 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuChator: Enabling Active Music Discovery via Conversational Music LLMs in Douyin Music
May 26, 2026Douyin Music, a large-scale platform with millions of daily users, adopts an immersive, feed-based discovery paradigm, where users passively explore music through continuous recommendations. While effective for passive music discovery, this paradigm restricts users to recommendation results and provides limited support for explicitly specifying listening intents. Unlike conventional search, where users express well-defined intents through explicit queries such as specific songs or artists, real-world active music discovery is often situational and colloquial, involving vague or underspecified requests. While LLMs enable natural language interaction, their direct use in music discovery remains limited by insufficient music-domain knowledge, lack of music-query collaborative reasoning, and shallow understanding of personalized preferences. To address these challenges, we introduce MuChator, an interactive MusicLLM-based framework that enables users to actively express situational music intents in natural language. MuChator incorporates three key components: (1) Music Knowledge Pre-training, a three-stage scheme that incrementally injects objective music knowledge, subjective music knowledge, and personalized music preferences into LLMs; (2) Context-aware Instruction Tuning, which constructs high-quality user-query-music triplets through an automated synthesis pipeline to align LLMs with active and situational user intents; and (3) Preference Alignment with Hybrid RM, which jointly models intent relevance, personalized preferences, and basic constraints, and is optimized using GRPO-based reinforcement learning. Extensive evaluations on industrial music recommendation datasets demonstrate that MuChator outperforms leading proprietary models, such as Gemini-3-Pro. The model has been deployed on Douyin Music App within ByteDance, with 46.49\% improvement of user active days in online A/B test.
Bridging Passive and Active: Enhancing Conversation Starter Recommendation via Active Expression Modeling
May 07, 2026Large Language Model (LLM)-driven conversational search is shifting information retrieval from reactive keyword matching to proactive, open-ended dialogues. In this context, Conversation Starters are widely deployed to provide personalized query recommendations that help users initiate dialogues. Conventionally, recommending these starters relies on a closed "exposure-click" loop. Yet, this feedback loop mechanism traps the system in an echo chamber where, compounded by data sparsity, it fails to capture the dynamic nature of conversational search intents shaped by the open world. As a result, the system skews towards popular but generic suggestions.In this work, we uncover an untapped paradigm shift to shatter this harmful feedback loop: harnessing user "free will" through active user expressions. Unlike traditional recommendations, conversational search empowers users to bypass menus entirely through manually typed queries. The open-world intents in active queries hold the key to breaking this loop. However, incorporating them is non-trivial: (1) there exists an inherent distribution shift between active queries and formulated starters. (2) Furthermore, the "non-ID-able" nature of open text renders traditional item-based popularity statistics ineffective for large-scale industrial streaming training. To this end, we propose Passive-Active Bridge (PA-Bridge), a novel framework that employs an adversarial distribution aligner to bridge the distributional gap between passively recommended starters and active expressions. Moreover, we introduce a semantic discretizer to enable the deployment of popularity debiasing algorithms. Online A/B tests on our platform, demonstrate that PA-Bridge significantly boosts the Feature Penetration Rate by 0.54% and User Active Days
IceBreaker for Conversational Agents: Breaking the First-Message Barrier with Personalized Starters
Apr 20, 2026Conversational agents, such as ChatGPT and Doubao, have become essential daily assistants for billions of users. To further enhance engagement, these systems are evolving from passive responders to proactive companions. However, existing efforts focus on activation within ongoing dialogues, while overlooking a key real-world bottleneck. In the conversation initiation stage, users may have a vague need but no explicit query intent, creating a first-message barrier where the conversation holds before it begins. To overcome this, we introduce Conversation Starter Generation: generating personalized starters to guide users into conversation. However, unlike in-conversation stages where immediate context guides the response, initiation must operate in a cold-start moment without explicit user intent. To pioneer in this direction, we present IceBreaker that frames human ice-breaking as a two-step handshake: (i) evoke resonance via Resonance-Aware Interest Distillation from session summaries to capture trigger interests, and (ii) stimulate interaction via Interaction-Oriented Starter Generation, optimized with personalized preference alignment and a self-reinforced loop to maximize engagement. Online A/B tests on one of the world's largest conversational agent products show that IceBreaker improves user active days by +0.184% and click-through rate by +9.425%, and has been deployed in production.
AdaF^2M^2: Comprehensive Learning and Responsive Leveraging Features in Recommendation System
Jan 27, 2025



Feature modeling, which involves feature representation learning and leveraging, plays an essential role in industrial recommendation systems. However, the data distribution in real-world applications usually follows a highly skewed long-tail pattern due to the popularity bias, which easily leads to over-reliance on ID-based features, such as user/item IDs and ID sequences of interactions. Such over-reliance makes it hard for models to learn features comprehensively, especially for those non-ID meta features, e.g., user/item characteristics. Further, it limits the feature leveraging ability in models, getting less generalized and more susceptible to data noise. Previous studies on feature modeling focus on feature extraction and interaction, hardly noticing the problems brought about by the long-tail data distribution. To achieve better feature representation learning and leveraging on real-world data, we propose a model-agnostic framework AdaF^2M^2, short for Adaptive Feature Modeling with Feature Mask. The feature-mask mechanism helps comprehensive feature learning via multi-forward training with augmented samples, while the adapter applies adaptive weights on features responsive to different user/item states. By arming base models with AdaF^2M^2, we conduct online A/B tests on multiple recommendation scenarios, obtaining +1.37% and +1.89% cumulative improvements on user active days and app duration respectively. Besides, the extended offline experiments on different models show improvements as well. AdaF$^2$M$^2$ has been widely deployed on both retrieval and ranking tasks in multiple applications of Douyin Group, indicating its superior effectiveness and universality.
Long-Term Interest Clock: Fine-Grained Time Perception in Streaming Recommendation System
Jan 27, 2025


User interests manifest a dynamic pattern within the course of a day, e.g., a user usually favors soft music at 8 a.m. but may turn to ambient music at 10 p.m. To model dynamic interests in a day, hour embedding is widely used in traditional daily-trained industrial recommendation systems. However, its discreteness can cause periodical online patterns and instability in recent streaming recommendation systems. Recently, Interest Clock has achieved remarkable performance in streaming recommendation systems. Nevertheless, it models users' dynamic interests in a coarse-grained manner, merely encoding users' discrete interests of 24 hours from short-term behaviors. In this paper, we propose a fine-grained method for perceiving time information for streaming recommendation systems, named Long-term Interest Clock (LIC). The key idea of LIC is adaptively calculating current user interests by taking into consideration the relevance of long-term behaviors around current time (e.g., 8 a.m.) given a candidate item. LIC consists of two modules: (1) Clock-GSU retrieves a sub-sequence by searching through long-term behaviors, using query information from a candidate item and current time, (2) Clock-ESU employs a time-gap-aware attention mechanism to aggregate sub-sequence with the candidate item. With Clock-GSU and Clock-ESU, LIC is capable of capturing users' dynamic fine-grained interests from long-term behaviors. We conduct online A/B tests, obtaining +0.122% improvements on user active days. Besides, the extended offline experiments show improvements as well. Long-term Interest Clock has been integrated into Douyin Music App's recommendation system.
Interest Clock: Time Perception in Real-Time Streaming Recommendation System
Apr 30, 2024



User preferences follow a dynamic pattern over a day, e.g., at 8 am, a user might prefer to read news, while at 8 pm, they might prefer to watch movies. Time modeling aims to enable recommendation systems to perceive time changes to capture users' dynamic preferences over time, which is an important and challenging problem in recommendation systems. Especially, streaming recommendation systems in the industry, with only available samples of the current moment, present greater challenges for time modeling. There is still a lack of effective time modeling methods for streaming recommendation systems. In this paper, we propose an effective and universal method Interest Clock to perceive time information in recommendation systems. Interest Clock first encodes users' time-aware preferences into a clock (hour-level personalized features) and then uses Gaussian distribution to smooth and aggregate them into the final interest clock embedding according to the current time for the final prediction. By arming base models with Interest Clock, we conduct online A/B tests, obtaining +0.509% and +0.758% improvements on user active days and app duration respectively. Besides, the extended offline experiments show improvements as well. Interest Clock has been deployed on Douyin Music App.
Multi-Representation Adaptation Network for Cross-domain Image Classification
Jan 04, 2022
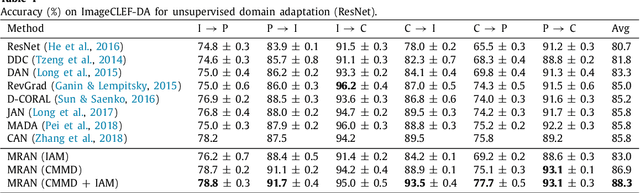
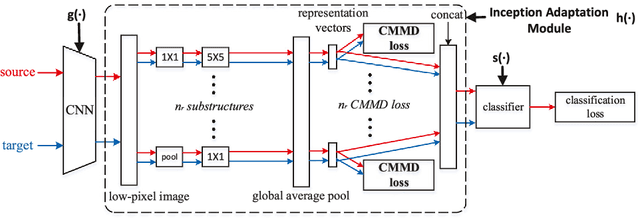
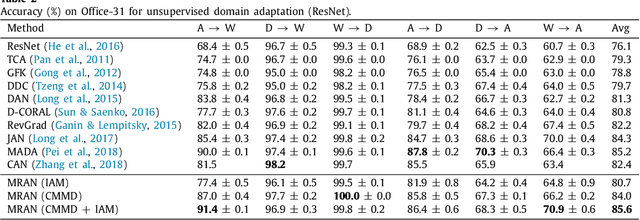
In image classification, it is often expensive and time-consuming to acquire sufficient labels. To solve this problem, domain adaptation often provides an attractive option given a large amount of labeled data from a similar nature but different domain. Existing approaches mainly align the distributions of representations extracted by a single structure and the representations may only contain partial information, e.g., only contain part of the saturation, brightness, and hue information. Along this line, we propose Multi-Representation Adaptation which can dramatically improve the classification accuracy for cross-domain image classification and specially aims to align the distributions of multiple representations extracted by a hybrid structure named Inception Adaptation Module (IAM). Based on this, we present Multi-Representation Adaptation Network (MRAN) to accomplish the cross-domain image classification task via multi-representation alignment which can capture the information from different aspects. In addition, we extend Maximum Mean Discrepancy (MMD) to compute the adaptation loss. Our approach can be easily implemented by extending most feed-forward models with IAM, and the network can be trained efficiently via back-propagation. Experiments conducted on three benchmark image datasets demonstrate the effectiveness of MRAN. The code has been available at https://github.com/easezyc/deep-transfer-learning.
Deep Subdomain Adaptation Network for Image Classification
Jun 17, 2021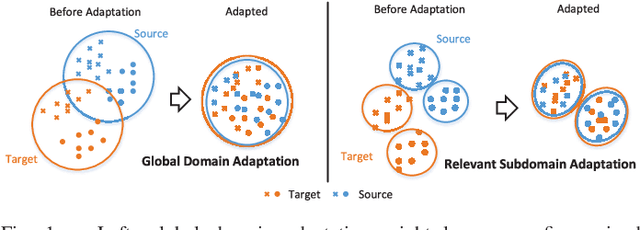
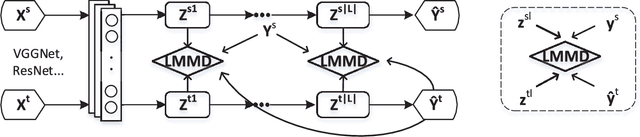
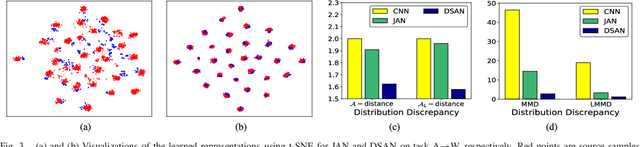
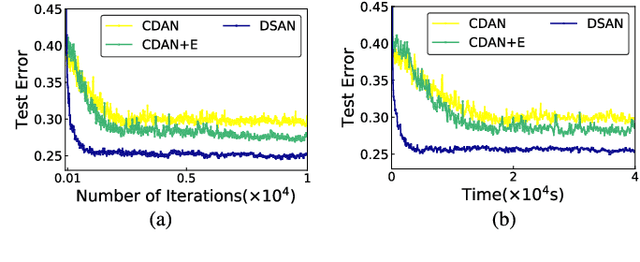
For a target task where labeled data is unavailable, domain adaptation can transfer a learner from a different source domain. Previous deep domain adaptation methods mainly learn a global domain shift, i.e., align the global source and target distributions without considering the relationships between two subdomains within the same category of different domains, leading to unsatisfying transfer learning performance without capturing the fine-grained information. Recently, more and more researchers pay attention to Subdomain Adaptation which focuses on accurately aligning the distributions of the relevant subdomains. However, most of them are adversarial methods which contain several loss functions and converge slowly. Based on this, we present Deep Subdomain Adaptation Network (DSAN) which learns a transfer network by aligning the relevant subdomain distributions of domain-specific layer activations across different domains based on a local maximum mean discrepancy (LMMD). Our DSAN is very simple but effective which does not need adversarial training and converges fast. The adaptation can be achieved easily with most feed-forward network models by extending them with LMMD loss, which can be trained efficiently via back-propagation. Experiments demonstrate that DSAN can achieve remarkable results on both object recognition tasks and digit classification tasks. Our code will be available at: https://github.com/easezyc/deep-transfer-learning
Atom Responding Machine for Dialog Generation
May 15, 2019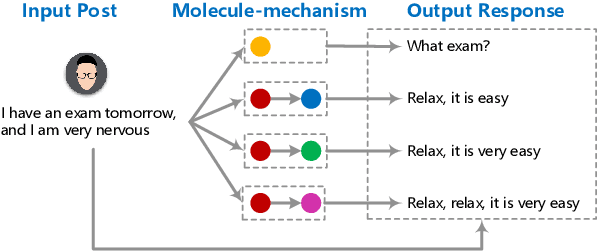
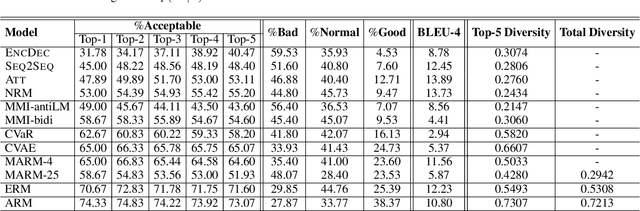
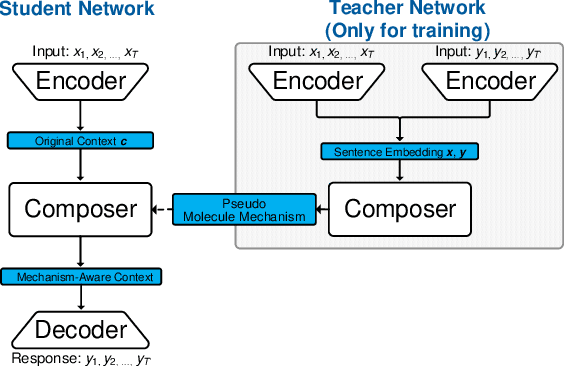
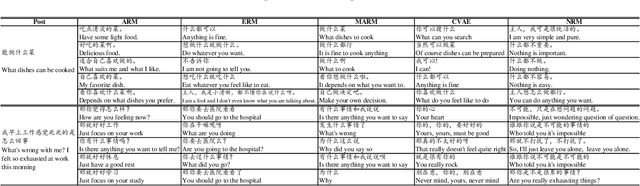
Recently, improving the relevance and diversity of dialogue system has attracted wide attention. For a post x, the corresponding response y is usually diverse in the real-world corpus, while the conventional encoder-decoder model tends to output the high-frequency (safe but trivial) responses and thus is difficult to handle the large number of responding styles. To address these issues, we propose the Atom Responding Machine (ARM), which is based on a proposed encoder-composer-decoder network trained by a teacher-student framework. To enrich the generated responses, ARM introduces a large number of molecule-mechanisms as various responding styles, which are conducted by taking different combinations from a few atom-mechanisms. In other words, even a little of atom-mechanisms can make a mickle of molecule-mechanisms. The experiments demonstrate diversity and quality of the responses generated by ARM. We also present generating process to show underlying interpretability for the result.