uncertainty and statistical estimation. For example, recent works in DRO have shown that popular statistical estimators can be interpreted as the solutions of suitable formulated data-driven DRO problems. In turn, this connection is used to optimally select tuning parameters in terms of a principled approach informed by robustness considerations. This paper contributes to this growing literature, connecting DRO and statistics, by showing how boosting algorithms can be studied via DRO. We propose a boosting type algorithm, named DRO-Boosting, as a procedure to solve our DRO formulation. Our DRO-Boosting algorithm recovers Adaptive Boosting (AdaBoost) in particular, thus showing that AdaBoost is effectively solving a DRO problem. We apply our algorithm to a financial dataset on credit card default payment prediction. We find that our approach compares favorably to alternative boosting methods which are widely used in practice.
Latent Semantic Analysis Approach for Document Summarization Based on Word Embeddings
Oct 28, 2018
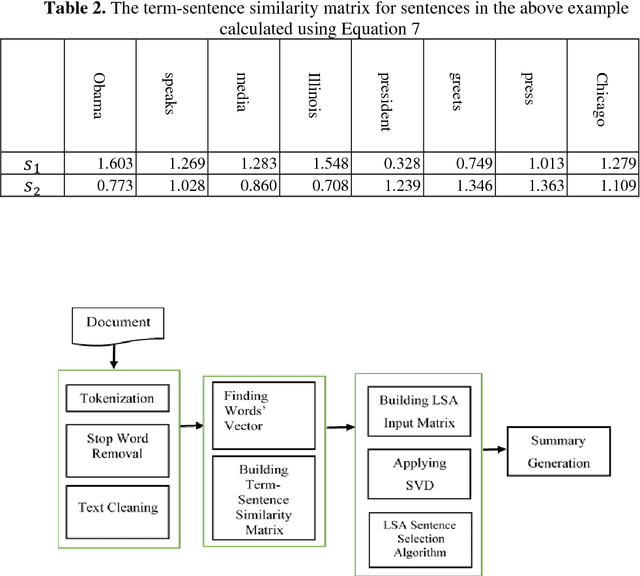
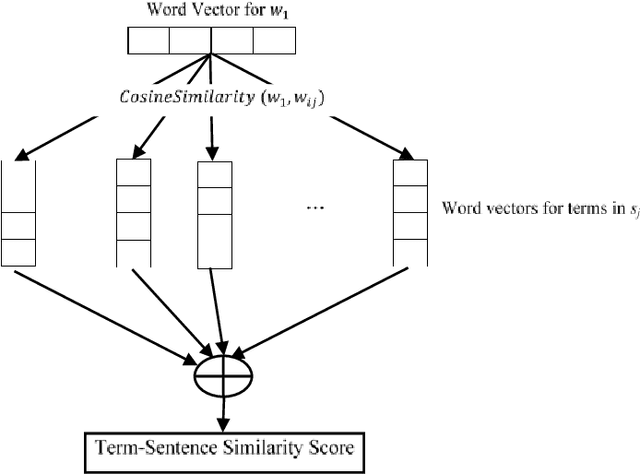
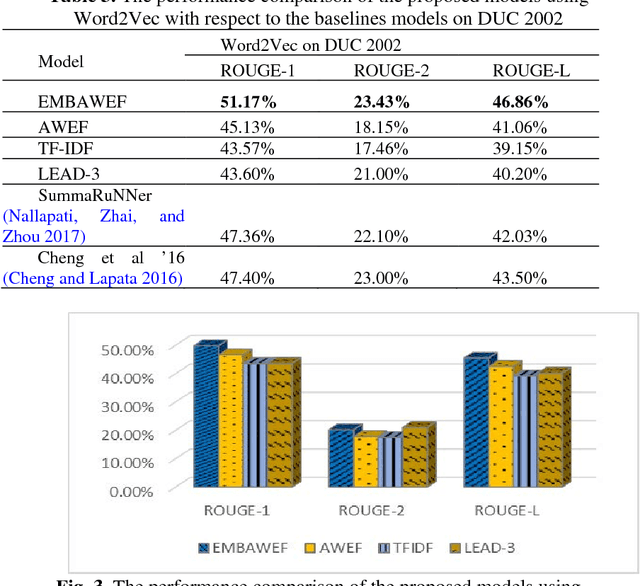
Since the amount of information on the internet is growing rapidly, it is not easy for a user to find relevant information for his/her query. To tackle this issue, much attention has been paid to Automatic Document Summarization. The key point in any successful document summarizer is a good document representation. The traditional approaches based on word overlapping mostly fail to produce that kind of representation. Word embedding, distributed representation of words, has shown an excellent performance that allows words to match on semantic level. Naively concatenating word embeddings makes the common word dominant which in turn diminish the representation quality. In this paper, we employ word embeddings to improve the weighting schemes for calculating the input matrix of Latent Semantic Analysis method. Two embedding-based weighting schemes are proposed and then combined to calculate the values of this matrix. The new weighting schemes are modified versions of the augment weight and the entropy frequency. The new schemes combine the strength of the traditional weighting schemes and word embedding. The proposed approach is experimentally evaluated on three well-known English datasets, DUC 2002, DUC 2004 and Multilingual 2015 Single-document Summarization for English. The proposed model performs comprehensively better compared to the state-of-the-art methods, by at least 1% ROUGE points, leading to a conclusion that it provides a better document representation and a better document summary as a result.
* 20 pages, One-column, 4 figures
Bidirectional Attentional Encoder-Decoder Model and Bidirectional Beam Search for Abstractive Summarization
Sep 18, 2018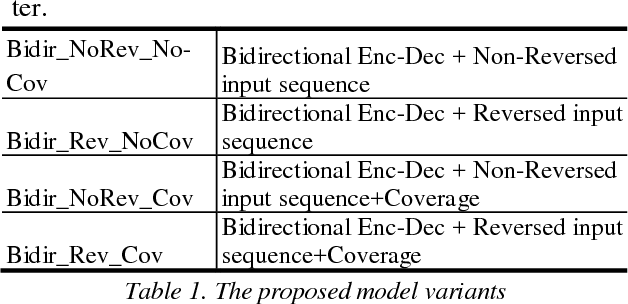
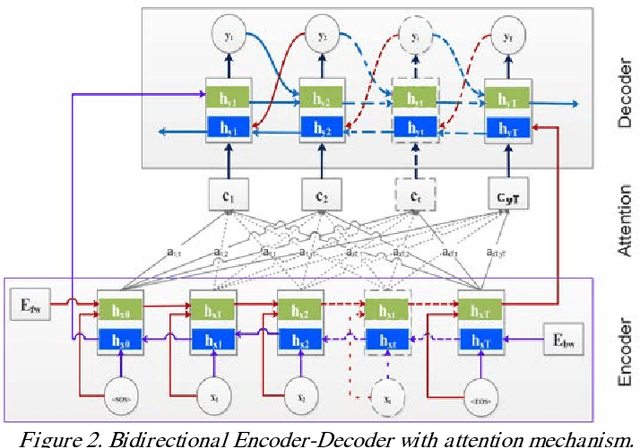
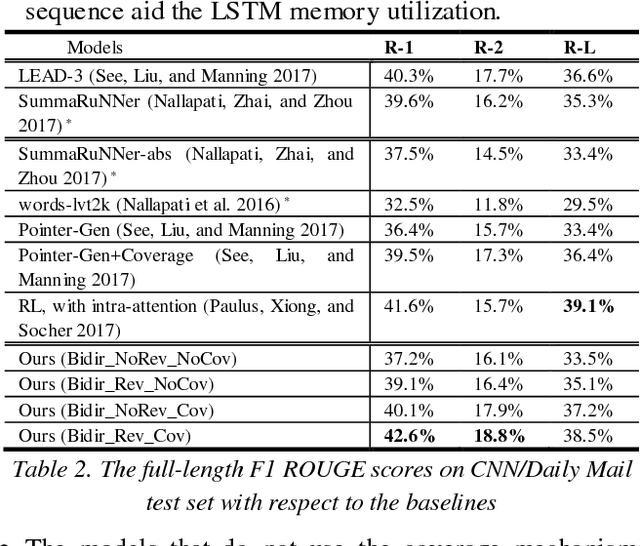
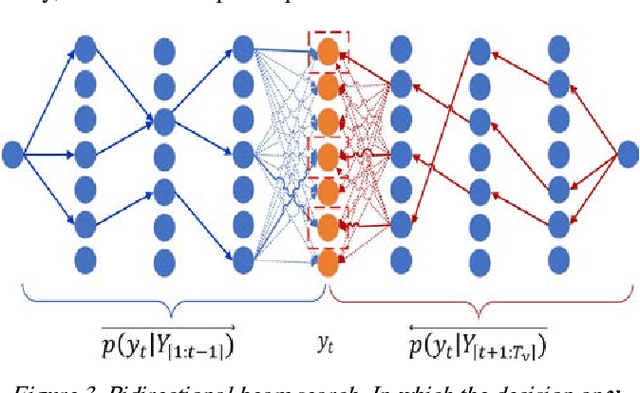
Sequence generative models with RNN variants, such as LSTM, GRU, show promising performance on abstractive document summarization. However, they still have some issues that limit their performance, especially while deal-ing with long sequences. One of the issues is that, to the best of our knowledge, all current models employ a unidirectional decoder, which reasons only about the past and still limited to retain future context while giving a prediction. This makes these models suffer on their own by generating unbalanced outputs. Moreover, unidirec-tional attention-based document summarization can only capture partial aspects of attentional regularities due to the inherited challenges in document summarization. To this end, we propose an end-to-end trainable bidirectional RNN model to tackle the aforementioned issues. The model has a bidirectional encoder-decoder architecture; in which the encoder and the decoder are bidirectional LSTMs. The forward decoder is initialized with the last hidden state of the backward encoder while the backward decoder is initialized with the last hidden state of the for-ward encoder. In addition, a bidirectional beam search mechanism is proposed as an approximate inference algo-rithm for generating the output summaries from the bidi-rectional model. This enables the model to reason about the past and future and to generate balanced outputs as a result. Experimental results on CNN / Daily Mail dataset show that the proposed model outperforms the current abstractive state-of-the-art models by a considerable mar-gin.
Semi-supervised Learning based on Distributionally Robust Optimization
Aug 04, 2017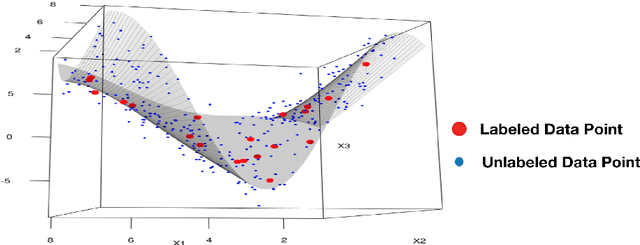
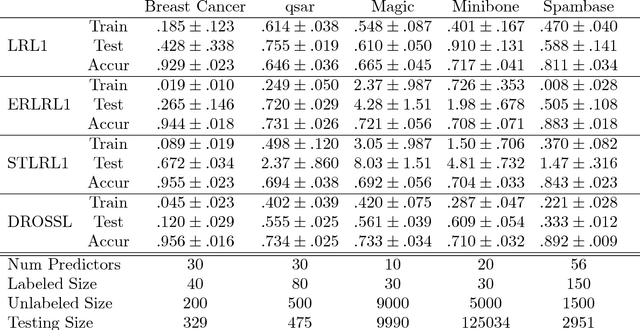
We propose a novel method for semi-supervised learning (SSL) based on data-driven distributionally robust optimization (DRO) using optimal transport metrics. Our proposed method enhances generalization error by using the unlabeled data to restrict the support of the worst case distribution in our DRO formulation. We enable the implementation of our DRO formulation by proposing a stochastic gradient descent algorithm which allows to easily implement the training procedure. We demonstrate that our Semi-supervised DRO method is able to improve the generalization error over natural supervised procedures and state-of-the-art SSL estimators. Finally, we include a discussion on the large sample behavior of the optimal uncertainty region in the DRO formulation. Our discussion exposes important aspects such as the role of dimension reduction in SSL.
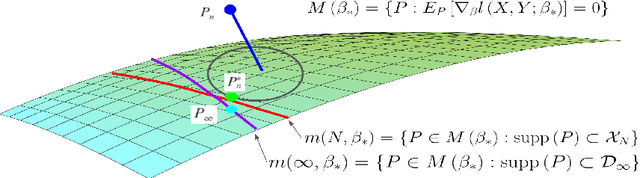
Doubly Robust Data-Driven Distributionally Robust Optimization
May 19, 2017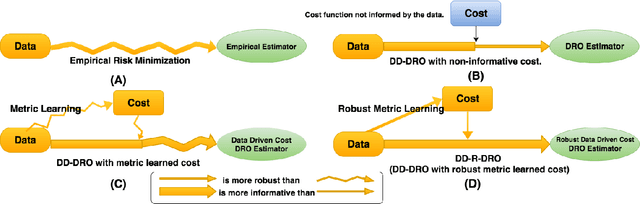
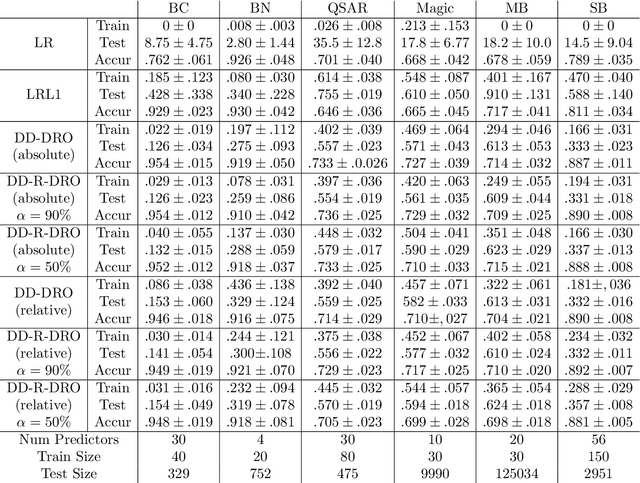
Data-driven Distributionally Robust Optimization (DD-DRO) via optimal transport has been shown to encompass a wide range of popular machine learning algorithms. The distributional uncertainty size is often shown to correspond to the regularization parameter. The type of regularization (e.g. the norm used to regularize) corresponds to the shape of the distributional uncertainty. We propose a data-driven robust optimization methodology to inform the transportation cost underlying the definition of the distributional uncertainty. We show empirically that this additional layer of robustification, which produces a method we called doubly robust data-driven distributionally robust optimization (DD-R-DRO), allows to enhance the generalization properties of regularized estimators while reducing testing error relative to state-of-the-art classifiers in a wide range of data sets.
Data-driven Optimal Transport Cost Selection for Distributionally Robust Optimizatio
May 19, 2017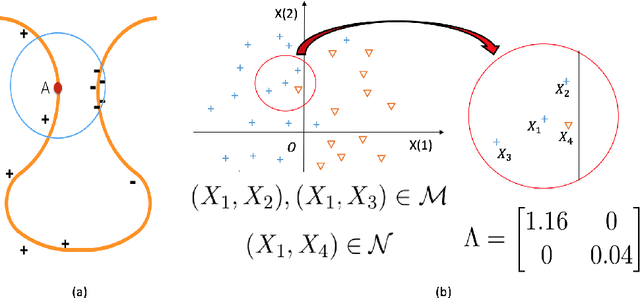
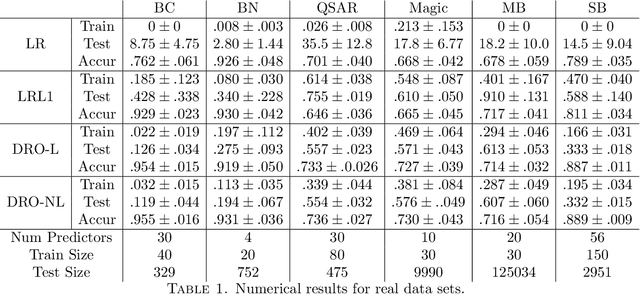
Recently, (Blanchet, Kang, and Murhy 2016) showed that several machine learning algorithms, such as square-root Lasso, Support Vector Machines, and regularized logistic regression, among many others, can be represented exactly as distributionally robust optimization (DRO) problems. The distributional uncertainty is defined as a neighborhood centered at the empirical distribution. We propose a methodology which learns such neighborhood in a natural data-driven way. We show rigorously that our framework encompasses adaptive regularization as a particular case. Moreover, we demonstrate empirically that our proposed methodology is able to improve upon a wide range of popular machine learning estimators.