 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatten: Video Action Recognition is an Image Classification task
Aug 17, 2024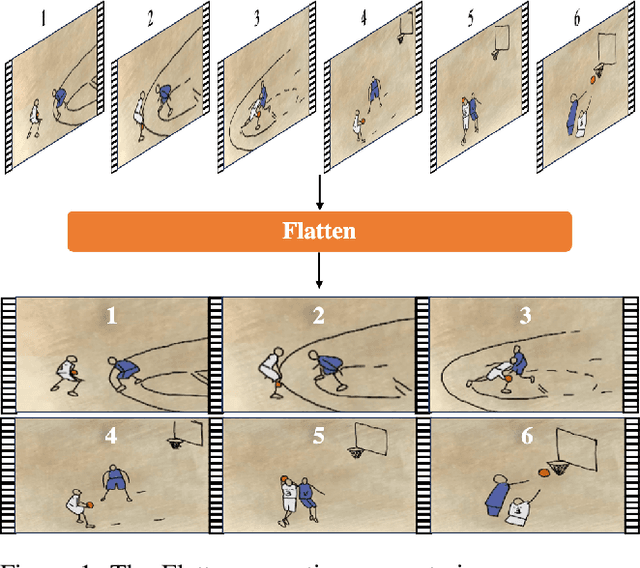
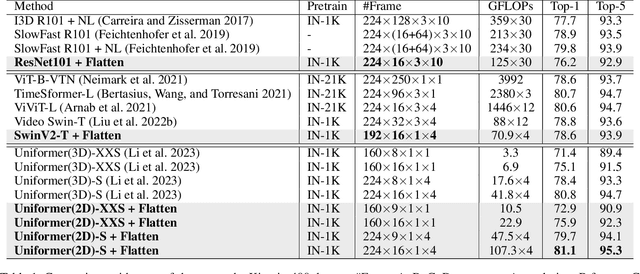
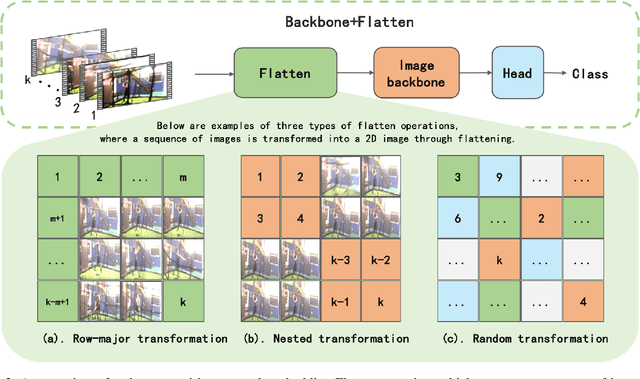
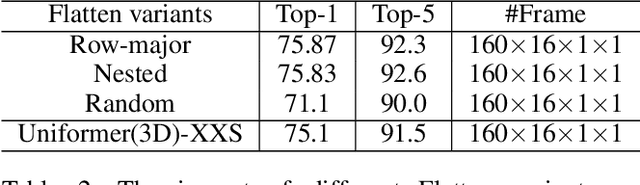
In recent years, video action recognition, as a fundamental task in the field of video understanding, has been deeply explored by numerous researchers.Most traditional video action recognition methods typically involve converting videos into three-dimensional data that encapsulates both spatial and temporal information, subsequently leveraging prevalent image understanding models to model and analyze these data. However,these methods have significant drawbacks. Firstly, when delving into video action recognition tasks, image understanding models often need to be adapted accordingly in terms of model architecture and preprocessing for these spatiotemporal tasks; Secondly, dealing with high-dimensional data often poses greater challenges and incurs higher time costs compared to its lower-dimensional counterparts.To bridge the gap between image-understanding and video-understanding tasks while simplifying the complexity of video comprehension, we introduce a novel video representation architecture, Flatten, which serves as a plug-and-play module that can be seamlessly integrated into any image-understanding network for efficient and effective 3D temporal data modeling.Specifically, by applying specific flattening operations (e.g., row-major transform), 3D spatiotemporal data is transformed into 2D spatial information, and then ordinary image understanding models are used to capture temporal dynamic and spatial semantic information, which in turn accomplishes effective and efficient video action recognition. Extensive experiments on commonly used datasets (Kinetics-400, Something-Something v2, and HMDB-51) and three classical image classification models (Uniformer, SwinV2, and ResNet), have demonstrated that embedding Flatten provides a significant performance improvements over original model.
Formalization of Robot Collision Detection Method based on Conformal Geometric Algebra
Dec 06, 2023Cooperative robots can significantly assist people in their productive activities, improving the quality of their works. Collision detection is vital to ensure the safe and stable operation of cooperative robots in productive activities. As an advanced geometric language, conformal geometric algebra can simplify the construction of the robot collision model and the calculation of collision distance. Compared with the formal method based on conformal geometric algebra, the traditional method may have some defects which are difficult to find in the modelling and calculation. We use the formal method based on conformal geometric algebra to study the collision detection problem of cooperative robots. This paper builds formal models of geometric primitives and the robot body based on the conformal geometric algebra library in HOL Light. We analyse the shortest distance between geometric primitives and prove their collision determination conditions. Based on the above contents, we construct a formal verification framework for the robot collision detection method. By the end of this paper, we apply the proposed framework to collision detection between two single-arm industrial cooperative robots. The flexibility and reliability of the proposed framework are verified by constructing a general collision model and a special collision model for two single-arm industrial cooperative robots.
A Consumer-tier based Visual-Brain Machine Interface for Augmented Reality Glasses Interactions
Aug 29, 2023



Objective.Visual-Brain Machine Interface(V-BMI) has provide a novel interaction technique for Augmented Reality (AR) industries. Several state-of-arts work has demonstates its high accuracy and real-time interaction capbilities. However, most of the studies employ EEGs devices that are rigid and difficult to apply in real-life AR glasseses application sceniraros. Here we develop a consumer-tier Visual-Brain Machine Inteface(V-BMI) system specialized for Augmented Reality(AR) glasses interactions. Approach. The developed system consists of a wearable hardware which takes advantages of fast set-up, reliable recording and comfortable wearable experience that specificized for AR glasses applications. Complementing this hardware, we have devised a software framework that facilitates real-time interactions within the system while accommodating a modular configuration to enhance scalability. Main results. The developed hardware is only 110g and 120x85x23 mm, which with 1 Tohm and peak to peak voltage is less than 1.5 uV, and a V-BMI based angry bird game and an Internet of Thing (IoT) AR applications are deisgned, we demonstrated such technology merits of intuitive experience and efficiency interaction. The real-time interaction accuracy is between 85 and 96 percentages in a commercial AR glasses (DTI is 2.24s and ITR 65 bits-min ). Significance. Our study indicates the developed system can provide an essential hardware-software framework for consumer based V-BMI AR glasses. Also, we derive several pivotal design factors for a consumer-grade V-BMI-based AR system: 1) Dynamic adaptation of stimulation patterns-classification methods via computer vision algorithms is necessary for AR glasses applications; and 2) Algorithmic localization to foster system stability and latency reduction.
Multi-Representation Adaptation Network for Cross-domain Image Classification
Jan 04, 2022
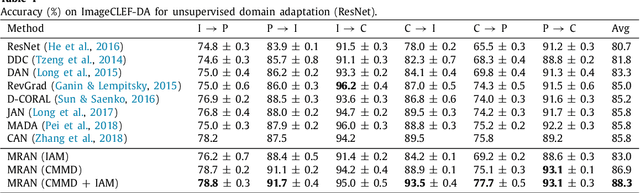
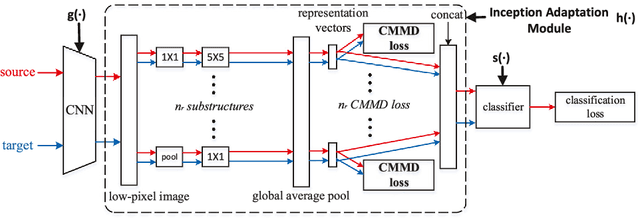
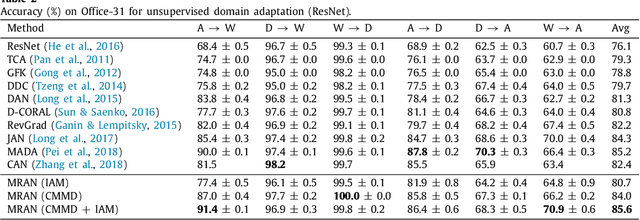
In image classification, it is often expensive and time-consuming to acquire sufficient labels. To solve this problem, domain adaptation often provides an attractive option given a large amount of labeled data from a similar nature but different domain. Existing approaches mainly align the distributions of representations extracted by a single structure and the representations may only contain partial information, e.g., only contain part of the saturation, brightness, and hue information. Along this line, we propose Multi-Representation Adaptation which can dramatically improve the classification accuracy for cross-domain image classification and specially aims to align the distributions of multiple representations extracted by a hybrid structure named Inception Adaptation Module (IAM). Based on this, we present Multi-Representation Adaptation Network (MRAN) to accomplish the cross-domain image classification task via multi-representation alignment which can capture the information from different aspects. In addition, we extend Maximum Mean Discrepancy (MMD) to compute the adaptation loss. Our approach can be easily implemented by extending most feed-forward models with IAM, and the network can be trained efficiently via back-propagation. Experiments conducted on three benchmark image datasets demonstrate the effectiveness of MRAN. The code has been available at https://github.com/easezyc/deep-transfer-learning.
Temporal Transformer Networks with Self-Supervision for Action Recognition
Dec 17, 2021
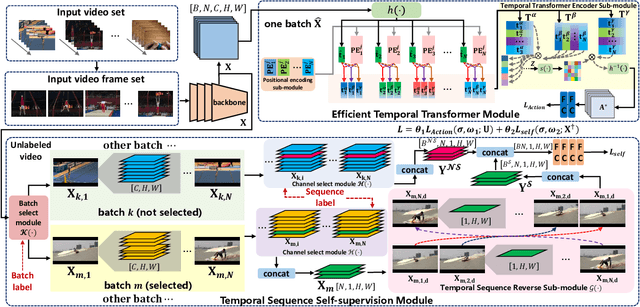
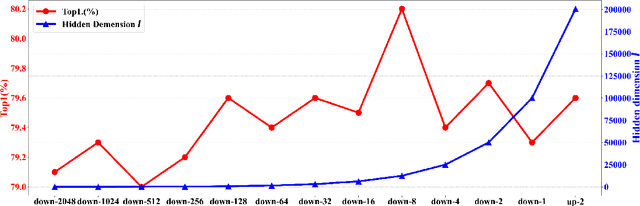
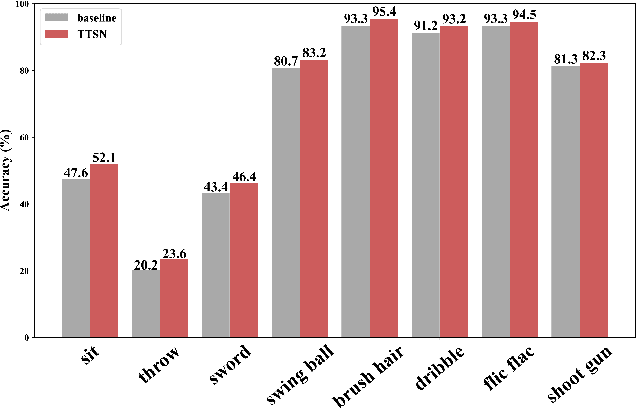
In recent years, 2D Convolutional Networks-based video action recognition has encouragingly gained wide popularity; However, constrained by the lack of long-range non-linear temporal relation modeling and reverse motion information modeling, the performance of existing models is, therefore, undercut seriously. To address this urgent problem, we introduce a startling Temporal Transformer Network with Self-supervision (TTSN). Our high-performance TTSN mainly consists of a temporal transformer module and a temporal sequence self-supervision module. Concisely speaking, we utilize the efficient temporal transformer module to model the non-linear temporal dependencies among non-local frames, which significantly enhances complex motion feature representations. The temporal sequence self-supervision module we employ unprecedentedly adopts the streamlined strategy of "random batch random channel" to reverse the sequence of video frames, allowing robust extractions of motion information representation from inversed temporal dimensions and improving the generalization capability of the model. Extensive experiments on three widely used datasets (HMDB51, UCF101, and Something-something V1) have conclusively demonstrated that our proposed TTSN is promising as it successfully achieves state-of-the-art performance for action recognition.
Combat Data Shift in Few-shot Learning with Knowledge Graph
Feb 26, 2021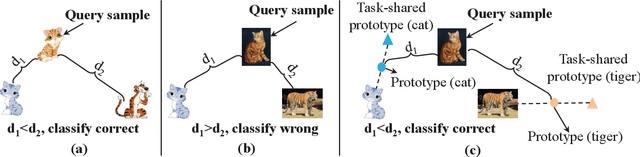
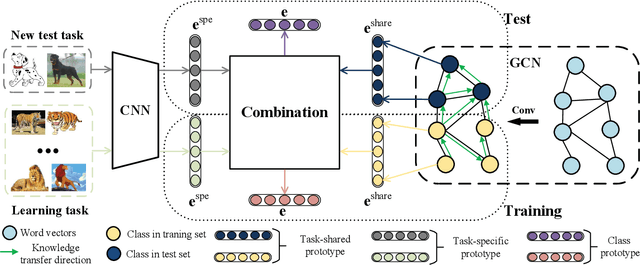
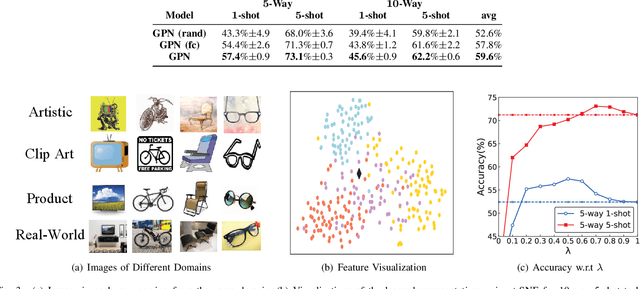
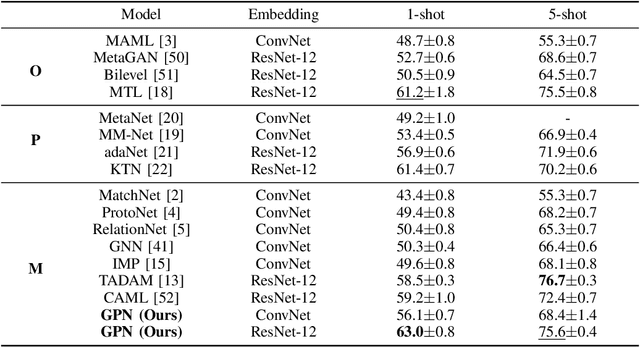
Many few-shot learning approaches have been designed under the meta-learning framework, which learns from a variety of learning tasks and generalizes to new tasks. These meta-learning approaches achieve the expected performance in the scenario where all samples are drawn from the same distributions (i.i.d. observations). However, in real-world applications, few-shot learning paradigm often suffers from data shift, i.e., samples in different tasks, even in the same task, could be drawn from various data distributions. Most existing few-shot learning approaches are not designed with the consideration of data shift, and thus show downgraded performance when data distribution shifts. However, it is non-trivial to address the data shift problem in few-shot learning, due to the limited number of labeled samples in each task. Targeting at addressing this problem, we propose a novel metric-based meta-learning framework to extract task-specific representations and task-shared representations with the help of knowledge graph. The data shift within/between tasks can thus be combated by the combination of task-shared and task-specific representations. The proposed model is evaluated on popular benchmarks and two constructed new challenging datasets. The evaluation results demonstrate its remarkable performance.
Exploring Spatial-Temporal Multi-Frequency Analysis for High-Fidelity and Temporal-Consistency Video Prediction
Feb 23, 2020

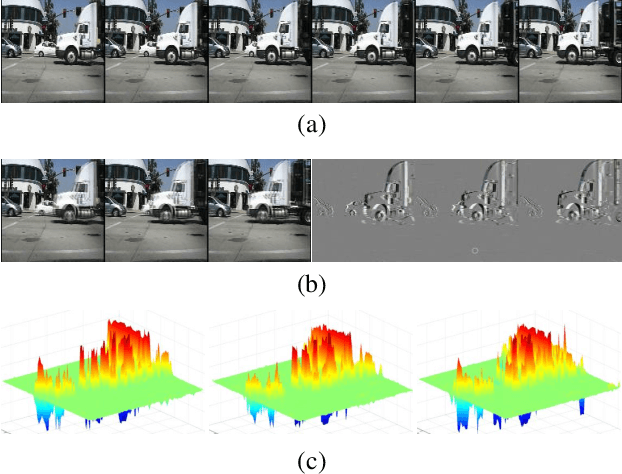
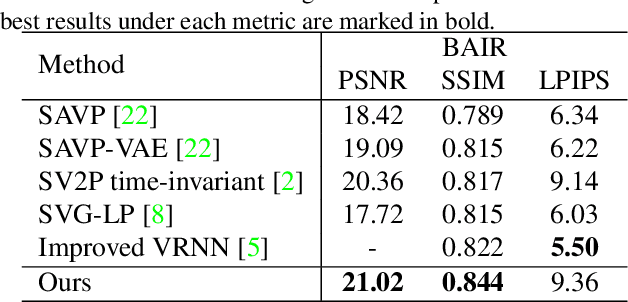
Video prediction is a pixel-wise dense prediction task to infer future frames based on past frames. Missing appearance details and motion blur are still two major problems for current predictive models, which lead to image distortion and temporal inconsistency. In this paper, we point out the necessity of exploring multi-frequency analysis to deal with the two problems. Inspired by the frequency band decomposition characteristic of Human Vision System (HVS), we propose a video prediction network based on multi-level wavelet analysis to deal with spatial and temporal information in a unified manner. Specifically, the multi-level spatial discrete wavelet transform decomposes each video frame into anisotropic sub-bands with multiple frequencies, helping to enrich structural information and reserve fine details. On the other hand, multi-level temporal discrete wavelet transform which operates on time axis decomposes the frame sequence into sub-band groups of different frequencies to accurately capture multi-frequency motions under a fixed frame rate. Extensive experiments on diverse datasets demonstrate that our model shows significant improvements on fidelity and temporal consistency over state-of-the-art works.