 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Qualified Benchmark Builders: Rebuilding Pre-Training Datasets for Advancing Code Intelligence Tasks
Apr 28, 2025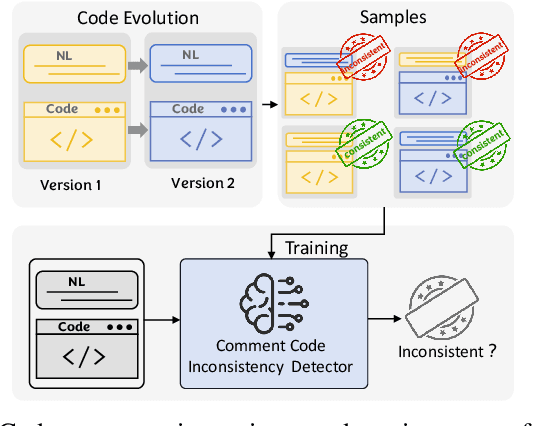
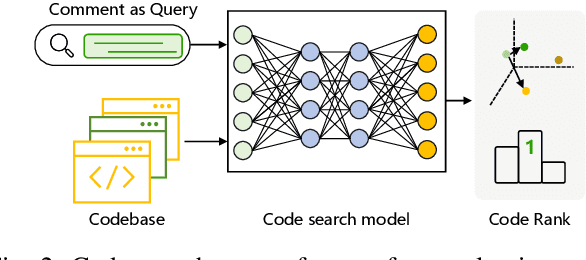

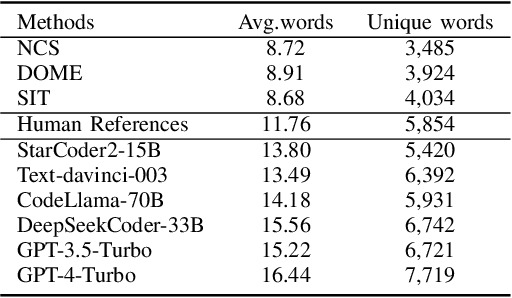
Pre-trained code models rely heavily on high-quality pre-training data, particularly human-written reference comments that bridge code and natural language. However, these comments often become outdated as software evolves, degrading model performance. Large language models (LLMs) excel at generating high-quality code comments. We investigate whether replacing human-written comments with LLM-generated ones improves pre-training datasets. Since standard metrics cannot assess reference comment quality, we propose two novel reference-free evaluation tasks: code-comment inconsistency detection and semantic code search. Results show that LLM-generated comments are more semantically consistent with code than human-written ones, as confirmed by manual evaluation. Leveraging this finding, we rebuild the CodeSearchNet dataset with LLM-generated comments and re-pre-train CodeT5. Evaluations demonstrate that models trained on LLM-enhanced data outperform those using original human comments in code summarization, generation, and translation tasks. This work validates rebuilding pre-training datasets with LLMs to advance code intelligence, challenging the traditional reliance on human reference comments.
Multi-head Sequence Tagging Model for Grammatical Error Correction
Oct 21, 2024
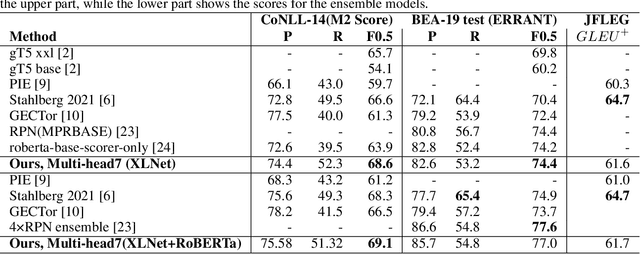
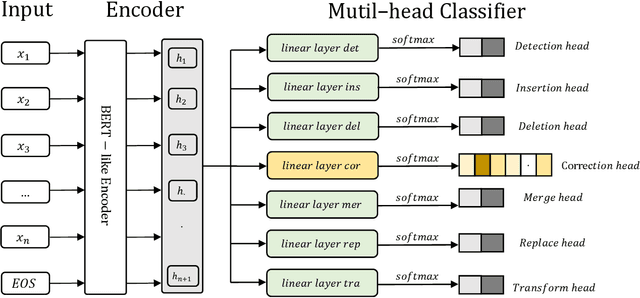

To solve the Grammatical Error Correction (GEC) problem , a mapping between a source sequence and a target one is needed, where the two differ only on few spans. For this reason, the attention has been shifted to the non-autoregressive or sequence tagging models. In which, the GEC has been simplified from Seq2Seq to labeling the input tokens with edit commands chosen from a large edit space. Due to this large number of classes and the limitation of the available datasets, the current sequence tagging approaches still have some issues handling a broad range of grammatical errors just by being laser-focused on one single task. To this end, we simplified the GEC further by dividing it into seven related subtasks: Insertion, Deletion, Merge, Substitution, Transformation, Detection, and Correction, with Correction being our primary focus. A distinct classification head is dedicated to each of these subtasks. the novel multi-head and multi-task learning model is proposed to effectively utilize training data and harness the information from related task training signals. To mitigate the limited number of available training samples, a new denoising autoencoder is used to generate a new synthetic dataset to be used for pretraining. Additionally, a new character-level transformation is proposed to enhance the sequence-to-edit function and improve the model's vocabulary coverage. Our single/ensemble model achieves an F0.5 of 74.4/77.0, and 68.6/69.1 on BEA-19 (test) and CoNLL-14 (test) respectively. Moreover, evaluated on JFLEG test set, the GLEU scores are 61.6 and 61.7 for the single and ensemble models, respectively. It mostly outperforms recently published state-of-the-art results by a considerable margin.
Latent Semantic Analysis Approach for Document Summarization Based on Word Embeddings
Oct 28, 2018
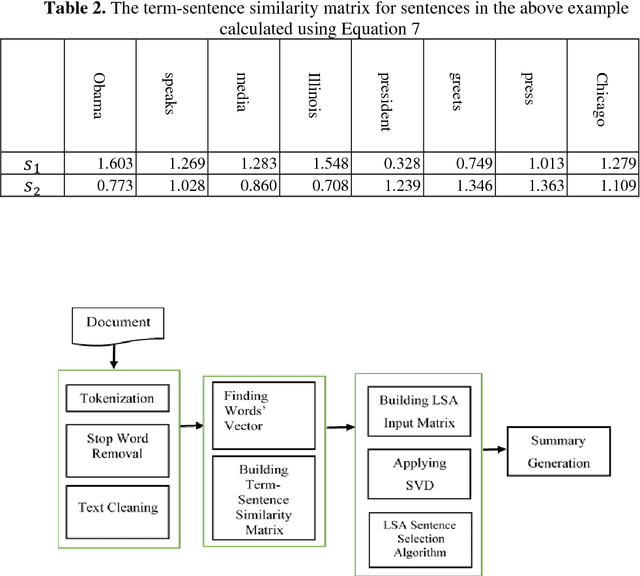
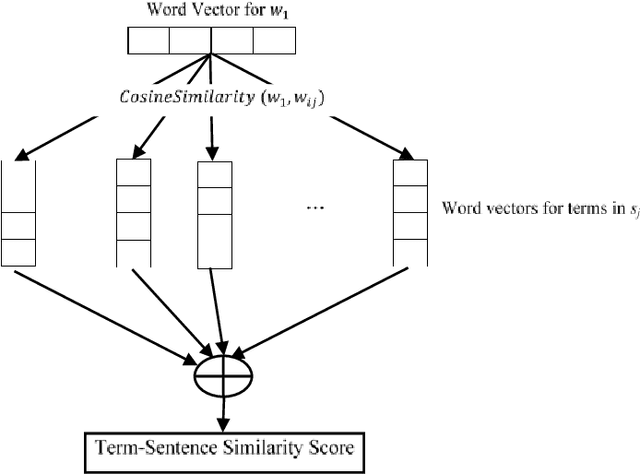
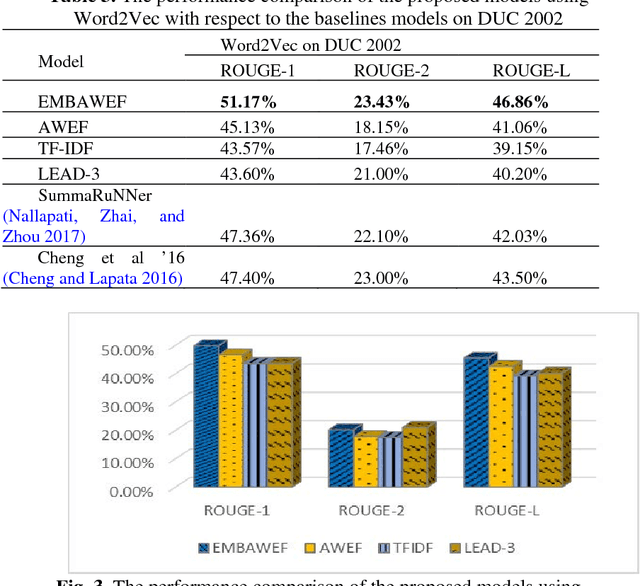
Since the amount of information on the internet is growing rapidly, it is not easy for a user to find relevant information for his/her query. To tackle this issue, much attention has been paid to Automatic Document Summarization. The key point in any successful document summarizer is a good document representation. The traditional approaches based on word overlapping mostly fail to produce that kind of representation. Word embedding, distributed representation of words, has shown an excellent performance that allows words to match on semantic level. Naively concatenating word embeddings makes the common word dominant which in turn diminish the representation quality. In this paper, we employ word embeddings to improve the weighting schemes for calculating the input matrix of Latent Semantic Analysis method. Two embedding-based weighting schemes are proposed and then combined to calculate the values of this matrix. The new weighting schemes are modified versions of the augment weight and the entropy frequency. The new schemes combine the strength of the traditional weighting schemes and word embedding. The proposed approach is experimentally evaluated on three well-known English datasets, DUC 2002, DUC 2004 and Multilingual 2015 Single-document Summarization for English. The proposed model performs comprehensively better compared to the state-of-the-art methods, by at least 1% ROUGE points, leading to a conclusion that it provides a better document representation and a better document summary as a result.
* 20 pages, One-column, 4 figures
Bidirectional Attentional Encoder-Decoder Model and Bidirectional Beam Search for Abstractive Summarization
Sep 18, 2018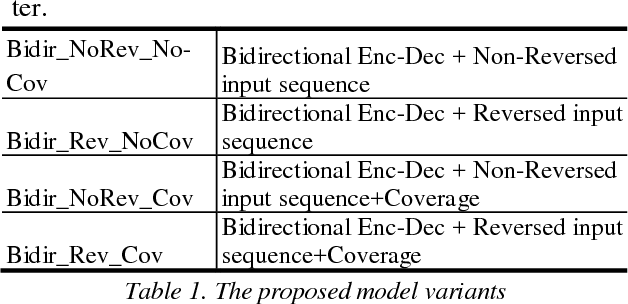
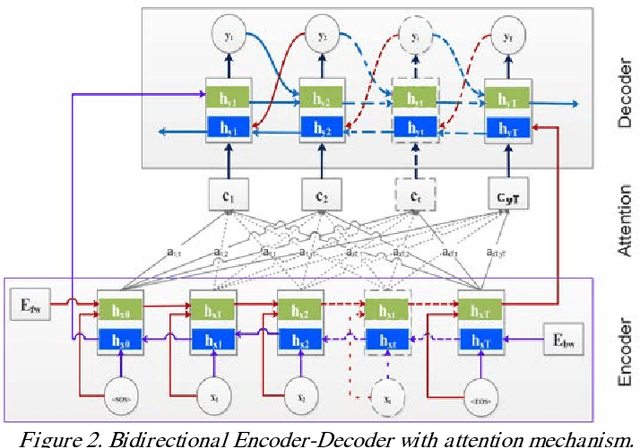
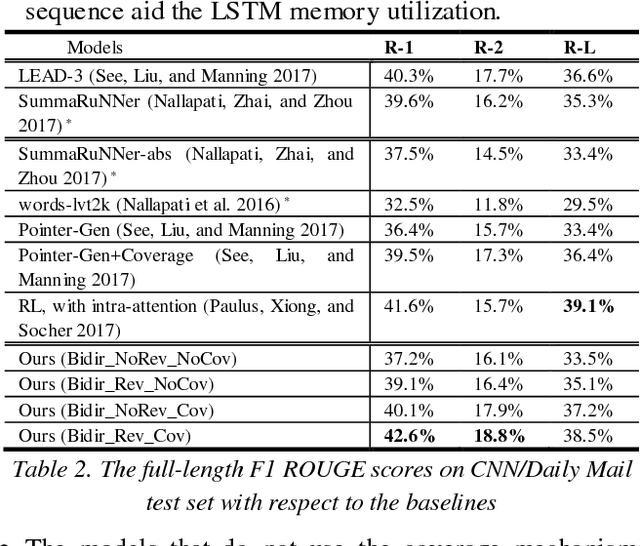
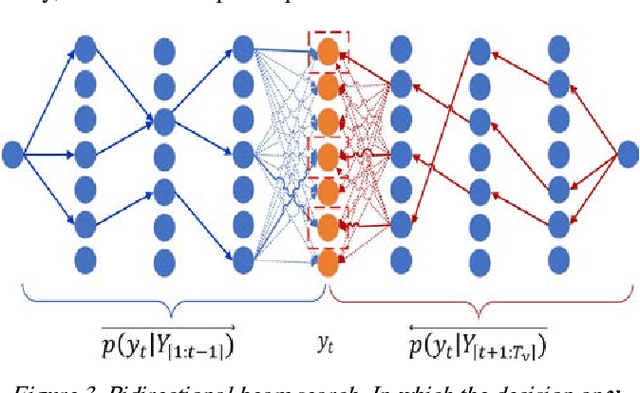
Sequence generative models with RNN variants, such as LSTM, GRU, show promising performance on abstractive document summarization. However, they still have some issues that limit their performance, especially while deal-ing with long sequences. One of the issues is that, to the best of our knowledge, all current models employ a unidirectional decoder, which reasons only about the past and still limited to retain future context while giving a prediction. This makes these models suffer on their own by generating unbalanced outputs. Moreover, unidirec-tional attention-based document summarization can only capture partial aspects of attentional regularities due to the inherited challenges in document summarization. To this end, we propose an end-to-end trainable bidirectional RNN model to tackle the aforementioned issues. The model has a bidirectional encoder-decoder architecture; in which the encoder and the decoder are bidirectional LSTMs. The forward decoder is initialized with the last hidden state of the backward encoder while the backward decoder is initialized with the last hidden state of the for-ward encoder. In addition, a bidirectional beam search mechanism is proposed as an approximate inference algo-rithm for generating the output summaries from the bidi-rectional model. This enables the model to reason about the past and future and to generate balanced outputs as a result. Experimental results on CNN / Daily Mail dataset show that the proposed model outperforms the current abstractive state-of-the-art models by a considerable mar-gin.
An Enhanced Latent Semantic Analysis Approach for Arabic Document Summarization
Jul 31, 2018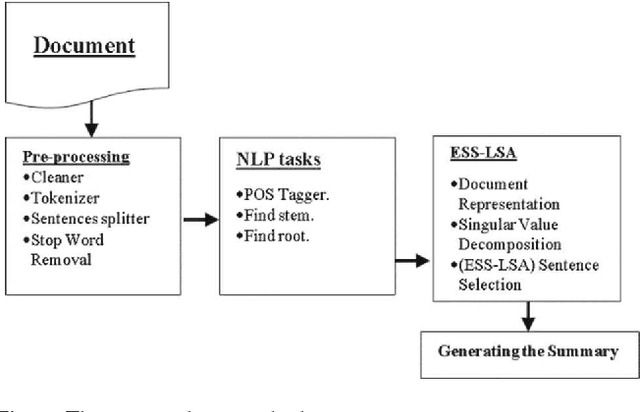
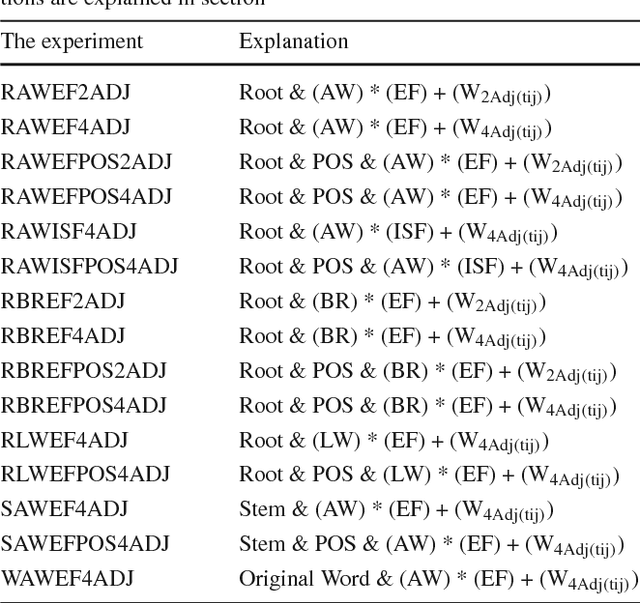

The fast-growing amount of information on the Internet makes the research in automatic document summarization very urgent. It is an effective solution for information overload. Many approaches have been proposed based on different strategies, such as latent semantic analysis (LSA). However, LSA, when applied to document summarization, has some limitations which diminish its performance. In this work, we try to overcome these limitations by applying statistic and linear algebraic approaches combined with syntactic and semantic processing of text. First, the part of speech tagger is utilized to reduce the dimension of LSA. Then, the weight of the term in four adjacent sentences is added to the weighting schemes while calculating the input matrix to take into account the word order and the syntactic relations. In addition, a new LSA-based sentence selection algorithm is proposed, in which the term description is combined with sentence description for each topic which in turn makes the generated summary more informative and diverse. To ensure the effectiveness of the proposed LSA-based sentence selection algorithm, extensive experiment on Arabic and English are done. Four datasets are used to evaluate the new model, Linguistic Data Consortium (LDC) Arabic Newswire-a corpus, Essex Arabic Summaries Corpus (EASC), DUC2002, and Multilingual MSS 2015 dataset. Experimental results on the four datasets show the effectiveness of the proposed model on Arabic and English datasets. It performs comprehensively better compared to the state-of-the-art methods.
* This is a pre-print of an article published in Arabian Journal for Science and Engineering. The final authenticated version is available online at: https://doi.org/10.1007/s13369-018-3286-z
A Hierarchical Structured Self-Attentive Model for Extractive Document Summarization (HSSAS)
May 20, 2018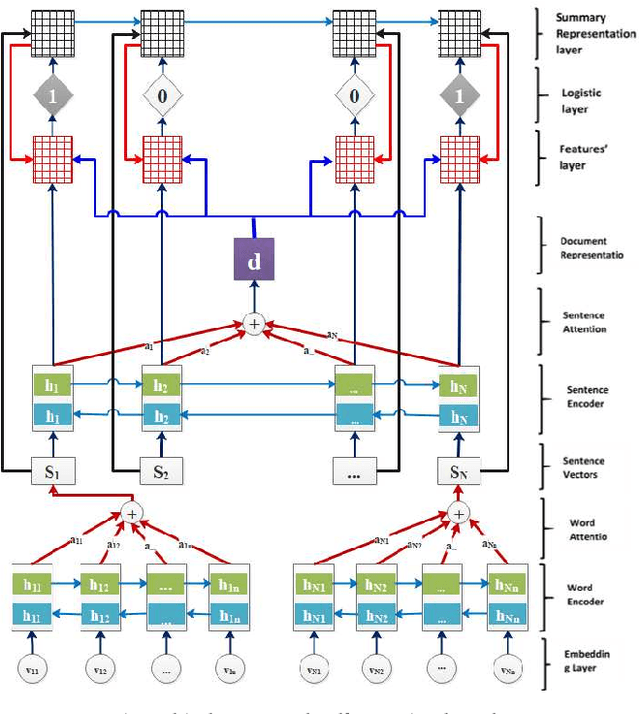
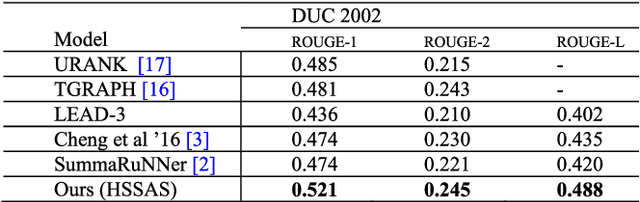
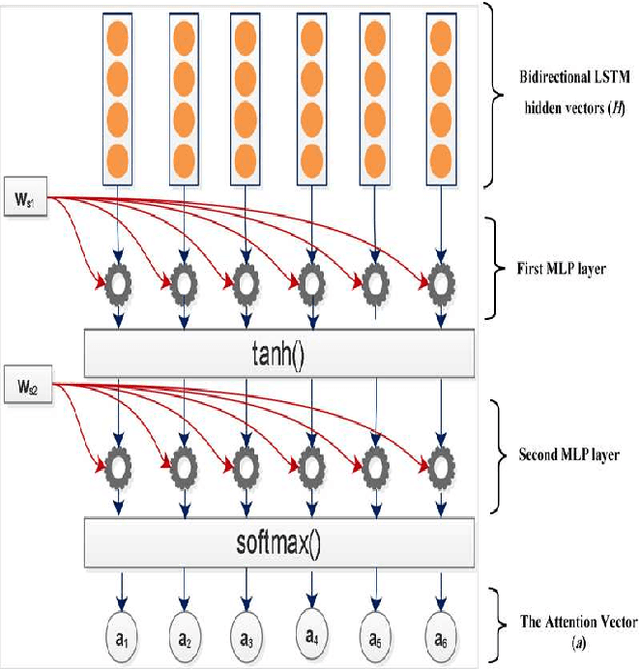
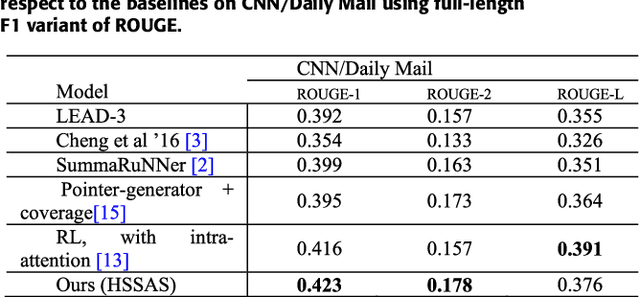
The recent advance in neural network architecture and training algorithms have shown the effectiveness of representation learning. The neural network-based models generate better representation than the traditional ones. They have the ability to automatically learn the distributed representation for sentences and documents. To this end, we proposed a novel model that addresses several issues that are not adequately modeled by the previously proposed models, such as the memory problem and incorporating the knowledge of document structure. Our model uses a hierarchical structured self-attention mechanism to create the sentence and document embeddings. This architecture mirrors the hierarchical structure of the document and in turn enables us to obtain better feature representation. The attention mechanism provides extra source of information to guide the summary extraction. The new model treated the summarization task as a classification problem in which the model computes the respective probabilities of sentence-summary membership. The model predictions are broken up by several features such as information content, salience, novelty and positional representation. The proposed model was evaluated on two well-known datasets, the CNN / Daily Mail, and DUC 2002. The experimental results show that our model outperforms the current extractive state-of-the-art by a considerable margin.