 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA-VGGT:Adapting VGGT to Large Scale Localization by Self-Supervised Learning with Geometry and Physics Aware Loss
Jan 26, 2026Transformer-based general visual geometry frameworks have shown promising performance in camera pose estimation and 3D scene understanding. Recent advancements in Visual Geometry Grounded Transformer (VGGT) models have shown great promise in camera pose estimation and 3D reconstruction. However, these models typically rely on ground truth labels for training, posing challenges when adapting to unlabeled and unseen scenes. In this paper, we propose a self-supervised framework to train VGGT with unlabeled data, thereby enhancing its localization capability in large-scale environments. To achieve this, we extend conventional pair-wise relations to sequence-wise geometric constraints for self-supervised learning. Specifically, in each sequence, we sample multiple source frames and geometrically project them onto different target frames, which improves temporal feature consistency. We formulate physical photometric consistency and geometric constraints as a joint optimization loss to circumvent the requirement for hard labels. By training the model with this proposed method, not only the local and global cross-view attention layers but also the camera and depth heads can effectively capture the underlying multi-view geometry. Experiments demonstrate that the model converges within hundreds of iterations and achieves significant improvements in large-scale localization. Our code will be released at https://github.com/X-yangfan/GPA-VGGT.
An Information-Theoretic Framework for Robust Large Language Model Editing
Dec 18, 2025



Large Language Models (LLMs) have become indispensable tools in science, technology, and society, enabling transformative advances across diverse fields. However, errors or outdated information within these models can undermine their accuracy and restrict their safe deployment. Developing efficient strategies for updating model knowledge without the expense and disruption of full retraining remains a critical challenge. Current model editing techniques frequently struggle to generalize corrections beyond narrow domains, leading to unintended consequences and limiting their practical impact. Here, we introduce a novel framework for editing LLMs, grounded in information bottleneck theory. This approach precisely compresses and isolates the essential information required for generalizable knowledge correction while minimizing disruption to unrelated model behaviors. Building upon this foundation, we present the Information Bottleneck Knowledge Editor (IBKE), which leverages compact latent representations to guide gradient-based updates, enabling robust and broadly applicable model editing. We validate IBKE's effectiveness across multiple LLM architectures and standard benchmark tasks, demonstrating state-of-the-art accuracy and improved generality and specificity of edits. These findings establish a theoretically principled and practical paradigm for open-domain knowledge editing, advancing the utility and trustworthiness of LLMs in real-world applications.
UniEdit: A Unified Knowledge Editing Benchmark for Large Language Models
May 18, 2025Model editing aims to enhance the accuracy and reliability of large language models (LLMs) by efficiently adjusting their internal parameters. Currently, most LLM editing datasets are confined to narrow knowledge domains and cover a limited range of editing evaluation. They often overlook the broad scope of editing demands and the diversity of ripple effects resulting from edits. In this context, we introduce UniEdit, a unified benchmark for LLM editing grounded in open-domain knowledge. First, we construct editing samples by selecting entities from 25 common domains across five major categories, utilizing the extensive triple knowledge available in open-domain knowledge graphs to ensure comprehensive coverage of the knowledge domains. To address the issues of generality and locality in editing, we design an Neighborhood Multi-hop Chain Sampling (NMCS) algorithm to sample subgraphs based on a given knowledge piece to entail comprehensive ripple effects to evaluate. Finally, we employ proprietary LLMs to convert the sampled knowledge subgraphs into natural language text, guaranteeing grammatical accuracy and syntactical diversity. Extensive statistical analysis confirms the scale, comprehensiveness, and diversity of our UniEdit benchmark. We conduct comprehensive experiments across multiple LLMs and editors, analyzing their performance to highlight strengths and weaknesses in editing across open knowledge domains and various evaluation criteria, thereby offering valuable insights for future research endeavors.
BELLE: A Bi-Level Multi-Agent Reasoning Framework for Multi-Hop Question Answering
May 17, 2025Multi-hop question answering (QA) involves finding multiple relevant passages and performing step-by-step reasoning to answer complex questions. Previous works on multi-hop QA employ specific methods from different modeling perspectives based on large language models (LLMs), regardless of the question types. In this paper, we first conduct an in-depth analysis of public multi-hop QA benchmarks, dividing the questions into four types and evaluating five types of cutting-edge methods for multi-hop QA: Chain-of-Thought (CoT), Single-step, Iterative-step, Sub-step, and Adaptive-step. We find that different types of multi-hop questions have varying degrees of sensitivity to different types of methods. Thus, we propose a Bi-levEL muLti-agEnt reasoning (BELLE) framework to address multi-hop QA by specifically focusing on the correspondence between question types and methods, where each type of method is regarded as an ''operator'' by prompting LLMs differently. The first level of BELLE includes multiple agents that debate to obtain an executive plan of combined ''operators'' to address the multi-hop QA task comprehensively. During the debate, in addition to the basic roles of affirmative debater, negative debater, and judge, at the second level, we further leverage fast and slow debaters to monitor whether changes in viewpoints are reasonable. Extensive experiments demonstrate that BELLE significantly outperforms strong baselines in various datasets. Additionally, the model consumption of BELLE is higher cost-effectiveness than that of single models in more complex multi-hop QA scenarios.
VGC-RIO: A Tightly Integrated Radar-Inertial Odometry with Spatial Weighted Doppler Velocity and Local Geometric Constrained RCS Histograms
May 15, 2025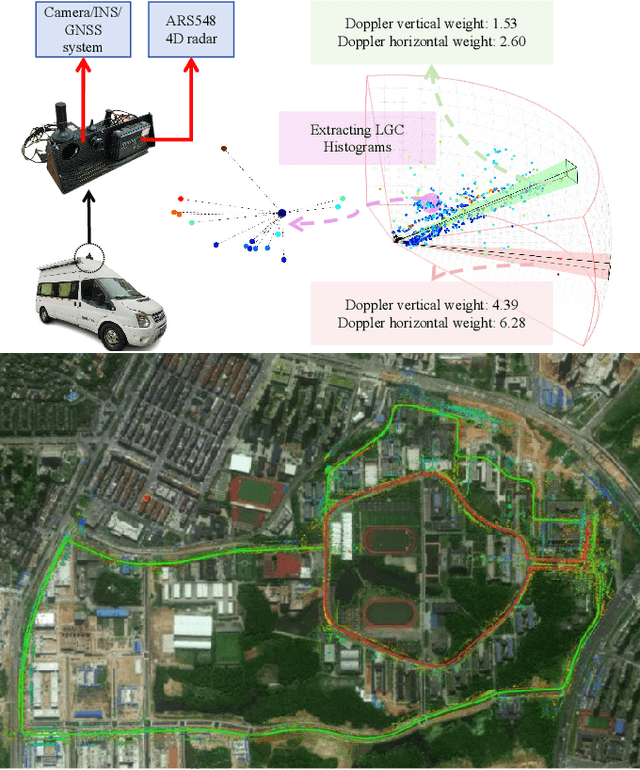
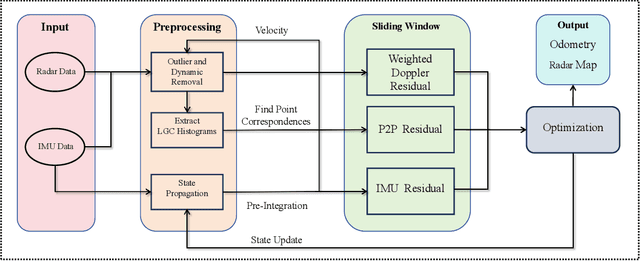
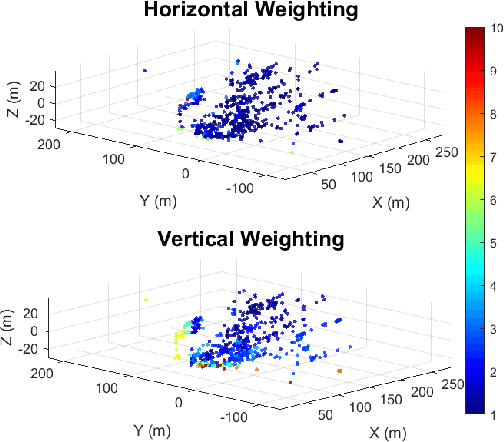
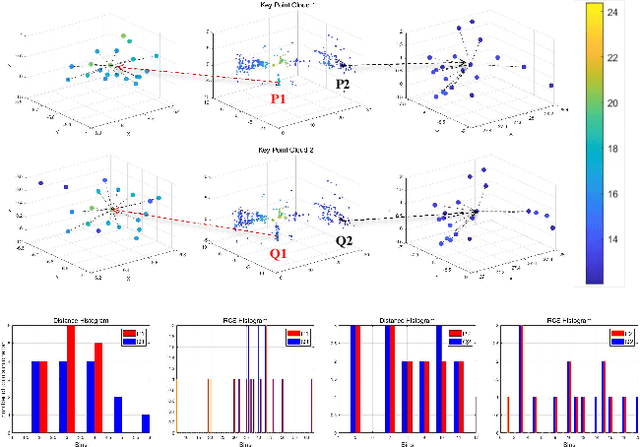
Recent advances in 4D radar-inertial odometry have demonstrated promising potential for autonomous lo calization in adverse conditions. However, effective handling of sparse and noisy radar measurements remains a critical challenge. In this paper, we propose a radar-inertial odometry with a spatial weighting method that adapts to unevenly distributed points and a novel point-description histogram for challenging point registration. To make full use of the Doppler velocity from different spatial sections, we propose a weighting calculation model. To enhance the point cloud registration performance under challenging scenarios, we con struct a novel point histogram descriptor that combines local geometric features and radar cross-section (RCS) features. We have also conducted extensive experiments on both public and self-constructed datasets. The results demonstrate the precision and robustness of the proposed VGC-RIO.
SLAM in the Dark: Self-Supervised Learning of Pose, Depth and Loop-Closure from Thermal Images
Feb 26, 2025



Visual SLAM is essential for mobile robots, drone navigation, and VR/AR, but traditional RGB camera systems struggle in low-light conditions, driving interest in thermal SLAM, which excels in such environments. However, thermal imaging faces challenges like low contrast, high noise, and limited large-scale annotated datasets, restricting the use of deep learning in outdoor scenarios. We present DarkSLAM, a noval deep learning-based monocular thermal SLAM system designed for large-scale localization and reconstruction in complex lighting conditions.Our approach incorporates the Efficient Channel Attention (ECA) mechanism in visual odometry and the Selective Kernel Attention (SKA) mechanism in depth estimation to enhance pose accuracy and mitigate thermal depth degradation. Additionally, the system includes thermal depth-based loop closure detection and pose optimization, ensuring robust performance in low-texture thermal scenes. Extensive outdoor experiments demonstrate that DarkSLAM significantly outperforms existing methods like SC-Sfm-Learner and Shin et al., delivering precise localization and 3D dense mapping even in challenging nighttime environments.
Concept Based Continuous Prompts for Interpretable Text Classification
Dec 02, 2024

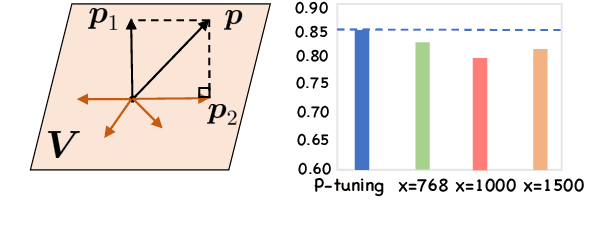
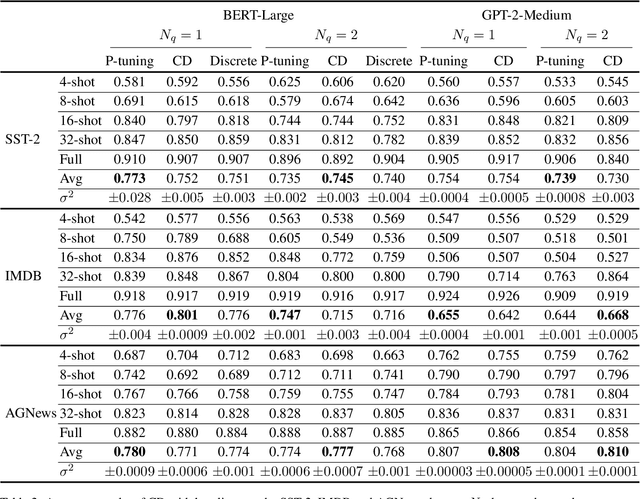
Continuous prompts have become widely adopted for augmenting performance across a wide range of natural language tasks. However, the underlying mechanism of this enhancement remains obscure. Previous studies rely on individual words for interpreting continuous prompts, which lacks comprehensive semantic understanding. Drawing inspiration from Concept Bottleneck Models, we propose a framework for interpreting continuous prompts by decomposing them into human-readable concepts. Specifically, to ensure the feasibility of the decomposition, we demonstrate that a corresponding concept embedding matrix and a coefficient matrix can always be found to replace the prompt embedding matrix. Then, we employ GPT-4o to generate a concept pool and choose potential candidate concepts that are discriminative and representative using a novel submodular optimization algorithm. Experiments demonstrate that our framework can achieve similar results as the original P-tuning and word-based approaches using only a few concepts while providing more plausible results. Our code is available at https://github.com/qq31415926/CD.
Lifelong Knowledge Editing for Vision Language Models with Low-Rank Mixture-of-Experts
Nov 23, 2024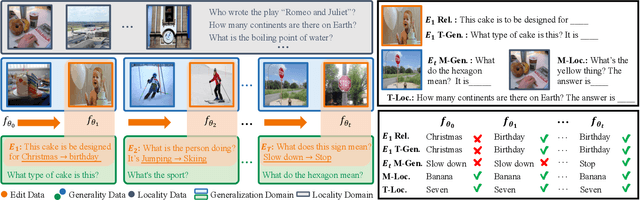
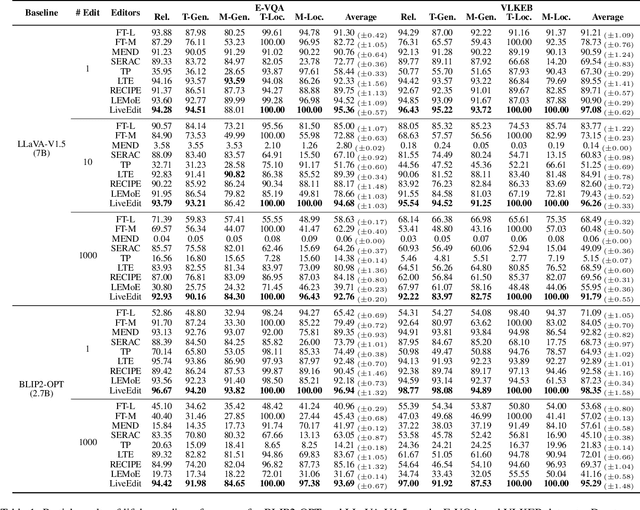
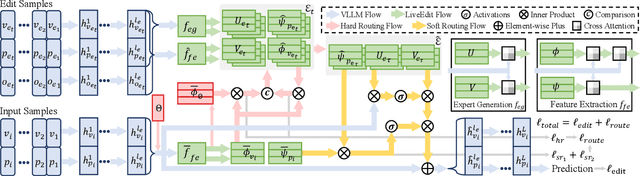
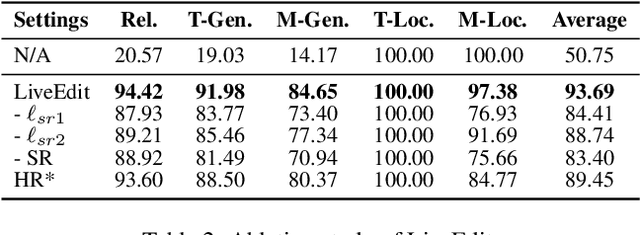
Model editing aims to correct inaccurate knowledge, update outdated information, and incorporate new data into Large Language Models (LLMs) without the need for retraining. This task poses challenges in lifelong scenarios where edits must be continuously applied for real-world applications. While some editors demonstrate strong robustness for lifelong editing in pure LLMs, Vision LLMs (VLLMs), which incorporate an additional vision modality, are not directly adaptable to existing LLM editors. In this paper, we propose LiveEdit, a LIfelong Vision language modEl Edit to bridge the gap between lifelong LLM editing and VLLMs. We begin by training an editing expert generator to independently produce low-rank experts for each editing instance, with the goal of correcting the relevant responses of the VLLM. A hard filtering mechanism is developed to utilize visual semantic knowledge, thereby coarsely eliminating visually irrelevant experts for input queries during the inference stage of the post-edited model. Finally, to integrate visually relevant experts, we introduce a soft routing mechanism based on textual semantic relevance to achieve multi-expert fusion. For evaluation, we establish a benchmark for lifelong VLLM editing. Extensive experiments demonstrate that LiveEdit offers significant advantages in lifelong VLLM editing scenarios. Further experiments validate the rationality and effectiveness of each module design in LiveEdit.
Attribution Analysis Meets Model Editing: Advancing Knowledge Correction in Vision Language Models with VisEdit
Aug 19, 2024



Model editing aims to correct outdated or erroneous knowledge in large models without costly retraining. Recent research discovered that the mid-layer representation of the subject's final token in a prompt has a strong influence on factual predictions, and developed Large Language Model (LLM) editing techniques based on this observation. However, for Vision-LLMs (VLLMs), how visual representations impact the predictions from a decoder-only language model remains largely unexplored. To the best of our knowledge, model editing for VLLMs has not been extensively studied in the literature. In this work, we employ the contribution allocation and noise perturbation methods to measure the contributions of visual representations for token predictions. Our attribution analysis shows that visual representations in mid-to-later layers that are highly relevant to the prompt contribute significantly to predictions. Based on these insights, we propose VisEdit, a novel model editor for VLLMs that effectively corrects knowledge by editing intermediate visual representations in regions important to the edit prompt. We evaluated VisEdit using multiple VLLM backbones and public VLLM editing benchmark datasets. The results show the superiority of VisEdit over the strong baselines adapted from existing state-of-the-art editors for LLMs.
KEHRL: Learning Knowledge-Enhanced Language Representations with Hierarchical Reinforcement Learning
Jun 24, 2024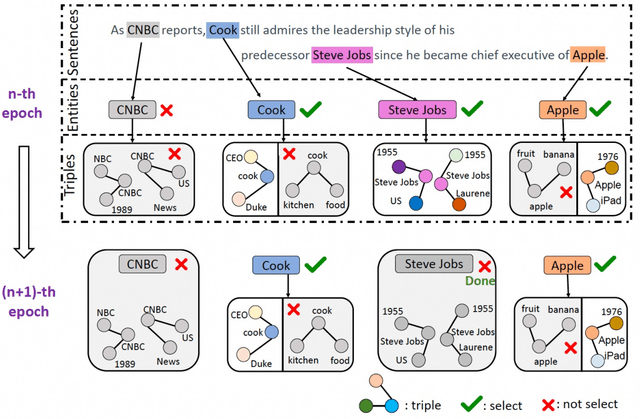
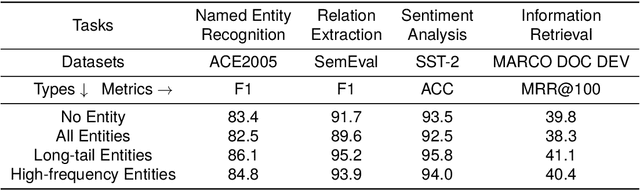
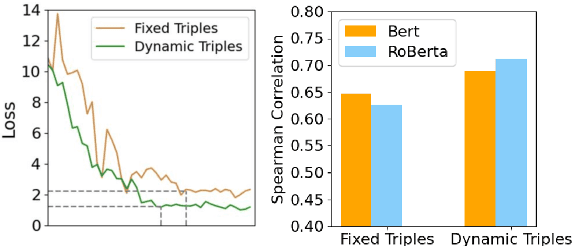

Knowledge-enhanced pre-trained language models (KEPLMs) leverage relation triples from knowledge graphs (KGs) and integrate these external data sources into language models via self-supervised learning. Previous works treat knowledge enhancement as two independent operations, i.e., knowledge injection and knowledge integration. In this paper, we propose to learn Knowledge-Enhanced language representations with Hierarchical Reinforcement Learning (KEHRL), which jointly addresses the problems of detecting positions for knowledge injection and integrating external knowledge into the model in order to avoid injecting inaccurate or irrelevant knowledge. Specifically, a high-level reinforcement learning (RL) agent utilizes both internal and prior knowledge to iteratively detect essential positions in texts for knowledge injection, which filters out less meaningful entities to avoid diverting the knowledge learning direction. Once the entity positions are selected, a relevant triple filtration module is triggered to perform low-level RL to dynamically refine the triples associated with polysemic entities through binary-valued actions. Experiments validate KEHRL's effectiveness in probing factual knowledge and enhancing the model's performance on various natural language understanding tasks.