 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA-VGGT:Adapting VGGT to Large Scale Localization by Self-Supervised Learning with Geometry and Physics Aware Loss
Jan 26, 2026Transformer-based general visual geometry frameworks have shown promising performance in camera pose estimation and 3D scene understanding. Recent advancements in Visual Geometry Grounded Transformer (VGGT) models have shown great promise in camera pose estimation and 3D reconstruction. However, these models typically rely on ground truth labels for training, posing challenges when adapting to unlabeled and unseen scenes. In this paper, we propose a self-supervised framework to train VGGT with unlabeled data, thereby enhancing its localization capability in large-scale environments. To achieve this, we extend conventional pair-wise relations to sequence-wise geometric constraints for self-supervised learning. Specifically, in each sequence, we sample multiple source frames and geometrically project them onto different target frames, which improves temporal feature consistency. We formulate physical photometric consistency and geometric constraints as a joint optimization loss to circumvent the requirement for hard labels. By training the model with this proposed method, not only the local and global cross-view attention layers but also the camera and depth heads can effectively capture the underlying multi-view geometry. Experiments demonstrate that the model converges within hundreds of iterations and achieves significant improvements in large-scale localization. Our code will be released at https://github.com/X-yangfan/GPA-VGGT.
SLAM in the Dark: Self-Supervised Learning of Pose, Depth and Loop-Closure from Thermal Images
Feb 26, 2025



Visual SLAM is essential for mobile robots, drone navigation, and VR/AR, but traditional RGB camera systems struggle in low-light conditions, driving interest in thermal SLAM, which excels in such environments. However, thermal imaging faces challenges like low contrast, high noise, and limited large-scale annotated datasets, restricting the use of deep learning in outdoor scenarios. We present DarkSLAM, a noval deep learning-based monocular thermal SLAM system designed for large-scale localization and reconstruction in complex lighting conditions.Our approach incorporates the Efficient Channel Attention (ECA) mechanism in visual odometry and the Selective Kernel Attention (SKA) mechanism in depth estimation to enhance pose accuracy and mitigate thermal depth degradation. Additionally, the system includes thermal depth-based loop closure detection and pose optimization, ensuring robust performance in low-texture thermal scenes. Extensive outdoor experiments demonstrate that DarkSLAM significantly outperforms existing methods like SC-Sfm-Learner and Shin et al., delivering precise localization and 3D dense mapping even in challenging nighttime environments.
Flatten: Video Action Recognition is an Image Classification task
Aug 17, 2024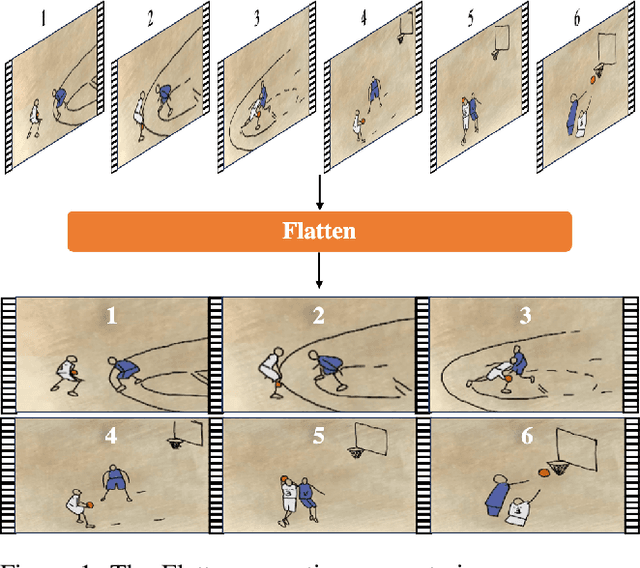
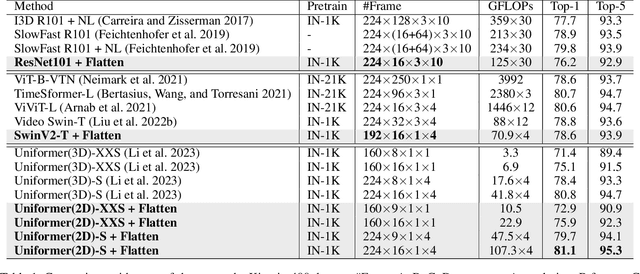
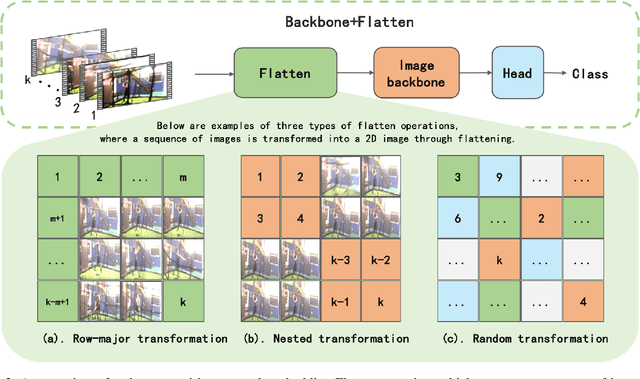
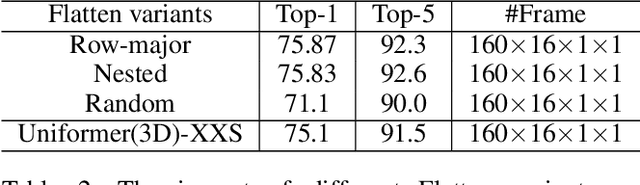
In recent years, video action recognition, as a fundamental task in the field of video understanding, has been deeply explored by numerous researchers.Most traditional video action recognition methods typically involve converting videos into three-dimensional data that encapsulates both spatial and temporal information, subsequently leveraging prevalent image understanding models to model and analyze these data. However,these methods have significant drawbacks. Firstly, when delving into video action recognition tasks, image understanding models often need to be adapted accordingly in terms of model architecture and preprocessing for these spatiotemporal tasks; Secondly, dealing with high-dimensional data often poses greater challenges and incurs higher time costs compared to its lower-dimensional counterparts.To bridge the gap between image-understanding and video-understanding tasks while simplifying the complexity of video comprehension, we introduce a novel video representation architecture, Flatten, which serves as a plug-and-play module that can be seamlessly integrated into any image-understanding network for efficient and effective 3D temporal data modeling.Specifically, by applying specific flattening operations (e.g., row-major transform), 3D spatiotemporal data is transformed into 2D spatial information, and then ordinary image understanding models are used to capture temporal dynamic and spatial semantic information, which in turn accomplishes effective and efficient video action recognition. Extensive experiments on commonly used datasets (Kinetics-400, Something-Something v2, and HMDB-51) and three classical image classification models (Uniformer, SwinV2, and ResNet), have demonstrated that embedding Flatten provides a significant performance improvements over original model.