 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA-VGGT:Adapting VGGT to Large Scale Localization by Self-Supervised Learning with Geometry and Physics Aware Loss
Jan 26, 2026Transformer-based general visual geometry frameworks have shown promising performance in camera pose estimation and 3D scene understanding. Recent advancements in Visual Geometry Grounded Transformer (VGGT) models have shown great promise in camera pose estimation and 3D reconstruction. However, these models typically rely on ground truth labels for training, posing challenges when adapting to unlabeled and unseen scenes. In this paper, we propose a self-supervised framework to train VGGT with unlabeled data, thereby enhancing its localization capability in large-scale environments. To achieve this, we extend conventional pair-wise relations to sequence-wise geometric constraints for self-supervised learning. Specifically, in each sequence, we sample multiple source frames and geometrically project them onto different target frames, which improves temporal feature consistency. We formulate physical photometric consistency and geometric constraints as a joint optimization loss to circumvent the requirement for hard labels. By training the model with this proposed method, not only the local and global cross-view attention layers but also the camera and depth heads can effectively capture the underlying multi-view geometry. Experiments demonstrate that the model converges within hundreds of iterations and achieves significant improvements in large-scale localization. Our code will be released at https://github.com/X-yangfan/GPA-VGGT.
Improve the autonomy of the SE2(3) group based Extended Kalman Filter for Integrated Navigation: Application
Jan 25, 2026One of the core advantages of SE2(3) Lie group framework for navigation modeling lies in the autonomy of error propagation. In the previous paper, the theoretical analysis of autonomy property of navigation model in inertial, earth and world frames was given. A construction method for SE2(3) group navigation model is proposed to improve the non-inertial navigation model toward full autonomy. This paper serves as a counterpart to previous paper and conducts the real-world strapdown inertial navigation system (SINS)/odometer(ODO) experiments as well as Monte-Carlo simulations to demonstrate the performance of improved SE2(3) group based high-precision navigation models.
LangGrasp: Leveraging Fine-Tuned LLMs for Language Interactive Robot Grasping with Ambiguous Instructions
Oct 02, 2025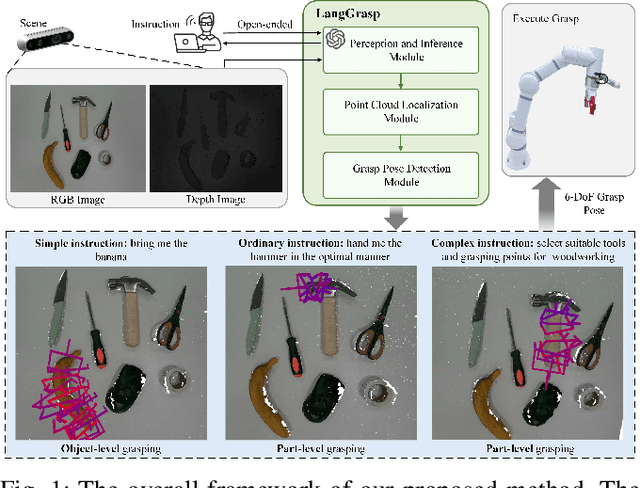
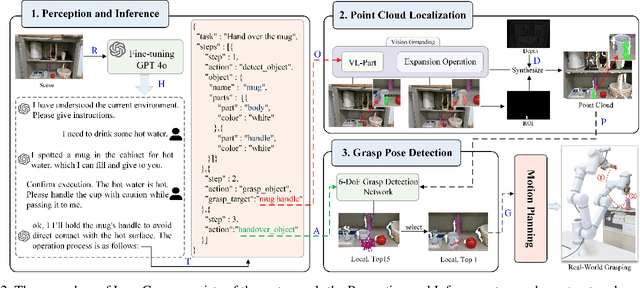

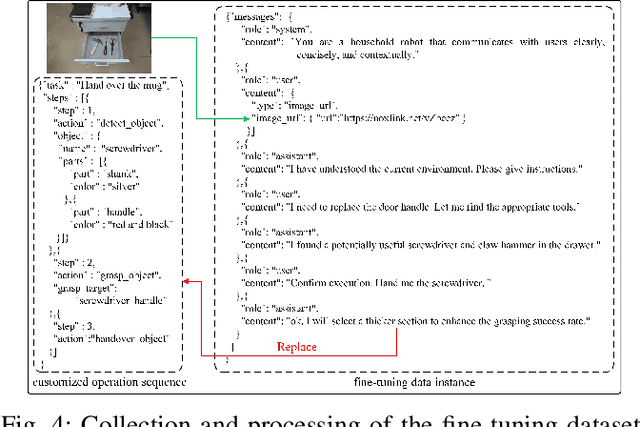
The existing language-driven grasping methods struggle to fully handle ambiguous instructions containing implicit intents. To tackle this challenge, we propose LangGrasp, a novel language-interactive robotic grasping framework. The framework integrates fine-tuned large language models (LLMs) to leverage their robust commonsense understanding and environmental perception capabilities, thereby deducing implicit intents from linguistic instructions and clarifying task requirements along with target manipulation objects. Furthermore, our designed point cloud localization module, guided by 2D part segmentation, enables partial point cloud localization in scenes, thereby extending grasping operations from coarse-grained object-level to fine-grained part-level manipulation. Experimental results show that the LangGrasp framework accurately resolves implicit intents in ambiguous instructions, identifying critical operations and target information that are unstated yet essential for task completion. Additionally, it dynamically selects optimal grasping poses by integrating environmental information. This enables high-precision grasping from object-level to part-level manipulation, significantly enhancing the adaptability and task execution efficiency of robots in unstructured environments. More information and code are available here: https://github.com/wu467/LangGrasp.
SLAM in the Dark: Self-Supervised Learning of Pose, Depth and Loop-Closure from Thermal Images
Feb 26, 2025



Visual SLAM is essential for mobile robots, drone navigation, and VR/AR, but traditional RGB camera systems struggle in low-light conditions, driving interest in thermal SLAM, which excels in such environments. However, thermal imaging faces challenges like low contrast, high noise, and limited large-scale annotated datasets, restricting the use of deep learning in outdoor scenarios. We present DarkSLAM, a noval deep learning-based monocular thermal SLAM system designed for large-scale localization and reconstruction in complex lighting conditions.Our approach incorporates the Efficient Channel Attention (ECA) mechanism in visual odometry and the Selective Kernel Attention (SKA) mechanism in depth estimation to enhance pose accuracy and mitigate thermal depth degradation. Additionally, the system includes thermal depth-based loop closure detection and pose optimization, ensuring robust performance in low-texture thermal scenes. Extensive outdoor experiments demonstrate that DarkSLAM significantly outperforms existing methods like SC-Sfm-Learner and Shin et al., delivering precise localization and 3D dense mapping even in challenging nighttime environments.
WebGames: Challenging General-Purpose Web-Browsing AI Agents
Feb 25, 2025


We introduce WebGames, a comprehensive benchmark suite designed to evaluate general-purpose web-browsing AI agents through a collection of 50+ interactive challenges. These challenges are specifically crafted to be straightforward for humans while systematically testing the limitations of current AI systems across fundamental browser interactions, advanced input processing, cognitive tasks, workflow automation, and interactive entertainment. Our framework eliminates external dependencies through a hermetic testing environment, ensuring reproducible evaluation with verifiable ground-truth solutions. We evaluate leading vision-language models including GPT-4o, Claude Computer-Use, Gemini-1.5-Pro, and Qwen2-VL against human performance. Results reveal a substantial capability gap, with the best AI system achieving only 43.1% success rate compared to human performance of 95.7%, highlighting fundamental limitations in current AI systems' ability to handle common web interaction patterns that humans find intuitive. The benchmark is publicly available at webgames.convergence.ai, offering a lightweight, client-side implementation that facilitates rapid evaluation cycles. Through its modular architecture and standardized challenge specifications, WebGames provides a robust foundation for measuring progress in development of more capable web-browsing agents.
LM2: Large Memory Models
Feb 09, 2025This paper introduces the Large Memory Model (LM2), a decoder-only Transformer architecture enhanced with an auxiliary memory module that aims to address the limitations of standard Transformers in multi-step reasoning, relational argumentation, and synthesizing information distributed over long contexts. The proposed LM2 incorporates a memory module that acts as a contextual representation repository, interacting with input tokens via cross attention and updating through gating mechanisms. To preserve the Transformers general-purpose capabilities, LM2 maintains the original information flow while integrating a complementary memory pathway. Experimental results on the BABILong benchmark demonstrate that the LM2model outperforms both the memory-augmented RMT model by 37.1% and the baseline Llama-3.2 model by 86.3% on average across tasks. LM2 exhibits exceptional capabilities in multi-hop inference, numerical reasoning, and large-context question-answering. On the MMLU dataset, it achieves a 5.0% improvement over a pre-trained vanilla model, demonstrating that its memory module does not degrade performance on general tasks. Further, in our analysis, we explore the memory interpretability, effectiveness of memory modules, and test-time behavior. Our findings emphasize the importance of explicit memory in enhancing Transformer architectures.
SP-VIO: Robust and Efficient Filter-Based Visual Inertial Odometry with State Transformation Model and Pose-Only Visual Description
Nov 12, 2024



Due to the advantages of high computational efficiency and small memory requirements, filter-based visual inertial odometry (VIO) has a good application prospect in miniaturized and payload-constrained embedded systems. However, the filter-based method has the problem of insufficient accuracy. To this end, we propose the State transformation and Pose-only VIO (SP-VIO) by rebuilding the state and measurement models, and considering further visual deprived conditions. In detail, we first proposed a system model based on the double state transformation extended Kalman filter (DST-EKF), which has been proven to have better observability and consistency than the models based on extended Kalman filter (EKF) and state transformation extended Kalman filter (ST-EKF). Secondly, to reduce the influence of linearization error caused by inaccurate 3D reconstruction, we adopt the Pose-only (PO) theory to decouple the measurement model from 3D features. Moreover, to deal with visual deprived conditions, we propose a double state transformation Rauch-Tung-Striebel (DST-RTS) backtracking method to optimize motion trajectories during visual interruption. Experiments on public (EuRoC, Tum-VI, KITTI) and personal datasets show that SP-VIO has better accuracy and efficiency than state-of-the-art (SOTA) VIO algorithms, and has better robustness under visual deprived conditions.
Metric-aligned Sample Selection and Critical Feature Sampling for Oriented Object Detection
Jul 10, 2023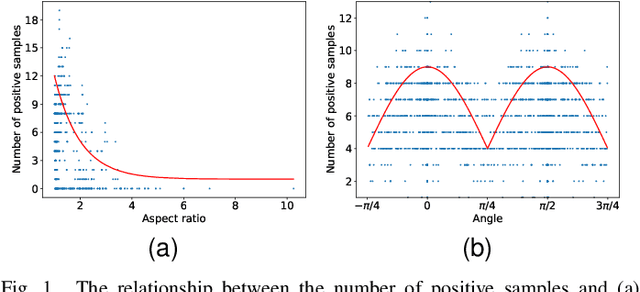

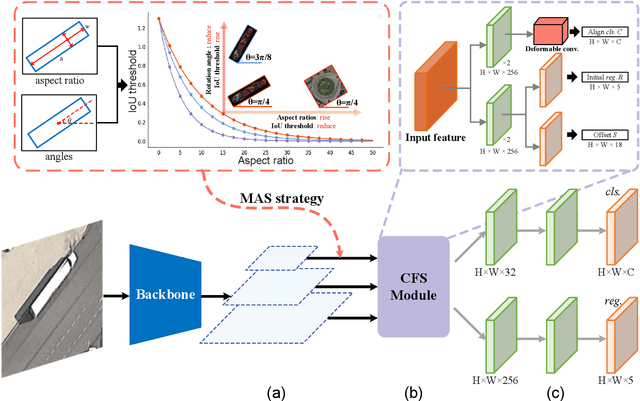
Arbitrary-oriented object detection is a relatively emerging but challenging task. Although remarkable progress has been made, there still remain many unsolved issues due to the large diversity of patterns in orientation, scale, aspect ratio, and visual appearance of objects in aerial images. Most of the existing methods adopt a coarse-grained fixed label assignment strategy and suffer from the inconsistency between the classification score and localization accuracy. First, to align the metric inconsistency between sample selection and regression loss calculation caused by fixed IoU strategy, we introduce affine transformation to evaluate the quality of samples and propose a distance-based label assignment strategy. The proposed metric-aligned selection (MAS) strategy can dynamically select samples according to the shape and rotation characteristic of objects. Second, to further address the inconsistency between classification and localization, we propose a critical feature sampling (CFS) module, which performs localization refinement on the sampling location for classification task to extract critical features accurately. Third, we present a scale-controlled smooth $L_1$ loss (SC-Loss) to adaptively select high quality samples by changing the form of regression loss function based on the statistics of proposals during training. Extensive experiments are conducted on four challenging rotated object detection datasets DOTA, FAIR1M-1.0, HRSC2016, and UCAS-AOD. The results show the state-of-the-art accuracy of the proposed detector.
Identity-Enhanced Network for Facial Expression Recognition
Dec 11, 2018
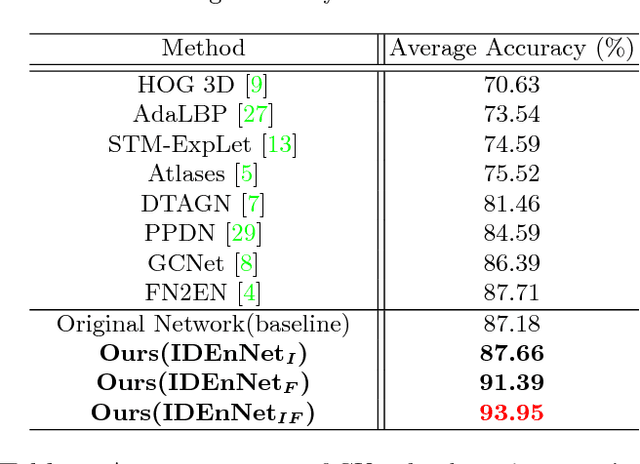
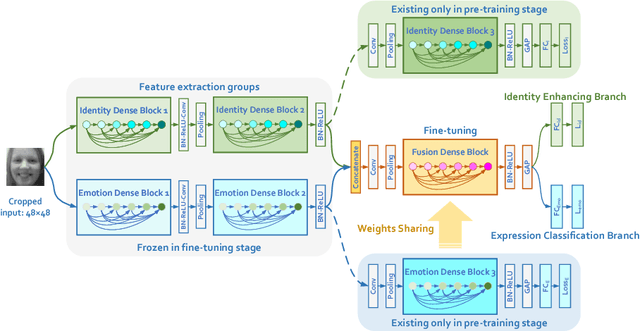

Facial expression recognition is a challenging task, arguably because of large intra-class variations and high inter-class similarities. The core drawback of the existing approaches is the lack of ability to discriminate the changes in appearance caused by emotions and identities. In this paper, we present a novel identity-enhanced network (IDEnNet) to eliminate the negative impact of identity factor and focus on recognizing facial expressions. Spatial fusion combined with self-constrained multi-task learning are adopted to jointly learn the expression representations and identity-related information. We evaluate our approach on three popular datasets, namely Oulu-CASIA, CK+ and MMI. IDEnNet improves the baseline consistently, and achieves the best or comparable state-of-the-art on all three datasets.