 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Passive and Active: Enhancing Conversation Starter Recommendation via Active Expression Modeling
May 07, 2026Large Language Model (LLM)-driven conversational search is shifting information retrieval from reactive keyword matching to proactive, open-ended dialogues. In this context, Conversation Starters are widely deployed to provide personalized query recommendations that help users initiate dialogues. Conventionally, recommending these starters relies on a closed "exposure-click" loop. Yet, this feedback loop mechanism traps the system in an echo chamber where, compounded by data sparsity, it fails to capture the dynamic nature of conversational search intents shaped by the open world. As a result, the system skews towards popular but generic suggestions.In this work, we uncover an untapped paradigm shift to shatter this harmful feedback loop: harnessing user "free will" through active user expressions. Unlike traditional recommendations, conversational search empowers users to bypass menus entirely through manually typed queries. The open-world intents in active queries hold the key to breaking this loop. However, incorporating them is non-trivial: (1) there exists an inherent distribution shift between active queries and formulated starters. (2) Furthermore, the "non-ID-able" nature of open text renders traditional item-based popularity statistics ineffective for large-scale industrial streaming training. To this end, we propose Passive-Active Bridge (PA-Bridge), a novel framework that employs an adversarial distribution aligner to bridge the distributional gap between passively recommended starters and active expressions. Moreover, we introduce a semantic discretizer to enable the deployment of popularity debiasing algorithms. Online A/B tests on our platform, demonstrate that PA-Bridge significantly boosts the Feature Penetration Rate by 0.54% and User Active Days
IceBreaker for Conversational Agents: Breaking the First-Message Barrier with Personalized Starters
Apr 20, 2026Conversational agents, such as ChatGPT and Doubao, have become essential daily assistants for billions of users. To further enhance engagement, these systems are evolving from passive responders to proactive companions. However, existing efforts focus on activation within ongoing dialogues, while overlooking a key real-world bottleneck. In the conversation initiation stage, users may have a vague need but no explicit query intent, creating a first-message barrier where the conversation holds before it begins. To overcome this, we introduce Conversation Starter Generation: generating personalized starters to guide users into conversation. However, unlike in-conversation stages where immediate context guides the response, initiation must operate in a cold-start moment without explicit user intent. To pioneer in this direction, we present IceBreaker that frames human ice-breaking as a two-step handshake: (i) evoke resonance via Resonance-Aware Interest Distillation from session summaries to capture trigger interests, and (ii) stimulate interaction via Interaction-Oriented Starter Generation, optimized with personalized preference alignment and a self-reinforced loop to maximize engagement. Online A/B tests on one of the world's largest conversational agent products show that IceBreaker improves user active days by +0.184% and click-through rate by +9.425%, and has been deployed in production.
XSkill: Continual Learning from Experience and Skills in Multimodal Agents
Mar 12, 2026Multimodal agents can now tackle complex reasoning tasks with diverse tools, yet they still suffer from inefficient tool use and inflexible orchestration in open-ended settings. A central challenge is enabling such agents to continually improve without parameter updates by learning from past trajectories. We identify two complementary forms of reusable knowledge essential for this goal: experiences, providing concise action-level guidance for tool selection and decision making, and skills, providing structured task-level guidance for planning and tool use. To this end, we propose XSkill, a dual-stream framework for continual learning from experience and skills in multimodal agents. XSkill grounds both knowledge extraction and retrieval in visual observations. During accumulation, XSkill distills and consolidates experiences and skills from multi-path rollouts via visually grounded summarization and cross-rollout critique. During inference, it retrieves and adapts this knowledge to the current visual context and feeds usage history back into accumulation to form a continual learning loop. Evaluated on five benchmarks across diverse domains with four backbone models, XSkill consistently and substantially outperforms both tool-only and learning-based baselines. Further analysis reveals that the two knowledge streams play complementary roles in influencing the reasoning behaviors of agents and show superior zero-shot generalization.
AgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios
Feb 26, 2026Real-world multimodal agents solve multi-step workflows grounded in visual evidence. For example, an agent can troubleshoot a device by linking a wiring photo to a schematic and validating the fix with online documentation, or plan a trip by interpreting a transit map and checking schedules under routing constraints. However, existing multimodal benchmarks mainly evaluate single-turn visual reasoning or specific tool skills, and they do not fully capture the realism, visual subtlety, and long-horizon tool use that practical agents require. We introduce AgentVista, a benchmark for generalist multimodal agents that spans 25 sub-domains across 7 categories, pairing realistic and detail-rich visual scenarios with natural hybrid tool use. Tasks require long-horizon tool interactions across modalities, including web search, image search, page navigation, and code-based operations for both image processing and general programming. Comprehensive evaluation of state-of-the-art models exposes significant gaps in their ability to carry out long-horizon multimodal tool use. Even the best model in our evaluation, Gemini-3-Pro with tools, achieves only 27.3% overall accuracy, and hard instances can require more than 25 tool-calling turns. We expect AgentVista to accelerate the development of more capable and reliable multimodal agents for realistic and ultra-challenging problem solving.
Long-Term Interest Clock: Fine-Grained Time Perception in Streaming Recommendation System
Jan 27, 2025


User interests manifest a dynamic pattern within the course of a day, e.g., a user usually favors soft music at 8 a.m. but may turn to ambient music at 10 p.m. To model dynamic interests in a day, hour embedding is widely used in traditional daily-trained industrial recommendation systems. However, its discreteness can cause periodical online patterns and instability in recent streaming recommendation systems. Recently, Interest Clock has achieved remarkable performance in streaming recommendation systems. Nevertheless, it models users' dynamic interests in a coarse-grained manner, merely encoding users' discrete interests of 24 hours from short-term behaviors. In this paper, we propose a fine-grained method for perceiving time information for streaming recommendation systems, named Long-term Interest Clock (LIC). The key idea of LIC is adaptively calculating current user interests by taking into consideration the relevance of long-term behaviors around current time (e.g., 8 a.m.) given a candidate item. LIC consists of two modules: (1) Clock-GSU retrieves a sub-sequence by searching through long-term behaviors, using query information from a candidate item and current time, (2) Clock-ESU employs a time-gap-aware attention mechanism to aggregate sub-sequence with the candidate item. With Clock-GSU and Clock-ESU, LIC is capable of capturing users' dynamic fine-grained interests from long-term behaviors. We conduct online A/B tests, obtaining +0.122% improvements on user active days. Besides, the extended offline experiments show improvements as well. Long-term Interest Clock has been integrated into Douyin Music App's recommendation system.
Multi-head Sequence Tagging Model for Grammatical Error Correction
Oct 21, 2024
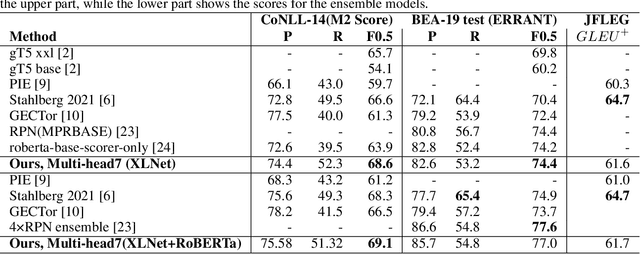
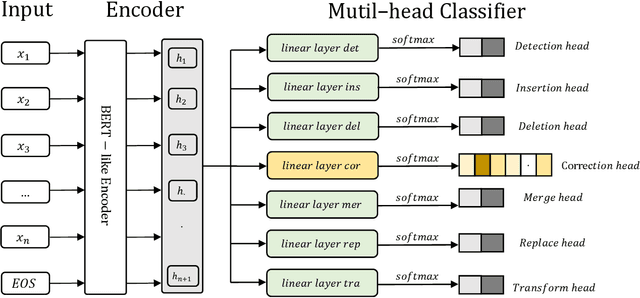

To solve the Grammatical Error Correction (GEC) problem , a mapping between a source sequence and a target one is needed, where the two differ only on few spans. For this reason, the attention has been shifted to the non-autoregressive or sequence tagging models. In which, the GEC has been simplified from Seq2Seq to labeling the input tokens with edit commands chosen from a large edit space. Due to this large number of classes and the limitation of the available datasets, the current sequence tagging approaches still have some issues handling a broad range of grammatical errors just by being laser-focused on one single task. To this end, we simplified the GEC further by dividing it into seven related subtasks: Insertion, Deletion, Merge, Substitution, Transformation, Detection, and Correction, with Correction being our primary focus. A distinct classification head is dedicated to each of these subtasks. the novel multi-head and multi-task learning model is proposed to effectively utilize training data and harness the information from related task training signals. To mitigate the limited number of available training samples, a new denoising autoencoder is used to generate a new synthetic dataset to be used for pretraining. Additionally, a new character-level transformation is proposed to enhance the sequence-to-edit function and improve the model's vocabulary coverage. Our single/ensemble model achieves an F0.5 of 74.4/77.0, and 68.6/69.1 on BEA-19 (test) and CoNLL-14 (test) respectively. Moreover, evaluated on JFLEG test set, the GLEU scores are 61.6 and 61.7 for the single and ensemble models, respectively. It mostly outperforms recently published state-of-the-art results by a considerable margin.