 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Semantic Analysis Approach for Document Summarization Based on Word Embeddings
Paper and Code
Oct 28, 2018
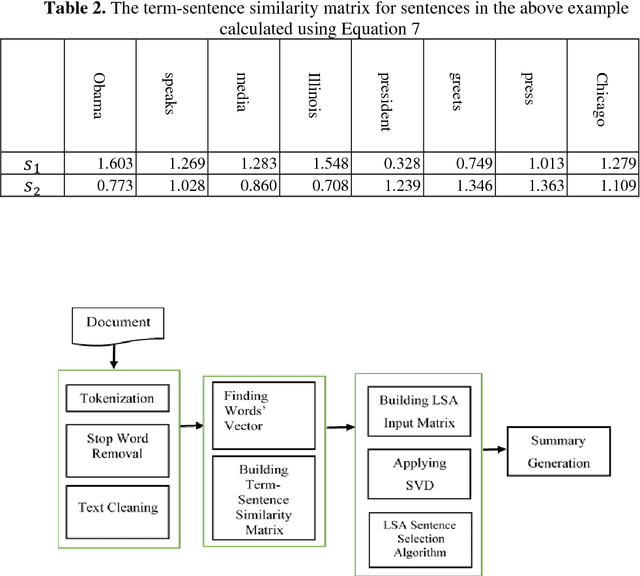
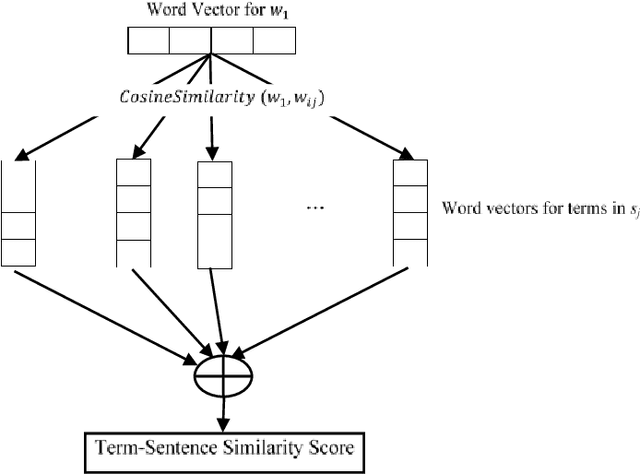
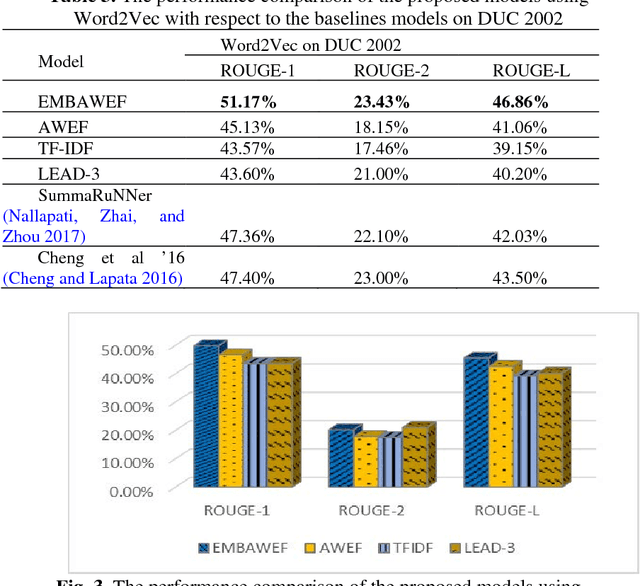
Since the amount of information on the internet is growing rapidly, it is not easy for a user to find relevant information for his/her query. To tackle this issue, much attention has been paid to Automatic Document Summarization. The key point in any successful document summarizer is a good document representation. The traditional approaches based on word overlapping mostly fail to produce that kind of representation. Word embedding, distributed representation of words, has shown an excellent performance that allows words to match on semantic level. Naively concatenating word embeddings makes the common word dominant which in turn diminish the representation quality. In this paper, we employ word embeddings to improve the weighting schemes for calculating the input matrix of Latent Semantic Analysis method. Two embedding-based weighting schemes are proposed and then combined to calculate the values of this matrix. The new weighting schemes are modified versions of the augment weight and the entropy frequency. The new schemes combine the strength of the traditional weighting schemes and word embedding. The proposed approach is experimentally evaluated on three well-known English datasets, DUC 2002, DUC 2004 and Multilingual 2015 Single-document Summarization for English. The proposed model performs comprehensively better compared to the state-of-the-art methods, by at least 1% ROUGE points, leading to a conclusion that it provides a better document representation and a better document summary as a result.