 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Steering Works: Toward a Unified View of Language Model Parameter Dynamics
Feb 02, 2026Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.
YuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
Disrupting Hierarchical Reasoning: Adversarial Protection for Geographic Privacy in Multimodal Reasoning Models
Dec 09, 2025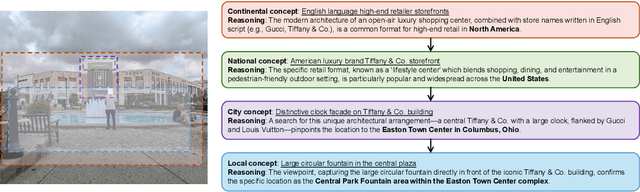
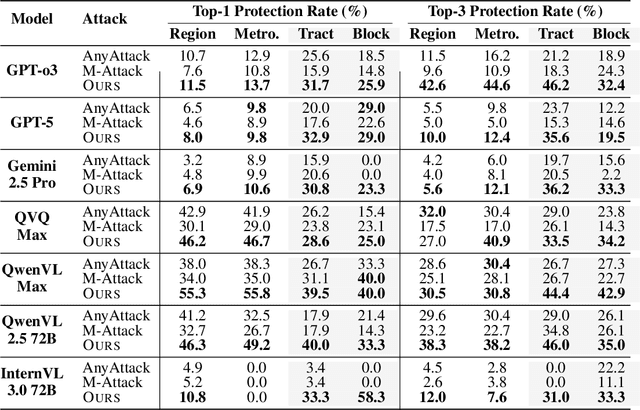
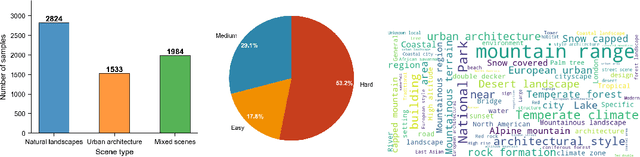
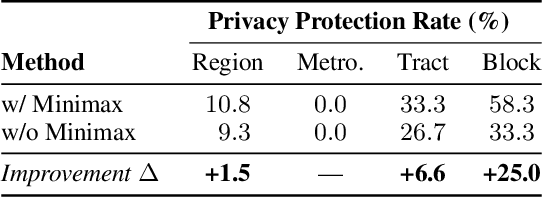
Multi-modal large reasoning models (MLRMs) pose significant privacy risks by inferring precise geographic locations from personal images through hierarchical chain-of-thought reasoning. Existing privacy protection techniques, primarily designed for perception-based models, prove ineffective against MLRMs' sophisticated multi-step reasoning processes that analyze environmental cues. We introduce \textbf{ReasonBreak}, a novel adversarial framework specifically designed to disrupt hierarchical reasoning in MLRMs through concept-aware perturbations. Our approach is founded on the key insight that effective disruption of geographic reasoning requires perturbations aligned with conceptual hierarchies rather than uniform noise. ReasonBreak strategically targets critical conceptual dependencies within reasoning chains, generating perturbations that invalidate specific inference steps and cascade through subsequent reasoning stages. To facilitate this approach, we contribute \textbf{GeoPrivacy-6K}, a comprehensive dataset comprising 6,341 ultra-high-resolution images ($\geq$2K) with hierarchical concept annotations. Extensive evaluation across seven state-of-the-art MLRMs (including GPT-o3, GPT-5, Gemini 2.5 Pro) demonstrates ReasonBreak's superior effectiveness, achieving a 14.4\% improvement in tract-level protection (33.8\% vs 19.4\%) and nearly doubling block-level protection (33.5\% vs 16.8\%). This work establishes a new paradigm for privacy protection against reasoning-based threats.
Oblivionis: A Lightweight Learning and Unlearning Framework for Federated Large Language Models
Aug 12, 2025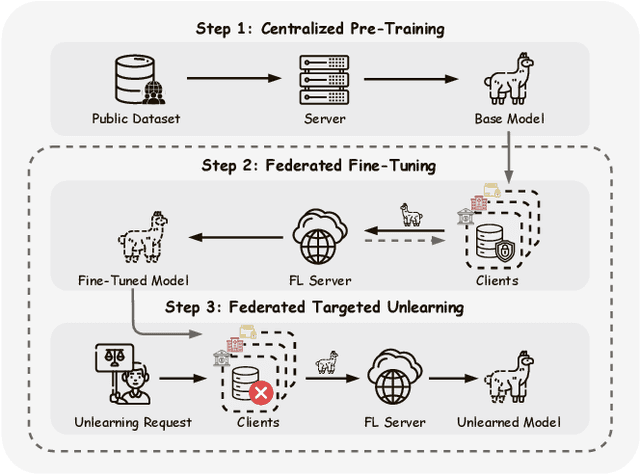
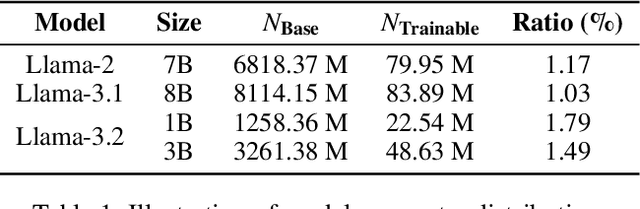
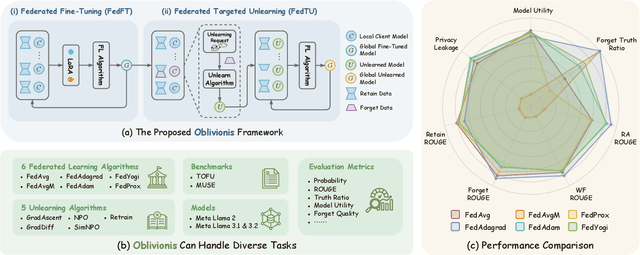
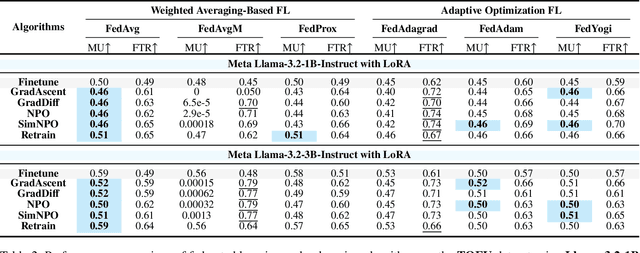
Large Language Models (LLMs) increasingly leverage Federated Learning (FL) to utilize private, task-specific datasets for fine-tuning while preserving data privacy. However, while federated LLM frameworks effectively enable collaborative training without raw data sharing, they critically lack built-in mechanisms for regulatory compliance like GDPR's right to be forgotten. Integrating private data heightens concerns over data quality and long-term governance, yet existing distributed training frameworks offer no principled way to selectively remove specific client contributions post-training. Due to distributed data silos, stringent privacy constraints, and the intricacies of interdependent model aggregation, federated LLM unlearning is significantly more complex than centralized LLM unlearning. To address this gap, we introduce Oblivionis, a lightweight learning and unlearning framework that enables clients to selectively remove specific private data during federated LLM training, enhancing trustworthiness and regulatory compliance. By unifying FL and unlearning as a dual optimization objective, we incorporate 6 FL and 5 unlearning algorithms for comprehensive evaluation and comparative analysis, establishing a robust pipeline for federated LLM unlearning. Extensive experiments demonstrate that Oblivionis outperforms local training, achieving a robust balance between forgetting efficacy and model utility, with cross-algorithm comparisons providing clear directions for future LLM development.
Generative Video Matting
Aug 11, 2025Video matting has traditionally been limited by the lack of high-quality ground-truth data. Most existing video matting datasets provide only human-annotated imperfect alpha and foreground annotations, which must be composited to background images or videos during the training stage. Thus, the generalization capability of previous methods in real-world scenarios is typically poor. In this work, we propose to solve the problem from two perspectives. First, we emphasize the importance of large-scale pre-training by pursuing diverse synthetic and pseudo-labeled segmentation datasets. We also develop a scalable synthetic data generation pipeline that can render diverse human bodies and fine-grained hairs, yielding around 200 video clips with a 3-second duration for fine-tuning. Second, we introduce a novel video matting approach that can effectively leverage the rich priors from pre-trained video diffusion models. This architecture offers two key advantages. First, strong priors play a critical role in bridging the domain gap between synthetic and real-world scenes. Second, unlike most existing methods that process video matting frame-by-frame and use an independent decoder to aggregate temporal information, our model is inherently designed for video, ensuring strong temporal consistency. We provide a comprehensive quantitative evaluation across three benchmark datasets, demonstrating our approach's superior performance, and present comprehensive qualitative results in diverse real-world scenes, illustrating the strong generalization capability of our method. The code is available at https://github.com/aim-uofa/GVM.
Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning
Jun 13, 2025Continual multimodal instruction tuning is crucial for adapting Multimodal Large Language Models (MLLMs) to evolving tasks. However, most existing methods adopt a fixed architecture, struggling with adapting to new tasks due to static model capacity. We propose to evolve the architecture under parameter budgets for dynamic task adaptation, which remains unexplored and imposes two challenges: 1) task architecture conflict, where different tasks require varying layer-wise adaptations, and 2) modality imbalance, where different tasks rely unevenly on modalities, leading to unbalanced updates. To address these challenges, we propose a novel Dynamic Mixture of Curriculum LoRA Experts (D-MoLE) method, which automatically evolves MLLM's architecture with controlled parameter budgets to continually adapt to new tasks while retaining previously learned knowledge. Specifically, we propose a dynamic layer-wise expert allocator, which automatically allocates LoRA experts across layers to resolve architecture conflicts, and routes instructions layer-wisely to facilitate knowledge sharing among experts. Then, we propose a gradient-based inter-modal continual curriculum, which adjusts the update ratio of each module in MLLM based on the difficulty of each modality within the task to alleviate the modality imbalance problem. Extensive experiments show that D-MoLE significantly outperforms state-of-the-art baselines, achieving a 15% average improvement over the best baseline. To the best of our knowledge, this is the first study of continual learning for MLLMs from an architectural perspective.
Score-based Generative Modeling for Conditional Independence Testing
May 29, 2025Determining conditional independence (CI) relationships between random variables is a fundamental yet challenging task in machine learning and statistics, especially in high-dimensional settings. Existing generative model-based CI testing methods, such as those utilizing generative adversarial networks (GANs), often struggle with undesirable modeling of conditional distributions and training instability, resulting in subpar performance. To address these issues, we propose a novel CI testing method via score-based generative modeling, which achieves precise Type I error control and strong testing power. Concretely, we first employ a sliced conditional score matching scheme to accurately estimate conditional score and use Langevin dynamics conditional sampling to generate null hypothesis samples, ensuring precise Type I error control. Then, we incorporate a goodness-of-fit stage into the method to verify generated samples and enhance interpretability in practice. We theoretically establish the error bound of conditional distributions modeled by score-based generative models and prove the validity of our CI tests. Extensive experiments on both synthetic and real-world datasets show that our method significantly outperforms existing state-of-the-art methods, providing a promising way to revitalize generative model-based CI testing.
AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
Apr 04, 2025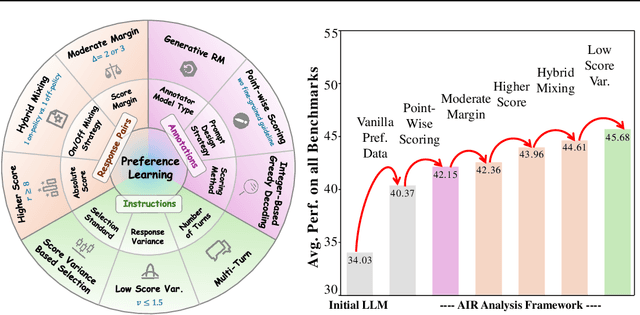
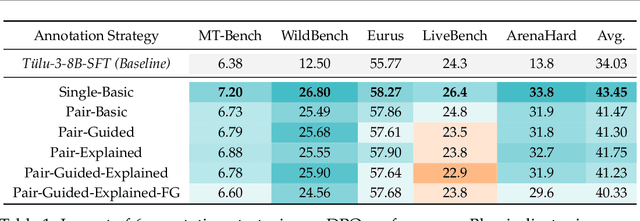
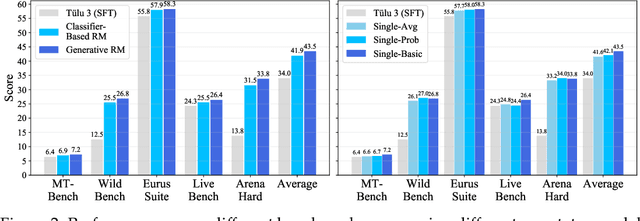

Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference \textbf{A}nnotations, \textbf{I}nstructions, and \textbf{R}esponse Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose \textbf{AIR}, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.
Correlation-Aware Graph Convolutional Networks for Multi-Label Node Classification
Nov 26, 2024



Multi-label node classification is an important yet under-explored domain in graph mining as many real-world nodes belong to multiple categories rather than just a single one. Although a few efforts have been made by utilizing Graph Convolution Networks (GCNs) to learn node representations and model correlations between multiple labels in the embedding space, they still suffer from the ambiguous feature and ambiguous topology induced by multiple labels, which reduces the credibility of the messages delivered in graphs and overlooks the label correlations on graph data. Therefore, it is crucial to reduce the ambiguity and empower the GCNs for accurate classification. However, this is quite challenging due to the requirement of retaining the distinctiveness of each label while fully harnessing the correlation between labels simultaneously. To address these issues, in this paper, we propose a Correlation-aware Graph Convolutional Network (CorGCN) for multi-label node classification. By introducing a novel Correlation-Aware Graph Decomposition module, CorGCN can learn a graph that contains rich label-correlated information for each label. It then employs a Correlation-Enhanced Graph Convolution to model the relationships between labels during message passing to further bolster the classification process. Extensive experiments on five datasets demonstrate the effectiveness of our proposed CorGCN.
Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper
Aug 20, 2024



Pre-trained multilingual speech foundation models, like Whisper, have shown impressive performance across different languages. However, adapting these models to new or specific languages is computationally extensive and faces catastrophic forgetting problems. Addressing these issues, our study investigates strategies to enhance the model on new languages in the absence of original training data, while also preserving the established performance on the original languages. Specifically, we first compare various LoRA-based methods to find out their vulnerability to forgetting. To mitigate this issue, we propose to leverage the LoRA parameters from the original model for approximate orthogonal gradient descent on the new samples. Additionally, we also introduce a learnable rank coefficient to allocate trainable parameters for more efficient training. Our experiments with a Chinese Whisper model (for Uyghur and Tibetan) yield better results with a more compact parameter set.