 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Semantic Analysis Approach for Document Summarization Based on Word Embeddings
Oct 28, 2018
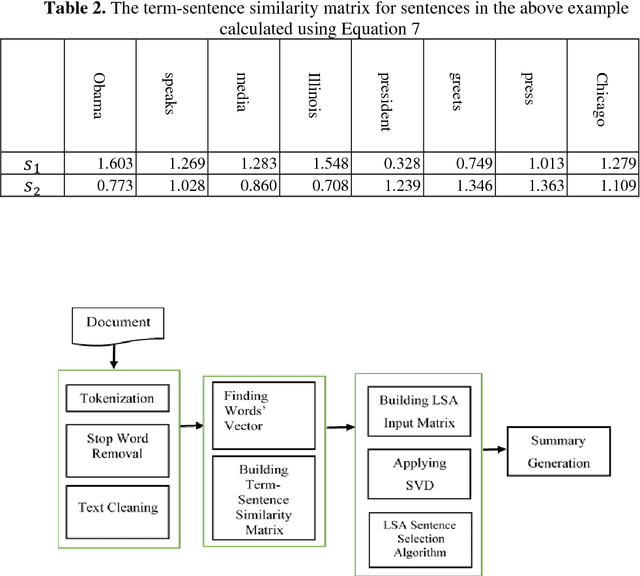
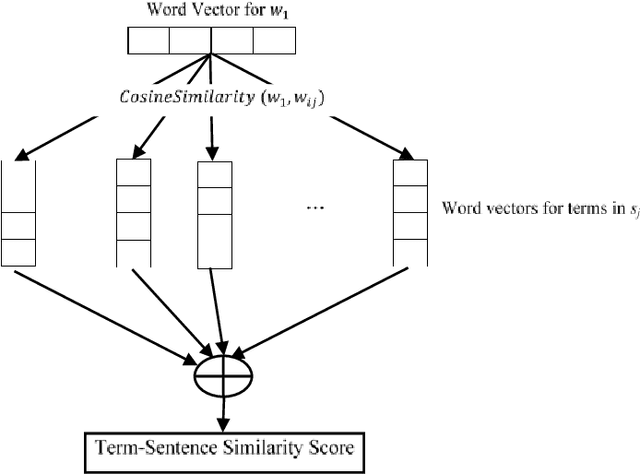
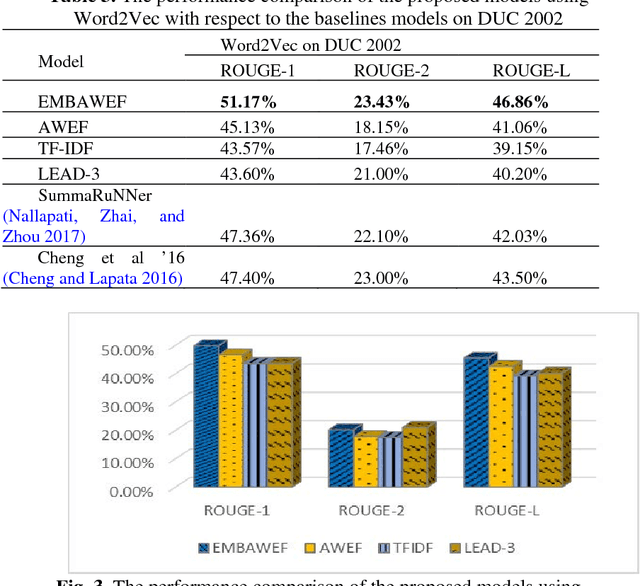
Since the amount of information on the internet is growing rapidly, it is not easy for a user to find relevant information for his/her query. To tackle this issue, much attention has been paid to Automatic Document Summarization. The key point in any successful document summarizer is a good document representation. The traditional approaches based on word overlapping mostly fail to produce that kind of representation. Word embedding, distributed representation of words, has shown an excellent performance that allows words to match on semantic level. Naively concatenating word embeddings makes the common word dominant which in turn diminish the representation quality. In this paper, we employ word embeddings to improve the weighting schemes for calculating the input matrix of Latent Semantic Analysis method. Two embedding-based weighting schemes are proposed and then combined to calculate the values of this matrix. The new weighting schemes are modified versions of the augment weight and the entropy frequency. The new schemes combine the strength of the traditional weighting schemes and word embedding. The proposed approach is experimentally evaluated on three well-known English datasets, DUC 2002, DUC 2004 and Multilingual 2015 Single-document Summarization for English. The proposed model performs comprehensively better compared to the state-of-the-art methods, by at least 1% ROUGE points, leading to a conclusion that it provides a better document representation and a better document summary as a result.
* 20 pages, One-column, 4 figures
Bidirectional Attentional Encoder-Decoder Model and Bidirectional Beam Search for Abstractive Summarization
Sep 18, 2018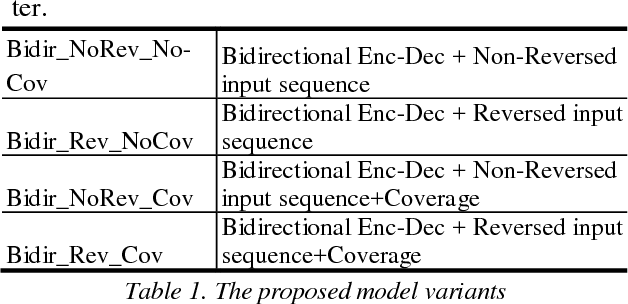
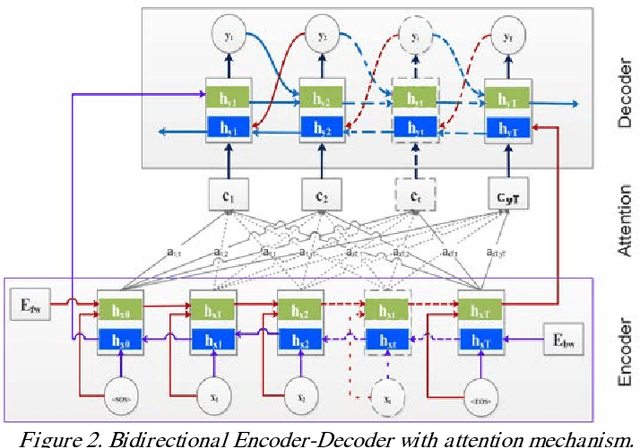
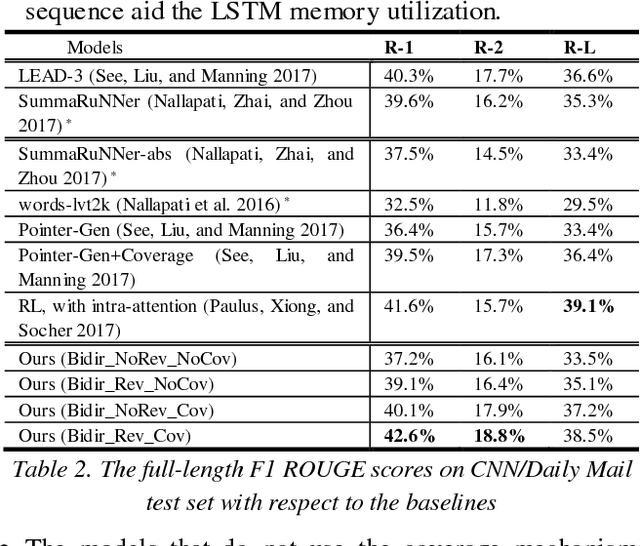
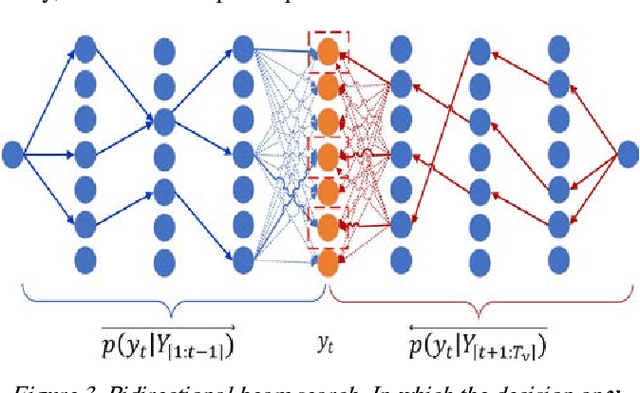
Sequence generative models with RNN variants, such as LSTM, GRU, show promising performance on abstractive document summarization. However, they still have some issues that limit their performance, especially while deal-ing with long sequences. One of the issues is that, to the best of our knowledge, all current models employ a unidirectional decoder, which reasons only about the past and still limited to retain future context while giving a prediction. This makes these models suffer on their own by generating unbalanced outputs. Moreover, unidirec-tional attention-based document summarization can only capture partial aspects of attentional regularities due to the inherited challenges in document summarization. To this end, we propose an end-to-end trainable bidirectional RNN model to tackle the aforementioned issues. The model has a bidirectional encoder-decoder architecture; in which the encoder and the decoder are bidirectional LSTMs. The forward decoder is initialized with the last hidden state of the backward encoder while the backward decoder is initialized with the last hidden state of the for-ward encoder. In addition, a bidirectional beam search mechanism is proposed as an approximate inference algo-rithm for generating the output summaries from the bidi-rectional model. This enables the model to reason about the past and future and to generate balanced outputs as a result. Experimental results on CNN / Daily Mail dataset show that the proposed model outperforms the current abstractive state-of-the-art models by a considerable mar-gin.
A Hierarchical Structured Self-Attentive Model for Extractive Document Summarization (HSSAS)
May 20, 2018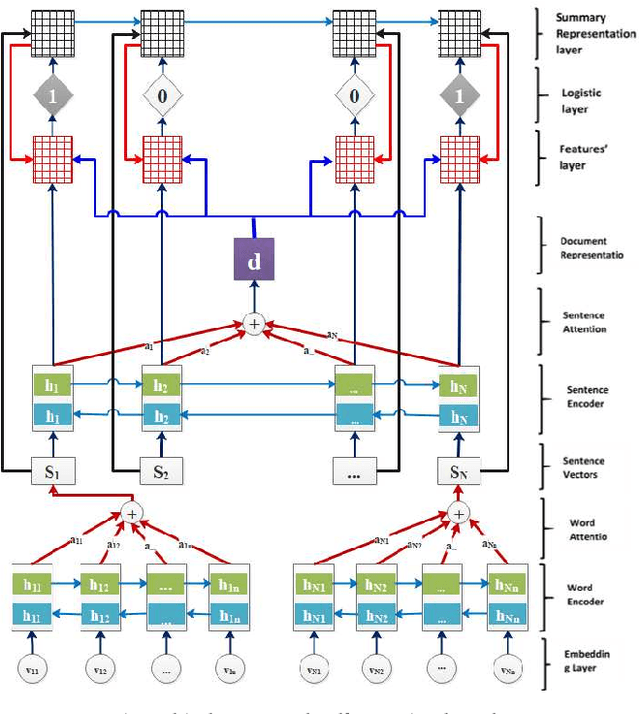
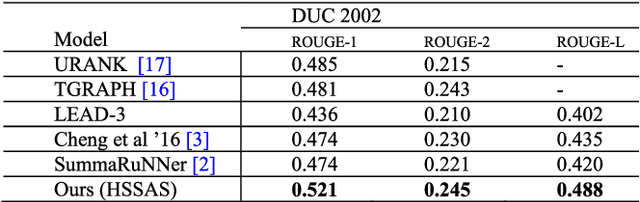
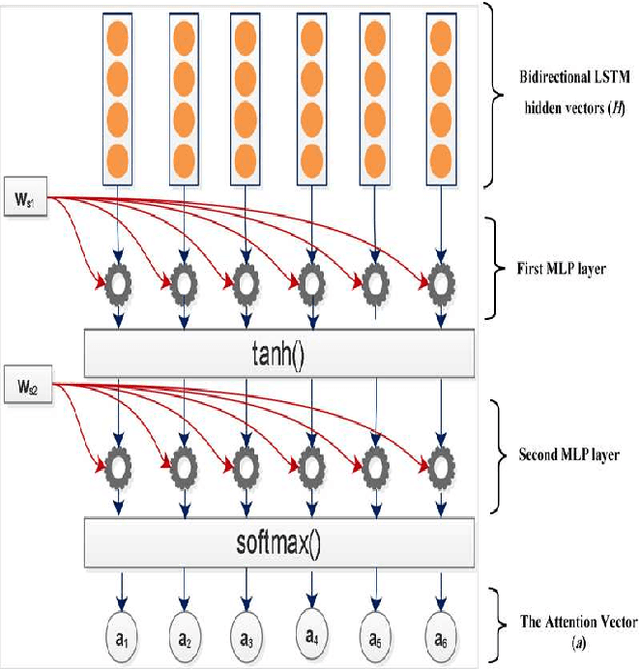
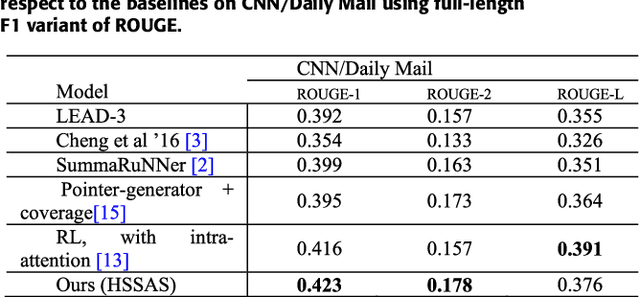
The recent advance in neural network architecture and training algorithms have shown the effectiveness of representation learning. The neural network-based models generate better representation than the traditional ones. They have the ability to automatically learn the distributed representation for sentences and documents. To this end, we proposed a novel model that addresses several issues that are not adequately modeled by the previously proposed models, such as the memory problem and incorporating the knowledge of document structure. Our model uses a hierarchical structured self-attention mechanism to create the sentence and document embeddings. This architecture mirrors the hierarchical structure of the document and in turn enables us to obtain better feature representation. The attention mechanism provides extra source of information to guide the summary extraction. The new model treated the summarization task as a classification problem in which the model computes the respective probabilities of sentence-summary membership. The model predictions are broken up by several features such as information content, salience, novelty and positional representation. The proposed model was evaluated on two well-known datasets, the CNN / Daily Mail, and DUC 2002. The experimental results show that our model outperforms the current extractive state-of-the-art by a considerable margin.